COVID-19 en Brasil: Cómo creamos un mapa interactivo que ubica a los lectores en el epicentro de la epidemia
Leer este artículo en

Mis herramientas favoritas: Lisseth Boon, diseño y visualización de datos

Guía práctica para periodistas: colaboración con organizaciones de la sociedad civil y organizaciones no gubernamentales

Guía para reportajes sobre la rendición de cuentas de la IA

Guía de GIJN para investigar emisiones de metano en vertederos y sus soluciones

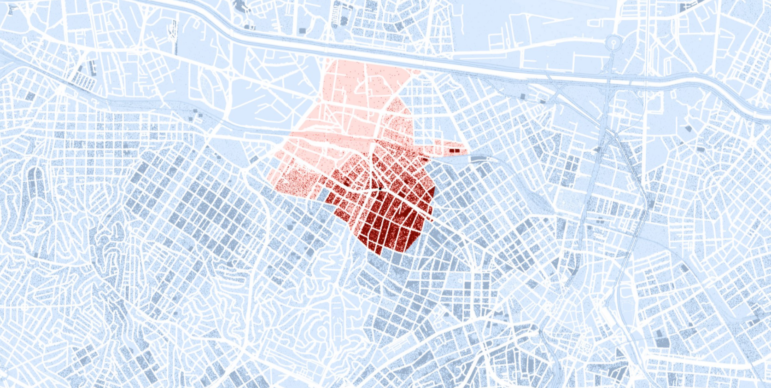
Image: La visualización de datos creada por el equipo. Captura de pantalla.
Nota del editor: Cuando la pandemia del COVID-19 golpeó por primera vez a Brasil, un equipo de periodistas de datos se propuso ilustrar el número de muertos en el país para que las cifras crecientes significaran algo tangible para los lectores. El resultado fue la visualización de datos en el epicentro. A medida que la crisis continúa profundizándose, el equipo ha actualizado continuamente el proyecto con los últimos datos disponibles. A continuación, un vistazo entre bastidores sobre cómo se creó el proyecto.
Si todos los muertos por COVID-19 en Brasil fueran tus vecinos, tu vecindario ya no aparecería en el mapa. Probablemente tu ciudad entera desaparecería.
Este escenario hipotético debería ayudarte a comprender la escala de la crisis sanitaria en Brasil, pero imaginar tu vecindario desolado no es fácil.
Sin embargo, una colaboración entre Google News Initiative y Agencia Lupa logró convertir esta idea en realidad. Usando la geolocalización y los mapas del censo de 2010, la visualización interactiva de datos que hicimos crea una especie de radio de devastación, convirtiendo el hogar de cada lector en el epicentro de la epidemia en Brasil.
Además de los tres periodistas que han escrito esta historia, el proyecto contó con cuatro editores y directores creativos más: Alberto Cairo y Marco Túlio Pires, de Google, y Natália Leal y Gilberto Scofield Jr., de Lupa.
Su trabajo se debió a la convicción de que ubicar al público en el ojo del huracán pandémico, incluso hipotéticamente, haría posible mostrar la escala de la tragedia de forma más clara.
Pero ¿por qué pensamos eso y por qué logramos que funcionara? Aquí explicaremos, detalladamente, cómo pusimos en marcha esa idea.
El comienzo: una tragedia invisible
Cuando comenzamos a trabajar en junio de 2020, 58 390 brasileños habían muerto a causa del coronavirus.
A pesar de la naturaleza irrefutable de estas cifras, la experiencia que ha tenido con la enfermedad cada uno de nosotros como periodistas, diseñadores y desarrolladores viviendo en distintas partes de Brasil, hasta ahora, había sido muy diferente.
Los que viven en San Pablo, la ciudad con más casos de Brasil, aguantaron una cuarentena estricta que duró desde finales de marzo hasta mediados de junio.
Los que viven en el Distrito Federal, donde está la capital brasileña, vieron cómo la pandemia afectó a la esfera política y cómo el virus se propagó con mayor rapidez aquí que en cualquier otro estado.
Por último, están los que viven en una comunidad más aislada en la zona rural de Paraná, donde incluso después de cuatro meses de COVID-19 en Brasil, solo se había registrado una muerte.
Para los que residían en los primeros dos lugares, la experiencia de vivir en el país que se ha convertido en el epicentro mundial de la pandemia más grande del siglo fue más asombrosa e intensa que para los que residían en el otro, que experimentaron los momentos más dramáticos de la crisis muy lejos de su propio vecindario.
De alguna manera, el aislamiento social causado por los confinamientos y ver las calles vacías había sido más palpable o comprensible para las personas, que la enorme cantidad de vidas perdidas. Incluso los que viven en medio de la crisis la han sufrido desde dentro de sus casas, a través de sus televisores o de Internet.
Sin embargo, decenas de miles de brasileños ya han muerto y miles más mueren cada semana. También están los enfermos en hospitales en todo el país, que son invisibles para nosotros.
Este proyecto comenzó con nosotros preguntándonos: ¿cómo podemos hacer que la gente vea realmente a estas víctimas? ¿Cómo podemos hacer que el costo humano de esta enfermedad sea más visible o relevante para las personas que lo ven como horas de aburrimiento, tiendas cerradas y aceras vacías?
Referencias conocidas
60 000 personas fallecidas [al momento en que se realizó el proyecto. Para marzo de 2021, la cifra alcanzó 280 000]. En comparación, es como si el Estadio de Arruda, en Recife, desapareciera repentinamente lleno de personas, o como si dos sambódromos de Anhembi, en San Pablo, se hubiesen esfumado. Es impactante, ¿verdad?
Sin duda lo es, para quienes conocen los lugares mencionados. Si vives en el estado capital de Pernambuco, sabes que el Estadio de Arruda es enorme, pero ¿y si nunca has estado cerca?
Para quienes viven en la ciudad de Ponta Grossa, en el estado de Paraná, las referencias de tamaño son distintas. La idea del sambódromo de San Pablo no evoca nada. El estadio de fútbol de la ciudad, por ejemplo, no es el Arruda sino el Estadio Germano Krüger.
Establecer paralelismos con lugares como este tiene más sentido para los residentes de Ponta Grossa que cualquier otro supuesto parámetro universal.
La misma lógica aplica para quienes viven en San Pablo, Brasilia, o cualquier otro sitio: mientras más conocida sea la referencia, más fácil es comprender la escala de la pandemia. Y ¿existe algo más conocido que el lugar donde vivimos?
La idea fundamental de este proyecto era hacer que las víctimas del COVID-19 fueran, repentinamente, más cercanas al lector. Leyendo el gráfico, las 60 000 personas fallecidas no solo son personas que viven a miles de kilómetros, sino que se convierten en vecinos, en conocidos. Las referencias ya no son un estadio de fútbol en el otro extremo del país o un suceso histórico distante; son las calles en las que camina el lector todos los días. Así la pandemia se vuelve palpable.
Fue a partir de este concepto que planificamos la experiencia, desarrollamos métodos, recopilamos datos y, finalmente, creamos la historia del artículo. En este documento, te mostraremos cómo pusimos en marcha el plan.
Lluvia de ideas: elementos básicos
Los miembros del equipo se reunían semanalmente. En la primera reunión, acordamos que había dos elementos esenciales si queríamos lograr el concepto.
Lo más crucial era personalizar e individualizar la experiencia del lector, un punto que desde el principio enfatizó Alberto Cairo, quien tuvo la idea de llevar las muertes al vecindario del lector.
Al hacer sentir personalmente afectados a los lectores, podíamos quitar la sensación de distancia entre la vida de quienes aún no se habían visto directamente afectados por el virus, y la realidad de la creciente cantidad de fallecimientos.
A ello se suma, el lenguaje usado en la visualización de datos tendría que ser lo más directo posible, evitando la abstracción excesiva.
Una gráfica mostrando la evolución de la curva de la enfermedad es informativa, pero todavía esconde su propia inflexión. Las líneas son, realmente, solo una representación de un gran grupo de personas. Para evitar este distanciamiento, el lenguaje utilizado debe ser lo más tangible posible para enfatizar la naturaleza de los datos.
Con las políticas de nuestro concepto en cuenta, nos lanzamos a la parte práctica haciendo lo que hacen los que buscan creatividad: recopilar contenido que nos gustaría “imitar”, la originalidad no es más que usar de inspiración a la gente correcta.
Inspiración
Decidimos comenzar la búsqueda explorando metáforas visuales que reflejaran nuestra propuesta editorial.
Una de las primeras referencias que nos vino a la mente fue un proyecto publicado por The New York Times después de las elecciones presidenciales de 2016 en Estados Unidos.
En el proyecto, el mapa de Estados Unidos desaparece según los resultados de la votación. Es como si se pusieran dos países uno al lado del otro: uno está compuesto solo por los estados en los que ganó Donald Trump. En el otro, solo se pueden ver los dominios de Hillary Clinton.

Imagen: Mapa que elimina las áreas de Estados Unidos donde Hillary Clinton obtuvo más votos que Donald Trump. Captura de pantalla.

Imagen: Mapa que elimina las áreas de Estados Unidos donde Donald Trump obtuvo más votos que Hillary Clinton. Captura de pantalla.
La metáfora utilizada por The New York Times aquí es poderosa porque distorsiona objetos, en este caso un mapa, conocido para el lector, lo que causa incomodidad. Aparte de eso, la representación coincide con el concepto de nuestro propio reportaje: desvanecer, desaparecer, esfumarse.
Una referencia similar se encontró en Brasil en el proyecto “Aqui não mora ninguém” (“Aquí no vive nadie”), realizado por Plano C, una empresa de consultoría geoespacial.

Imagen: Las áreas naranja representan las regiones inhabitadas de Brasil. Captura de pantalla.
En la vista de arriba, las áreas del país donde no vive ni una sola persona se pintan de naranja. De nuevo, vemos la metáfora de vacío y ausencia, pero esta vez en el mismo espacio en el que trabajaremos: el territorio brasileño.
Sin embargo, los datos mostrados en ambos ejemplos omitían un aspecto importante: la densidad demográfica.
Tanto las áreas eliminadas en el mapa de The New York Times y los cuadrados naranjas en el mapa de Plan C muestran «valores booleanos» (la idea de que los valores eran verdaderos (Candidato A ganó aquí) o falsos (Candidato A no ganó aquí)) y contienen información de algún modo superficial: ¿Ganó el candidato en esa región? ¿alguien vive allí?
Como nuestra meta fue representar el número total de muertes por COVID-19 en Brasil en un momento determinado, también debemos mostrar la cantidad de personas que viven en un área determinada.
Sin este elemento, se corría el riesgo de confundir un espacio grande con un área densamente poblada, que no siempre es el caso. Más personas viven en una cuadra en el centro de San Pablo que en un área de decenas de kilómetros al norte del país, por ejemplo.
Así que también buscamos referencias en proyectos que se enfocaban en resaltar esta dimensión geográfica.
Entre los proyectos que investigamos, uno muy interesante fue desarrollado por The Pudding, en el cual la cantidad de personas viviendo en un área determinada se representaba como una barra en la parte superior de un mapa, generando “montañas”.

Mapa de densidad de población producido por la empresa de periodismo de datos americana llamada The Pudding
El resultado es una vista inusual de la distribución de la población mundial, que es más intuitiva y fácil de leer que los mapas clásicos de colores o mapas de calor.
Otra referencia importante fue una gráfica interactiva publicada por el periódico Nexo, que debido a problemas técnicos ahora es inaccesible.
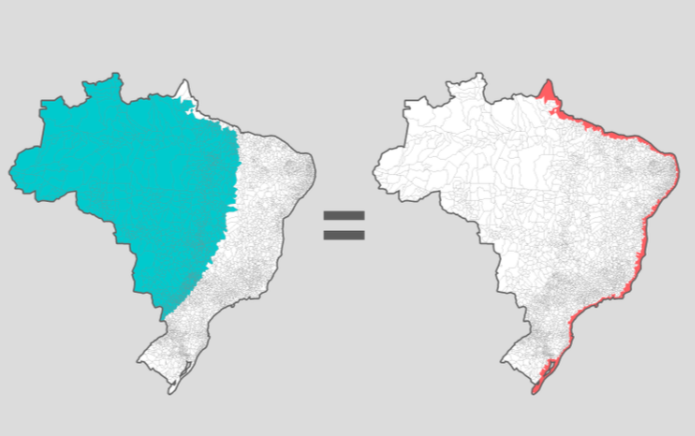
En el área azul y el área roja vive la misma cantidad de personas
En la gráfica de Nexo, después de que los participantes revelaban dónde vivían, veían un mapa de Brasil resaltando varios municipios cuya población combinada coincide con la cantidad de personas que vive en la ciudad del participante.
Para coincidir con la cantidad de personas que viven en una ciudad como San Pablo, por ejemplo, fue necesario pintar la mayoría de las regiones del norte y noroeste de Brasil. De este modo, la distribución desigual de la población del territorio se representó desde un punto de vista muy personal.
Tanto el trabajo de The Pudding como el de Nexo dependen, sin embargo, de un grado de abstracción. El primero es, prácticamente, un gráfico de barras con escalas implícitas. El segundo pinta polígonos de cierto color cuando se cumple una condición.
También nos inspiró la noción de una representación simplificada de la población: donde cada persona está representada por un punto, llamado mapa racial de puntos, y que fue una idea desarrollada por investigadores en la Universidad de Virginia.

Imagen: Cada punto representa a una persona. Cada color, una raza. Captura de pantalla.
La visualización de datos usa unidades de censo para mostrar dónde viven las personas de distintas etnias en Estados Unidos. Cada una está representada por un color. Nexo también produjo un mapa similar, pero con datos brasileros.
Además de las referencias de representación visual, también buscamos artículos que personalizaran al máximo la experiencia de lectura. Se usaron dos reportajes más de The New York Times como ejemplos de buenas prácticas.
El primero era sobre el aumento de las temperaturas en muchas ciudades del mundo, personalizado para comenzar siempre con la ubicación del lector.

Imagen: El gráfico personalizado muestra el aumento de las temperaturas en la ciudad del lector. Captura de pantalla.
El segundo usa una estrategia similar para abordar la contaminación del aire.

Imagen: La cantidad de micropartículas de contaminación del aire en la ciudad del lector está representada por pequeños círculos. Captura de pantalla.
Por último, también nos rodeamos de historias e imágenes que tenían una estética poderosa y un impacto emocional.
Entre ellas estaban imágenes de las fosas poco profundas que fueron portada de muchos periódicos durante el pico de la epidemia en Manaos y San Pablo. La cantidad de tumbas podría servir como indicador de la evolución de la pandemia, con un atractivo visual sólido y sombrío.

Imagen: Tumbas abiertas en San Pablo. Fotografía de José Antonio de Moraes/Anadolu Agency/Getty.
Los tributos y las listas de nombres, como el Memorial Inumeráveis (Memorial Innumerable en español), fueron importantes en el proceso.

Imagen: El proyecto recopila obituarios de las víctimas de COVID-19 en Brasil. Captura de pantalla.
Esa iniciativa recopila pequeños obituarios de algunas de las víctimas de COVID-19, resaltando que cada uno de los números representa a una persona única e irremplazable.
La lista de arriba, por supuesto, no es exhaustiva, pero muestra algunas de las piezas que nos inspiraron.
Usamos como referencia mucho más contenido durante algunos de nuestros chats informales. De esas incontables influencias, pudimos refinar nuestro concepto inicial.
Ideas de arranque
Una vez lista la lista de referencias, llegó el momento de usarla como arranque para nuestras propias ideas y luego mezclarlas todas para generar algo nuevo e interesante.
Teníamos una idea general de que nuestra tarea sería mostrar la distribución de las muertes por COVID-19 creando un perímetro que rodeara al lector. Sin embargo, había muchas formas de hacer esto.
Para elegir la mejor forma de contar la historia, decidimos crear un inventario de ideas y solo elegir las mejores entre esas.
Así que enumeramos once propuestas. Muchas eran muy parecidas entre sí, con diferencias solo en los métodos o la representación visual. Otras trataban de ser tan creativas que se alejaban mucho del concepto original. Todas se mencionan en el gráfico a continuación.

Imagen: Cortesía. Borrador hecho a mano con los once proyectos que se consideraron antes de escoger el formato final. Captura de pantalla.
Estos garabatos son difíciles de entender, unas semanas después de que se escribieran, incluso a nosotros nos costó recordar exactamente qué significaba cada uno.
Para ayudarnos a resolver estos acertijos, consideramos las siguientes ideas.
- Rodear con un círculo las coordenadas geográficas que daba el usuario. El tamaño del radio se calcularía usando la densidad demográfica de la región como un estimado, que también se usaría para llenar el área con puntos.
- Un concepto parecido, pero que enfatiza la relación entre los casos y las muertes. El círculo que muestra los casos sería enorme, devorando ciudades enteras y revelando que la enfermedad está mucho más extendida de lo que parece.
- En lugar de preocuparnos por la densidad demográfica que rodea al usuario, en esta propuesta transformaríamos todo el panorama en un cementerio abarrotado, por ende, la dimensión sería la misma sin importar la ubicación del usuario.
- Esta idea implicaba encontrar áreas grandes y conocidas cerca del lector, como parques y plazas y llenarlas de tumbas suficientes para enterrar a todas las víctimas mortales de la epidemia en Brasil.
- Una idea parecida a la del punto 1, pero ahora simplemente agregaríamos la población de sectores adyacentes basándonos en datos del censo (ampliaremos sobre esto en breve).
- Otra idea similar a la propuesta anterior, pero con otra fuente de datos: una cuadrícula estadística del Instituto Brasileño de Geografía y Estadísticas – IBGE. Explicaremos detalladamente más adelante, pero el método hacía ver el mapa como una cuadrícula.
- Aquí, la idea era eliminar del mapa varias ciudades cercanas al usuario; aquellas en las cuales la cantidad de habitantes es menor a la cifra total de muertes por COVID-19 en Brasil.
- Otra propuesta similar al punto 1, pero esta vez con un mapa 3D con más detalles sobre las zonas y edificios afectados en lugar de un mapa sencillo de la calle.
- Ampliando la idea del punto 8, este mapa mostraría los edificios en la ciudad del usuario con más detalle.
- Menos convencional y pretenciosamente artística, esta propuesta usaría realidad aumentada para soltar una lágrima por cada una de las víctimas del COVID-19 en la pantalla del lector.
- Intentando combinar la originalidad de la propuesta 10 y las referencias geográficas individualizadas de todos los demás puntos, esta propuesta mostraría cómo el entorno de un lector se podría haber visto afectado por la pandemia a través de la cámara del celular del usuario.
Nuestra lista reveló la profundidad de nuestra creatividad, pero al final escogimos una propuesta muy similar al concepto original y más fundamentada. ¿Por qué?
Los criterios para escoger cuál proyecto realizar fueron la disponibilidad de los datos, la factibilidad técnica, estética, y la posibilidad de enviar un mensaje que tuviera sentido para la mayor cantidad de personas posible.
¿Cómo le fue a cada una de las propuestas clasificadas según estos criterios? Veamos cada uno individualmente.
Las propuestas que implicaban realidad aumentada serían difíciles de ejecutar con un equipo pequeño en un período corto.
Las que dependían de modelos 3D solo serían interesantes para aquellos en las pocas ciudades brasileñas con muchos edificios altos.
La propuesta para transformar espacios públicos en cementerios dependería de si existían áreas suficientemente amplias cerca del usuario, que puede no ser el caso en regiones lejos de los centros urbanos más grandes.
Distribuir tumbas alrededor del lector minimizaría la personalización de la experiencia, ya que el resultado sería similar para todos, sin importar las características de la región.
Quedamos solo con los puntos 1, 2, 3, y 4. Al final, no escogimos solo una idea para desarrollar: el producto final se creó con elementos tomados de todas ellas.
El guión
Luego de rebotar ideas, decidimos que la mejor opción sería poblar el vecindario del usuario para reflejar todas las muertes por COVID-19 en el país.
Sin embargo, el material no podía reducirse a eso. Aunque el elemento interactivo ya era cautivador, el artículo necesitaba una narrativa real.
Contar una historia, relacionar ideas y evocar una secuencia de imágenes es esencial para el contenido memorable. Sin eso, tendríamos una creación virtual hermosa e interactiva, pero incapaz de brindar información útil.
Como queríamos desarrollar una estructura narrativa capaz de dejar huella, queríamos ofrecer algo más que un objeto digital colorido y divertido.
Comenzamos el reportaje desde el punto de vista más personal posible, literalmente sobre la casa del usuario. Sin embargo, a medida que progresa la historia, nos alejamos gradualmente del punto de vista del usuario.
Primero, nos trasladamos a una ciudad vecina que se desaparecería del mapa.
Luego, llegamos a una capital cercana.
Por último, les recordamos a los lectores que las víctimas realmente no estaban dispersas alrededor de sus casas, pero que no obstante son reales.
Sin darnos cuenta, creamos una estructura que evocaba la dinámica de la información, llamada “vista cercana” y “vista lejana” establecida por la investigadora estadounidense Nikki Usher.
En el libro de 2016 “Periodismo interactivo”, Nikki Usher afirma que una de las posibilidades del periodismo de datos es ofrecer un alcance que sea tanto personalizado y cercano a la realidad del lector, como amplio al exponer los temas que afectan a toda la sociedad.
En resumen, esto es lo que intentamos hacer: contar una historia que comienza en el vecindario del usuario, pero revela un panorama social más amplio.
Manos a la obra
Para este momento, ya sabíamos lo que queríamos crear. Sin embargo, todavía no estábamos seguros de cómo lo haríamos.
Luego de otra lluvia de ideas, nos dimos cuenta de que la mejor forma de descubrirlo era ensuciándonos las manos. Así que comenzamos a hacer pruebas para ver qué funcionaba mejor en la práctica.
Basándonos en los resultados de proyectos pequeños de prototipo, podríamos tomar una decisión informada y luego avanzar al proyecto a gran escala con todas sus complejidades.
Lo primero a elegir era evidente: cuál fuente de datos utilizar.
Distribución de la población
La base de datos más importante para este proyecto sería la que mostrara la distribución de la población de Brasil, de la cual se harían todos los cálculos. Teníamos dos opciones, ambas producidas por el IBGE.
La más detallada era la cuadrícula estadística, que se utilizó en uno de los proyectos mencionados como referencia: el mapa “Aqui não mora ninguém” (aquí no vive nadie), de la empresa de consultoría Plan C.
Divide el territorio brasileño en una serie de rectángulos de 200 m², en zonas urbanas, y 1 km² en zonas rurales, sin obedecer a límites administrativos como municipios o estados. Los datos muestran cuántas personas viven en estos polígonos.

Imagen: Cada rectángulo en la imagen de arriba es un ítem en la cuadrícula estadística de IBGE. Mientras más oscuros los colores, mayor es la densidad de población de las áreas. Captura de pantalla.
La otra alternativa eran las áreas de censo, que son divisiones territoriales hechas para organizar el Censo de 2010. Son de distintos tamaños y obedecen los límites estatales y de las ciudades, a diferencia de la primera opción.
A pesar de ser menos granular, la base de datos por sectores brinda información más densa. Además de la cantidad de personas viviendo en cada polígono, también conocemos la edad de cada persona y el ingreso promedio de los habitantes, por ejemplo.

Imagen: Las áreas de censo son usualmente más pequeñas en zonas con menor densidad de población y más grandes en áreas con menor densidad demográfica. Captura de pantalla.
Para comenzar, empezamos con la base de datos más detallada, así que hicimos algunas pruebas con la cuadrícula estadística, pero rápidamente surgieron problemas.
Había muchos archivos grandes, lo que hizo que procesarlos fuera más difícil y lento. La base de datos completa tiene 13.5 millones de polígonos, lo que significa que eran muchos ítems para computar efectivamente.
El guión tenía que ejecutarse en un máximo de 3 segundos, en el peor de los casos. Un segundo más, y la página tardaría mucho en cargar, y no hay nada más frustrante para los lectores que una página que carga lento. Así que comenzamos a probar con las áreas de censo.
Aunque la base geográfica del censo de 2020 es grande, divide el país en muchos segmentos menos: unos 350 000, lo que disminuyó la complejidad de computación por órdenes de magnitud.
Aparte, dos de los miembros del equipo ya habían trabajado con las áreas de censo. En 2018, publicamos un reportaje que comparaba esta información demográfica con los datos electorales.
Una de las opciones, por lo tanto, era más fácil de utilizar y, además, era conocida para nosotros. Se tomó la decisión.
Las muertes
La segunda base de datos necesaria para hacer que funcionara la aplicación, en teoría debería ser muy simple: necesitábamos saber la cantidad de muertes por COVID-19 en Brasil. Sin embargo, las cifras reveladas por las autoridades habían sido confusas desde el inicio de la pandemia.
Durante las primeras semanas, los datos se divulgaban de forma errática y hubiesen tenido poca granularidad. Últimamente, los cambios metodológicos habían erosionado la confianza en la información oficial del Departamento de Salud.
Para sortear la falta de datos, muchas entidades independientes estaban recopilando y publicando sus propias estadísticas. Así que, una vez más, necesitábamos escoger una fuente.
Entre las opciones estaban los datos del Concejo Nacional de Secretarios de Salud (CONASS, en portugués); las cifras recopiladas por un consorcio de medios, y estadísticas publicadas por investigadores y periodistas independientes, como Lagom Data o Brasil.io.
Lo esencial era publicar la base de datos en un formato cohesivo, garantizando la continuidad y la accesibilidad. De nuevo, evaluamos cada opción.
Ni los datos del CONASS ni los del consorcio de medios estaban publicados en un formato accesible.
Lagom Data publica las cifras con un formato abierto, a través de un enlace de descarga, en lugar del sistema API que facilitaría nuestra recopilación de datos.
Por descarte, solo quedaba Brasil.io. Con aproximadamente 40 voluntarios, el equipo dirigido por el desarrollador Álvaro Justen había estado recopilando cifras diarias de casos y muertes por COVID-19 en todas las ciudades brasileras desde marzo.
Además, el proyecto tenía licencias Creative Commons y GNU, que permiten reproducir el contenido. Estos principios son parecidos a los que hemos adoptado para este proyecto, que también es de fuente abierta y hace su mayor esfuerzo para ser replicable.
Con los mapas y el número de muertes en mano, ahora necesitábamos desarrollar una fórmula para calcular las áreas que resaltaríamos alrededor de cada usuario.
A partir de aquí, explicaremos los detalles sobre qué hace la aplicación tras bastidores.
Tras bastidores
En la práctica, solo uno de los elementos era difícil de desarrollar: calcular el área alrededor del usuario. Al estar lista, esta función también serviría para simular los efectos de la enfermedad en estas capitales de estados.
Calcular el área resaltada, sin embargo, sería complejo a nivel computacional. Con eso, llegaron las preguntas técnicas: ¿cuál lenguaje de programación deberíamos usar? ¿Cómo podríamos asegurar la ejecución más rápida posible? ¿Cómo podríamos desarrollar una solución eficiente en semanas?
En aras de mantener lo conocido, decidimos usar Python para desarrollar el back-end del proyecto. El lenguaje no es el más rápido disponible, pero compensa por su lentitud con flexibilidad y una serie de módulos útiles.
La mayoría de los cálculos usan el paquete de análisis geoespacial GeoPandas, y otros programas relacionados, como Shapely.
Sin embargo, las tecnologías utilizadas eran un problema secundario. Antes de escribir el código, necesitábamos definir un algoritmo, es decir, un cálculo paso a paso detallado.
Algoritmo: Plan A
Primero, probamos un enfoque basado en seleccionar polígonos adyacentes hasta que alcanzáramos la población requerida. Lo hicimos siguiendo estos pasos:
- Con las coordenadas geográficas enviadas por los usuarios, pudimos averiguar sus sectores en el censo.
- Luego, pudimos seleccionar las áreas de censo cercanas y comprobar si tenían la población necesaria.
- Si no la tenían, se seleccionaban las áreas cercanas a las cercanas, y así sucesivamente.
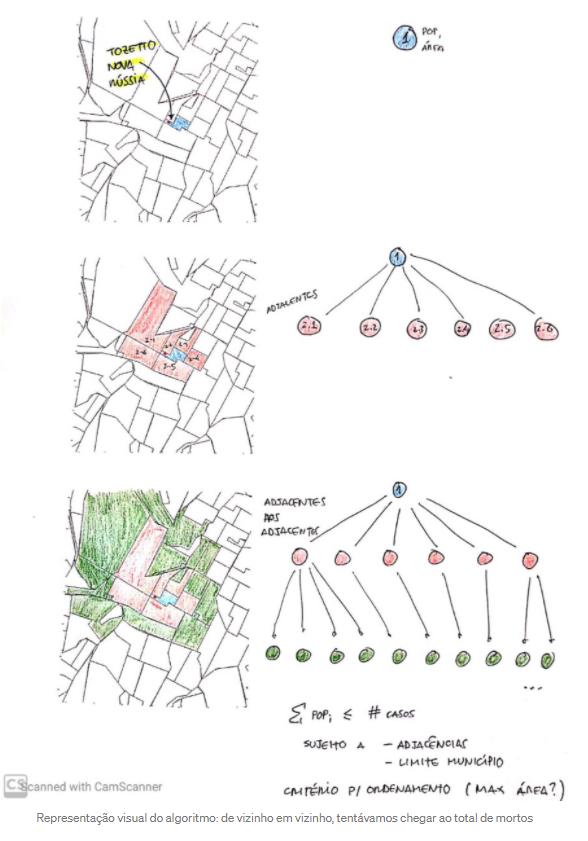
Imagen: La representación visual del algoritmo: de vecino en vecino, intentamos alcanzar el número de víctimas. Captura de pantalla.
Luego de implementar esta solución y probar el programa usando algunas coordenadas, hallamos un problema.
Aunque el desempeño fue rápido y la lógica era simple, el resultado fue una serie de áreas amorfas. Las figuras parecían arbitrarias y no tenían sentido para nadie que no conociera el método de cálculo.

Imagen: Resultado del algoritmo en el vecindario Barra Funda, en San Pablo: ¿cómo explicamos el significado de esta área roja extraña? Captura de pantalla.
Explicar cómo logramos y mostramos la periferia sería difícil y comprometería la efectividad del mensaje. Así que probamos un método alternativo.
Algoritmo: Plan B
Ahora sabíamos que los resultados del cálculo final debían ser entendidos fácil e inmediatamente. También nos dimos cuenta de que la idea de ubicar al usuario en el centro de la epidemia sugería una forma específica: un círculo alrededor de la ubicación del lector.
Así que (¡por ahora!), dejamos a un lado la complejidad computacional, la elegancia del código y el desempeño. Primero, tendríamos que calcular el radio, luego optimizaríamos el programa si fuese necesario.
Brevemente, los pasos para el nuevo cálculo fueron:
- Fijar un punto en el mapa, representando las coordenadas del usuario.
- Aumentar el radio de ese punto para descubrir cuáles sectores del censo cruzaban este nuevo círculo.
- Agregar la población de cada sector de censo según el porcentaje de intersección. Si un sector de censo con 100 residentes estaba 100% dentro del círculo, por ejemplo, lo incluiríamos todo. Si estaba 30% dentro, contaríamos solo 30.
- Si la cantidad de personas dentro del círculo era entre 90% y 110% del total de muertes por COVID-19 en Brasil, redondearíamos.
- Si la población dentro del círculo era menos que el total de víctimas en el país, aumentaríamos el radio del círculo y repetiríamos el cálculo.
- Si la población dentro del círculo era mayor al total de víctimas, reduciríamos el radio del círculo y repetiríamos el cálculo.
Aunque este método es más complejo que el ejemplo anterior, generó resultados más fáciles de entender. Los casos de COVID-19 ya no se extendían arbitrariamente, sino en direcciones uniformes alrededor del usuario.
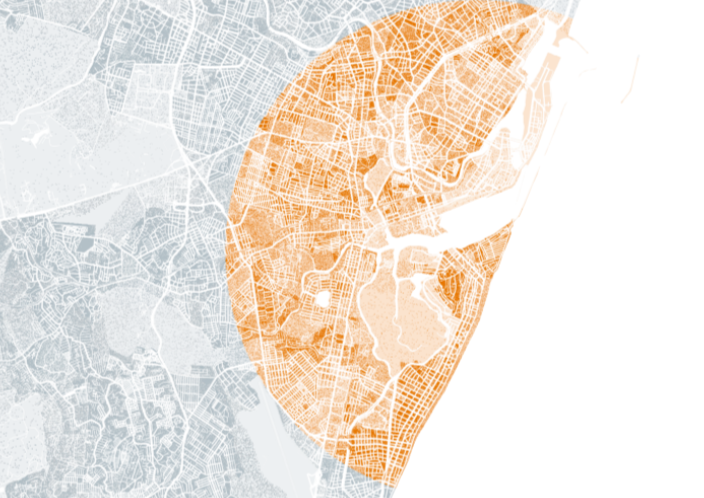
Imagen: El radio de muertes desde el centro histórico de Recife. El formato circular envía un mensaje más efectivo. Captura de pantalla.
Sin embargo, estos buenos resultados tenían un precio: un tiempo de ejecución más largo. El desafío ahora era hacer que el guión corriera lo suficientemente rápido para una aplicación en la nube.
Problemas de desempeño
Ya habíamos estimado que el tiempo máximo aceptable para el cálculo eran 3 segundos. Una demora mayor pondría impaciente al lector. Y, en cualquier caso, ¿quién espera tres segundos para que cargue un contenido hoy en día?
En el formato original, sin optimizar ni desarrollar para un mejor desempeño, el programa se tardó diez veces más que eso. Después de algunas pruebas, identificamos los cuellos de botella principales. Eran estos:
- Todos los sectores del censo estaban cargando en la memoria.
- Estábamos calculando el porcentaje de intersección entre cada sector de censo y el radio del círculo.
- Y estábamos averiguando cuáles sectores del censo hacían intersección con el círculo.
Allí fue que varios módulos de Python nos salvaron el pellejo: Feather, Rtree, y PyGEOS. Todos amplían y optimizan las funciones de GeoPandas. Además, nos dimos cuenta de que tendríamos que preprocesar los datos de la base de áreas de censo.
Pero ¿cómo exactamente nos ayudaron estas herramientas y qué tipo de preprocesamiento fue necesario? Veamos, uno por uno:
- Brasil tiene más de 300 000 sectores de censo. Sin embargo, solo necesitábamos una cantidad pequeña de sectores alrededor de la ubicación de cada lector. Así que tuvimos que encontrar una forma de cargar solo los datos relevantes.
Para hacer esto, dividimos el territorio brasilero en 10 000 rectángulos y guardamos cada uno, con sus respectivos sectores, en un archivo distinto.
De esa manera, podíamos examinar solo el rectángulo que representaba la ubicación del punto que dio el usuario, o también los rectángulos adyacentes, en los casos en que el sector más cercano no tenía la población requerida para nuestro cálculo.
Esta estrategia redujo significativamente el tiempo de espera, pero todavía había una forma de hacer más rápido el proceso. En lugar de usar archivos en el formato shapefile provisto por la IBGE, escogimos el formato feather, que fue creado específicamente para acelerar la lectura de las operaciones.
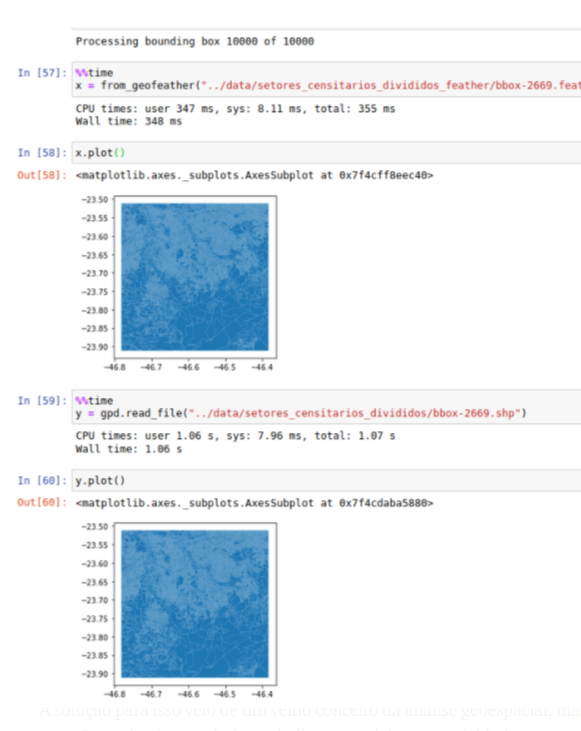
Imagenes: Comparación entre el tiempo requerido para leer un archivo en los formatos shapefile y feather: el último es casi tres veces más rápido. Capturas de pantalla.
- Para calcular cuántas personas viven dentro de un radio dado, necesitábamos calcular la intersección entre cada área de censo y el área del círculo. Usualmente, GeoPanda usa un paquete de menor nivel llamado Shapely para este tipo de operación.
El problema es que Shapely no es suficientemente rápido para procesar cientos de polígonos simultáneamente, ya que no soporta operaciones vectorizadas. Estas operaciones son lo que hacen que los paquetes estadísticos ejecuten los códigos rápido.
Sin embargo, hay un paquete llamado PyGeos que, aunque es menos flexible, usa vectores para hacer lo mismo que Shapely.
La versión más reciente de GeoPandas incluye soporte opcional para estas funciones. Con una línea adicional de código, la velocidad del programa aumenta considerablemente.
gpd.options.use_pygeos = True
- Por último, necesitábamos hallar la forma más rápida de calcular cuáles sectores de censo hacían intersección con el círculo.
La solución llegó gracias a un antiguo concepto de análisis geoespacial, del que todavía no sabíamos: los índices espaciales, implementados en GeoPandas a través del paquete Rtree.
Este concepto es algo parecido al punto 1: en la práctica, habría pocas áreas de censo que hicieran intersección con el círculo alrededor del lector. Entonces ¿qué sentido tiene calcular todos los polígonos, incluso los que están lejos?
Usando un índice espacial, podemos evitar este trabajo innecesario. En lugar de comprobar individualmente si cada elemento estaba tocando el círculo, pudimos crear envelopes alrededor de pequeños grupos de sectores.

Imagen: Un tipo específico de índice espacial llamado r-tree. Observa cómo los polígonos rojos más pequeños están encapsulados por polígonos más grandes. Captura de pantalla.
Estos envelopes funcionan como filtros previos: primero, comprobamos cuál tocó la circunferencia. Si ninguno lo hizo, podemos ignorar todos los sectores de censo dentro: lógicamente, ninguno de ellos hará intersección con el círculo.
Por lo tanto, sí es posible descartar una gran cantidad de entradas antes y procesar solo las que importan.
Con todas estas herramientas, pudimos lograr un desempeño suficientemente bueno para todas las zonas urbanas del país.
Después de la optimización, el tiempo de ejecución del código se redujo de medio minuto a menos de 3 segundos
Salida a escena
Con el tamaño del radio calculado desde la ubicación del lector, ya podíamos ubicar al individuo en un mapa y establecer un área a su alrededor, creando el círculo.
El siguiente reto era mostrar cada una de las decenas de miles de habitantes en esa área como puntos en el mapa, algo potencialmente complicado debido al triste hecho de que la cantidad de fallecidos seguía aumentando diariamente.
Además, los puntos tendrían que hacerse alrededor de la ubicación del lector, respetando la población de los sectores del censo interceptados por el círculo. Finalmente, todavía debíamos evitar que se mostraran en lugares como calles, parques y lagos.
Como ninguno de nosotros tenía mucha experiencia con la visualización de datos en mapas, no sabíamos cómo hacerlo. Así que, igual que en todas las fases del proyecto, consideramos una serie de resultados distintos antes de llegar al producto final.
Podríamos, por ejemplo, hacer un mapa básico usando paquetes como D3.js o una imagen estática de un mapa, un resultado más fácil pero que no tenía la ambición de un proyecto como este.
Así que decidimos crear un “mapa escurridizo”, en otras palabras, un mapa interactivo que permitía al usuario acercar o deslizar la pantalla, por ejemplo. Sin embargo, teníamos todavía otras preguntas.
Podíamos elegir entre varios servicios como Mapbox, Leaflet, o Google Maps. Con cualquiera que eligiéramos, todavía necesitábamos decidir cómo implementar las capas adicionales para hacer el círculo, agregar los puntos y otros elementos visuales que, a su vez, se podían hacer usando SVG, Canvas, u otra función del mismo servicio de mapas.

Imagen: Decidir cómo implementar la interfaz visual del proyecto no fue sencillo. Captura de pantalla.
La tarea de escoger cómo proceder le tocó a Tiago, el ingeniero del equipo y, naturalmente, se decidió usando ecuaciones y conclusiones matemáticas que el resto de nosotros todavía no entiende.
Estimar el círculo
Por suerte, Tiago recientemente había asistido a una presentación de los diseñadores estadounidenses David Eads y Paula Friedrich.
En la videoconferencia, explicaron cómo habían desarrollado una aplicación que mapeaba la evolución del COVID-19 en Illinois. Usaron Mapbox y una biblioteca Javascript llamada turf.js.
Algo interesante sobre estas herramientas, es que te dan la opción de agregar fuentes de datos y desarrollar capas visuales mientras el lector usa el mapa.
La flexibilidad de cambiar la interfaz sobre la marcha era exactamente lo que estábamos buscando. Así que decidimos probarlas y los resultados no podrían haber sido mejores.
Para ilustrar, el ejemplo a continuación muestra cómo trazamos el círculo en una ubicación ya calculada por el algoritmo tras bastidores.
- Usamos turf.js para calcular la distancia entre las coordenadas de la ubicación del lector y las coordinadas de un punto en el círculo.
- Con esta distancia, usando turf.js de nuevo, calculamos las dimensiones del polígono para representar el círculo.
- Agregamos la información de este polígono a Mapbox, como fuente de datos y, por consiguiente, también agregamos una capa visual al mapa.
De este modo el círculo trazado se convirtió en parte de la propia interfaz, el usuario podía mover la pantalla y acercar o alejar, y la forma se adaptaría en consecuencia, comportándose como un elemento nativo.
Así evitaríamos volver a trazar la imagen cada vez que un usuario interactuara con el mapa, lo que sería una gran limitación si decidiéramos usar tecnologías como SVG o Canvas.
200 millones de puntos
Con el elemento del círculo funcionando correctamente, solo quedaba un problema: cómo representar a los habitantes de la región.
Como dijimos antes, la idea era representar a cada persona con un elemento único en el mapa. Por ende, tendríamos que mostrar, al menos decenas de miles de puntos, siempre respetando la densidad de la población de cada sector del censo.
En nuestro primer intento, probamos dibujar todos los puntos en el propio navegador. La implementación fue más difícil de lo que parecía.
Los Turf.js pueden generar puntos aleatorios dentro de un rectángulo, pero no si la forma es irregular como los polígonos de las divisiones territoriales del IBGE.
Por lo tanto, primero teníamos que calcular el cuadro delimitador, algo como un envelope rectangular alrededor del polígono, para cada sector del censo y luego llenarlo con los puntos. Luego, comprobamos cuáles de estos estaban realmente dentro del sector y descartamos los demás.
Con este método, si generábamos solo un ítem por cada habitante, siempre nos faltarían ítems en el mapa, ya que ignoraría la mayoría.
La solución fue estimar cuántos puntos generados dentro del rectángulo entrarían o saldrían del área de censo. Así pudimos crear puntos adicionales para compensar la diferencia.
Nos enfrentábamos a un problema de probabilidades geográficas y, en ese momento, tener a un ingeniero en el equipo de periodistas y diseñadores marcó la diferencia.
Al final, logramos el siguiente resultado:

Imagen: Uno de los primeros prototipos, resaltando las muertes alrededor de una ubicación en el municipio Palhoca, SC. Captura de pantalla.
Como era de esperarse, calcular y procesar decenas de miles de puntos requiere mucha capacidad de procesamiento. El trabajo pesado probablemente colgaría el navegador de muchos usuarios, especialmente en dispositivos móviles y computadoras viejas.
Así que, afrontando la imposibilidad de ejecutar la simulación y el cálculo de los puntos en la ubicación durante el tiempo de ejecución, comenzamos a considerar otras alternativas. No había escapatoria sin hacer parte del preprocesamiento tras cámaras.
Sin embargo, lo que parecía un obstáculo en el camino hizo que la idea ambiciosa que ya teníamos se volviera más atractiva: generar y cargar previamente al mapa una capa con 190 millones de puntos, uno para cada persona de Brasil, según los datos de 2010.
En lugar de solo crear los puntos dentro del círculo, los dispersaríamos por todo el territorio nacional. El radio ahora sirve solo para enfatizar los puntos en el área afectada, como se muestra en la siguiente imagen.

Imagen: Prototipo del mapa mostrando un punto por cada habitante de Brasil, en lugar de mostrar solo un punto por cada víctima de COVID-19. Captura de pantalla.
Los puntos se procesaron de forma similar a nuestro primer experimento: generados de forma aleatoria dentro de los cuadros delimitadores de los sectores de censo, en cantidades suficientes para garantizar que, al final, la cantidad total de puntos dentro de cada polígono sería similar a sus respectivos habitantes.
Gracias a Python, en lugar de volver a hacer esto cada vez que un usuario interactuaba con el mapa, el cálculo se haría solo una vez. Los datos resultantes (unos 23 gigabytes de información geográfica) se convirtieron en tilesets usando un programa desarrollado por el equipo de Mapbox, llamado tippecanoe.
En la práctica, esto significa que todos los puntos se han guardado como una capa adicional en el mapa, en el mismo formato que la cuadrícula de la calle, por ejemplo. Con esto, pueden mostrarse, cargarse, y modificarse con el procesamiento mínimo.
Finalmente, esta montaña de datos terminó siendo procesada por una computadora notebook de 10 años. Probablemente, lo que evitó el incendio fue el sistema de refrigeración improvisado “creado” en la desesperación del amanecer:

Imagen: Sistema de ventilación hecho con piezas de Lego evitó que esta pobre computadora se quemara. Captura de pantalla.
Las piezas fundamentales del proyecto estaban listas, aunque todavía faltaba mucho por hacer y hacía falta trabajo meticuloso para refinar las interacciones, scripts, estética y muchos otros detalles y problemas que fuimos enfrentando durante el desarrollo del proyecto.
¿Qué aprendimos?
Al final de un período con una carga de trabajo tan fuerte como esta, es imposible no aprender algunas lecciones valiosas para tu próximo proyecto. Por cliché que suene, no podemos imaginarnos una forma mejor de terminar este texto que haciendo una lista de estos descubrimientos.
Dividir las tareas y trabajar en equipo
Mientras armábamos el equipo para el proyecto, decidimos que cada uno de nosotros debía estar dedicado a un área específica. Una persona procesaría los datos, otro trabajaría con las herramientas y otro definiría la identidad visual.
En teoría, son tareas bastante compartimentadas.
Por supuesto, al final de la línea de ensamblaje, los resultados se combinan para funcionar como un sistema único, en cuanto a la tecnología.
Hubiese sido muy posible que cada uno de nosotros nos sentáramos en nuestras computadoras y solo habláramos entre nosotros sobre el procesamiento de datos. Por suerte, nuestra rutina era muy distinta. En las reuniones regulares por videoconferencia y, principalmente, a través de un grupo de WhatsApp que estuvo activo durante muchas madrugadas, constantemente hablamos sobre todas las dimensiones del contenido.
Aunque cada miembro del equipo tenía una tarea específica que cumplir, las huellas de todos se pueden ver en todo el material.
Logramos el equilibrio perfecto: operar con una división estricta de las tareas, pero con la libertad de hacer sugerencias sobre temas fuera de nuestras respectivas responsabilidades.
La primera parte de la ecuación garantizaba la productividad y eficiencia. La segunda, una fuente más grande de creatividad y pensamiento crítico.
Lluvia de ideas eterna
El grupo de WhatsApp también sirvió como depósito para enlaces no conectados, conceptos a medio pensar, y malas ideas.
Cuando se pone así, parece que la comunicación allí solo generaba ruido, pero era exactamente lo opuesto.
En lugar de confinar la búsqueda de referencias a las etapas iniciales del proceso creativo, este entorno caótico nos sumergió en una especie de lluvia de ideas constante.
Lo compartíamos todo, incluyendo sugerencias para cursos en línea sobre diseño y machine learning, discusiones sobre el uso del color en los mapas, imágenes de vitrales de iglesias que parecían mapas de calor, e incluso imágenes de árboles secos en el desierto de Namibia.

Imagen: Los archivos compartidos en el grupo de WhatsApp: referencias, pruebas, memes, cursos y árboles secos.
Todo este “caos” terminó contribuyendo indirectamente a la materialización del proyecto. De allí vinieron ideas sobre paletas de colores, metáforas visuales interesantes, y varias formas de presentar el contenido que no habíamos pensado antes.
Aprender sobre la marcha
Finalmente, descubrimos que para poner en marcha un proyecto complejo en poco tiempo, necesitas estar dispuesto y ser capaz de aprender cosas nuevas rápidamente.
De nuevo, WhatsApp es un ejemplo de esta idea: el nombre de nuestro grupo de trabajo es “Irresponsables motivados”, ¿por qué?
La verdad es que, aunque conocíamos muchas partes del desarrollo de una aplicación como esta, en la práctica nunca habíamos trabajado con muchas de estas ideas.
Como este proyecto era un trabajo adicional para todos, solo teníamos las noches para estudiar y realizar nuestras tareas. Este nivel de compromiso, nos dimos cuenta, que no era de las cosas más responsables que habíamos hecho en la vida.
Sin embargo, pronto descubrimos cómo nos compensaría esta locura: con la capacidad de lanzarnos de cabeza a un tema nuevo y comprender lo básico en poco tiempo.
Al final, no importó si nunca antes habíamos trabajado con MapBox o escuchado sobre PyGEOS, o incluso desarrollado una aplicación API interactiva. Como estas herramientas eran necesarias para el trabajo, no había otra alternativa más que leer los documentos, ver tutoriales, y aprende cómo usarlas.
Un desarrollador cualificado probablemente lea nuestro código fuente y haga una mueca. Es posible que tenga razón. ¿Qué pensamos nosotros? ¡“Hecho” es mejor que “perfecto”!
Lecturas adicionales
Claves para visualizar datos sobre el COVID-19
Mis herramientas favoritas: Alberto Cairo y la visualización de datos
Enlaces de interés sobre periodismo de datos

Esta historia fue escrita por Rodrigo Menegat, Tiago Maranhão y Vinicius Sueiro y fue publicada originalmente en portugués en Medium. Puedes leer el post original aquí.
Mis herramientas favoritas: Lisseth Boon, diseño y visualización de datos
Guía práctica para periodistas: colaboración con organizaciones de la sociedad civil y organizaciones no gubernamentales
Guía para reportajes sobre la rendición de cuentas de la IA
Guía de GIJN para investigar emisiones de metano en vertederos y sus soluciones

De reunir datos a contar historias: los consejos de concepto y diseño de John Burn-Murdoch, del Financial Times

Enriquece tus investigaciones ambientales con datos y gráficos
Mis herramientas favoritas: Gurman Bhatia sobre hacer periodismo con datos y gráficos
Mis herramientas favoritas: Lisseth Boon, diseño y visualización de datos

Esta obra está licenciada bajo un Creative Commons Reconocimiento-Sin Derivadas 4.0 Licencia Internacional
Republica nuestros artículos de forma gratuita, en línea o de manera impresa, bajo una licencia Creative Commons.
Republica este artículo
Esta obra está licenciada bajo un Creative Commons Reconocimiento-Sin Derivadas 4.0 Licencia Internacional
Leer siguiente
Periodismo de datos
De reunir datos a contar historias: los consejos de concepto y diseño de John Burn-Murdoch, del Financial Times
El jefe de datos del Financial Times analiza cómo considera el uso del texto, el color y las anotaciones para potenciar la narrativa visual de los reportajes a través de gráficos e infografías.
Preguntar a ChatGPT
Herramientas y consejos para reportear Periodismo de datos
Enriquece tus investigaciones ambientales con datos y gráficos
En la reciente conferencia de periodismo ambiental del Pulitzer Center, un panel de reporteros y diseñadores explicaron cómo hacer que las historias ambientales sean más convincentes utilizando datos y visualización.
Periodismo de datos
Mis herramientas favoritas: Gurman Bhatia sobre hacer periodismo con datos y gráficos
La periodista y diseñadora de información india Gurman Bhatia habla sobre sus herramientas favoritas de codificación y visualización de datos.
Periodismo de datos
Mis herramientas favoritas: Lisseth Boon, diseño y visualización de datos
Conoce a Lisseth Boon, periodista que ha realizado investigaciones sobre violaciones de derechos humanos, tráfico de oro, minería ilegal y delitos ambientales en Venezuela. En esta pieza Boon habla sobre herramientas de diseño y visualización para hacer mejores reportajes.