
কোডিং দক্ষতা ছাড়াই বিনামূল্যে ব্যবহারযোগ্য ডেটা এক্সট্রাকশন টুল
আর্টিকেলটি পড়ুন এই ভাষায়:

ছবি: শাটারস্টক
জিআইজেএন টুলবক্সে আবারও স্বাগতম। এখানে আমরা অনুসন্ধানী সাংবাদিকদের জন্য সাম্প্রতিক টিপস ও টুলস পরীক্ষা নিরীক্ষা করি। এই সংস্করণে, আমরা তিনটি বিনামূল্যে ব্যবহারযোগ্য এবং তুলনামূলকভাবে সহজ সল্যুশন বিশ্লেষণ করব, যা রিপোর্টারেরা নথি থেকে ডেটা স্ক্র্যাপিংয়ের কাজে ব্যবহার করতে পারেন। সম্প্রতি ২০২২ ইনভেস্টিগেটিভ রিপোর্টার্স অ্যান্ড এডিটরস্ কনফারেন্সে (আইআরই২২) যখন এই কৌশলগুলো উপস্থাপন করা হচ্ছিল, তখন সমবেত সাংবাদিকদের মধ্যে খুশির ঢেউ দেখা যায়। (ওয়াচডগ রিপোর্টারদের এমন স্বতঃস্ফূর্ত প্রতিক্রিয়ার চেয়ে ভালো স্বীকৃতি আর কী হতে পারে!)
অনুসন্ধানের জন্য দরকারি ডেটা পেয়ে যাওয়ার পর সাংবাদিকেরা প্রায়ই দ্বিতীয় আরেকটি সমস্যায় পড়েন: সেই ডেটাকে সিলেক্ট করে, তুলে নিয়ে, কীভাবে স্প্রেডশিটে ফেলবেন – যেন ইচ্ছেমত ব্যবহার করা যায়। গায়ে খেটে ডেটা এন্ট্রি, উন্নত কোডিং বা ব্যয়বহুল বাণিজ্যিক ওসিআর (অপটিক্যাল ক্যারেক্টার রিকগনিশন) সেবা ব্যবহার করা, অনেক ছোট গণমাধ্যমের জন্যই ডেটা স্ক্র্যাপিংয়ের বাস্তবসম্মত বিকল্প নয়।
![]() আইআরই২২ সম্মেলনে বেশ কয়েকজন অভিজ্ঞ ওয়াচডগ সাংবাদিক বলেছেন, তাঁরা স্ক্যান করা নথি বা “নিরেট” পিডিএফ-এর মত “অচল” ফরম্যাটে পাবলিক নথি প্রকাশের প্রবণতা বাড়তে দেখছেন, এবং কিছু সরকারি সংস্থা রিপোর্টিং প্রক্রিয়াকে বাধাগ্রস্ত করতে ইচ্ছা করেই এধরনের ফরম্যাট ব্যবহার করছে।
আইআরই২২ সম্মেলনে বেশ কয়েকজন অভিজ্ঞ ওয়াচডগ সাংবাদিক বলেছেন, তাঁরা স্ক্যান করা নথি বা “নিরেট” পিডিএফ-এর মত “অচল” ফরম্যাটে পাবলিক নথি প্রকাশের প্রবণতা বাড়তে দেখছেন, এবং কিছু সরকারি সংস্থা রিপোর্টিং প্রক্রিয়াকে বাধাগ্রস্ত করতে ইচ্ছা করেই এধরনের ফরম্যাট ব্যবহার করছে।
আরও সমস্যা হলো, বিশ্বের অনেক সংস্থা ওয়েবপেজ ঘেঁটে কাঙ্খিত ডেটা খুঁজে বের করতে বলে সাংবাদিকদের। কিন্তু এজন্য গোটা ডেটাসেট ঘেঁটে, অসংখ্য ট্যাব বা শিট থেকে ক্লিক করে ডেটা কপি করে নিয়ে, সেটি আবার টেবিলে (সারণী) পেস্ট করতে হয়।
“আমি উন্মুক্ত নথি চেয়ে প্রচুর আবেদন করি, এবং দেখতে পাই – যে ফরম্যাটে নথি বা ডেটার জন্য অনুরোধ করেছি, সেভাবে সেই নথি বা ডেটা পাওয়ার ঘটনা বেশ বিরল” – বলেছিলেন ইউএস টুডের অনুসন্ধানী রিপোর্টার কেনি জ্যাকবি। কনফারেন্সে তিনি বেশ কয়েকটি পিডিএফ টুল উপস্থাপন করেন। “মাঝে মাঝে মনে হয় আপনার কাজকে আরও কঠিন করতেই সংস্থাটি ইচ্ছা করেই নথিটি এভাবে দিচ্ছে – হয় একটি পিডিএফ থেকে টেক্সট সরিয়ে রাখবে, নয়তো পাঠানোর আগে স্ক্যান করবে, অথবা ডেটাগুলো কোনো কলাম ও রো ছাড়া অগোছালো ফরম্যাটে থাকবে। এই বাধাগুলো সত্যি আমাদের কাজের গতি কমিয়ে দিতে পারে, তাই এগুলো মোকাাবিলার জন্য টুল থাকা জরুরি।”
পিডিএফের বাধা জয়ে গুগল পিনপয়েন্ট ও তার নতুন ফিচার
২০২০ সালে, জিআইজেএনই প্রথম জানায় যে গুগল জার্নালিস্ট স্টুডিও কৃত্রিম বুদ্ধিমত্তা-চালিত একটি ডকুমেন্ট পার্সিং টুল নিয়ে এসেছে, যা এখন “পিনপয়েন্ট” নামে পরিচিত। সদ্য-প্রকাশিত এই টুলকে আমরা “টার্বো-চার্জড কন্ট্রোল-এফ (Ctrl-F)” ফাংশন আখ্যা দিয়েছি, কারণ এই টুলে উন্নত ওসিআর আছে, যা দ্রুত বিপুল পরিমাণ নথি এবং ছবি সার্চ করতে পারে। আইআরই২২-এর ডেটা বিষয়ক একটি সেশনে জ্যাকবি বলেছেন, পিনপয়েন্ট তখন থেকে পেশাদার সাংবাদিকদের জন্য বিনামূল্যে সহজে ব্যবহারযোগ্য ডিজিটাল মাস্টার টুল হিসেবে বিবেচিত হয়ে আসছে। এর আংশিক কারণ হিসেবে তিনি মনে করেন, এর ডেভেলপারেরা অনুসন্ধানী রিপোর্টারদের পরামর্শ গ্রহণ করেছিলেন।
জ্যাকবি দেখিয়েছেন যে পিনপয়েন্টের ডেটা ফিচারে এখন নিচের ফিচারগুলো অন্তর্ভুক্ত:
- আপনি যদি একটি একক কি-ওয়ার্ড সার্চ করেন – ধরা যাক, “ফ্যাকাল্টি” – এটি কেবল আপনার আপলোড করা গবেষণা-ফাইলে সেই শব্দের খোঁজ করবে না, বরং সম্পর্কিত শব্দগুলোও তুলে ধরবে – যেমন “টিচার,” বা “ক্যাম্পাস,” বা “প্রফেসর।” এটি সার্চ করা টার্মের অন্যান্য টেন্সও খুঁজে বের করে; পর্তুগিজ, স্প্যানিশ, ফরাসি ও পোলিশসহ সাতটি ভাষায় কাজ করে; এবং বিয়োগ চিহ্ন দিয়ে অপ্রয়োজনীয় পদগুলোও বাদ দিতে পারে।
- একগুচ্ছ স্ক্যান করা বা পিডিএফ নথি বা তাড়াহুড়ো করে হাতে লেখা কাগজ আপলোড করুন। এটি দ্রুত সেগুলোকে “সক্রিয়,” সার্চযোগ্য, কপি-পেস্ট করা যায়, এমন টেক্সট নথিতে পরিণত করতে পারে। এমনকি লেখাগুলো আনুভূমিক অবস্থায় না থাকলেও, এটি সেখান থেকে শব্দ পড়তে পারে।
- এই টুল ছবি থেকে চিহ্ন বা গ্রাফিতি সনাক্ত করতে পারে। এটি টেক্সটকে শুধু ট্রান্সক্রাইবই করে না, বরং ছবির ব্যাকগ্রাউন্ডে ফলক বা নোটিশবোর্ডে পাওয়া ছোট স্ক্রিপ্টের বড় অনুচ্ছেদকেও লেখায় রূপান্তরিত করতে পারে। (পিনপয়েন্টের ডেমো চলাকালীন একটি ছবিতে জটিল, জীবনী তথ্যসম্বলিত কোনাকুনি ফলকে ছোট ছোট লেখা পড়তে এবং প্রক্রিয়াজাত করতে পারায় উপস্থিত সাংবাদিকেরা আনন্দে চিৎকার করে ওঠেন ৷ এনবিসি টেলিমুন্ডোর রিপোর্টার ভ্যালেজকা গিল অবাক হয়ে বলেন: “হায় ঈশ্বর! আপনি আমার জীবন বদলে দিয়েছেন – এটি আমার অনেক সময় বাঁচাবে।”)
- জ্যাকবি বলেন, এর অডিও এবং ভিডিও ট্রান্সক্রিপশন ফিচার এখন এত উন্নত যে তিনি তাঁর অডিও সাক্ষাৎকারের সার্চযোগ্য ট্রান্সক্রিপশন তৈরি করতে ট্রিন্ট বা অটারের মতো অল্পমূল্যের ট্রান্সক্রিপশন টুলের বদলে বিনামূল্যের টুল পিনপয়েন্ট ব্যবহার করেন। তিনি আরও বলেন, “এর এই বৈশিষ্ট্যটি সেই টুলগুলোর মতই, তবে এটি বিনামূল্যে করা যায়। ট্রিন্ট ও অটার করে, অথচ পিনপয়েন্ট করে না, এমন একটি কাজ হলো – কে কথা বলছে তা সনাক্ত করা এবং প্রত্যেক ব্যক্তির নাম দেয়া — যেমন ‘স্পিকার ২’। তবে এটি কথোপকথনে যৌক্তিক বিরতি এবং কণ্ঠস্বরের ওঠানামা সনাক্ত করে। আপনি কেবল টেক্সট ট্রান্সক্রিপ্টের যে কোনো একটি বিন্দুতে ক্লিক করা মাত্র এটি সেই বিন্দুতে প্লে করা শুরু করবে।”
জ্যাকবি বলছিলেন, পিনপয়েন্টের ফিচারগুলোতে বিনামূল্যে ব্যবহারের সুবিধা এখন অনেক সহজ, এবং বড় প্রকল্পের জন্য তাঁদের টেকনিশিয়ানদের কাছ থেকে অতিরিক্ত স্টোরেজ চেয়ে নেওয়া যায়।
“এটি ব্যবহারের জন্য আপনাকে অনুমোদন পেতে হবে, তবে আমি এবং আমার স্ত্রী – যিনি নিজেও একজন সাংবাদিক – যখন সাইন আপ করেছিলাম, তখন আমরা প্রায় সঙ্গে সঙ্গেই অনুমোদন পেয়েছিলাম,” তিনি জানান। “আপনার একটি প্রাতিষ্ঠানিক ইমেল অ্যাড্রেস প্রয়োজন হতে পারে, তবে এটি ব্যবহারের সুযোগ পাওয়া তেমন কঠিন নয় এবং এই দলটি খুব দ্রুত সাড়া দেয়।”
নেতিবাচক দিক? পিনপয়েন্ট একটি সম্পূর্ণ অনলাইন সেবা।
তিনি সতর্ক করে বলেন, “তার মানে আপনার একটি ইন্টারনেট সংযোগ প্রয়োজন, আর আপনি কোথাও কোনো সার্ভারে আপনার নথিগুলো আপলোড করছেন, আর – ধরুন, গুগলের বিরুদ্ধে যদি সমন জারি করা হয় – তাহলে সম্ভবত আপনার নথিগুলো হস্তান্তর করা হতে পারে। এছাড়াও, এটি আপনাকে ওসিআর নথির কপি ডাউনলোড করার সুযোগ দেয় না – এটি পিনপয়েন্টে থাকে, তাই আপনাকে টেক্সটটি কপি-পেস্ট করতে হবে। তবে এই ক্ষেত্রে, তাদের ওসিআরটিই সম্ভবত সেরা।”
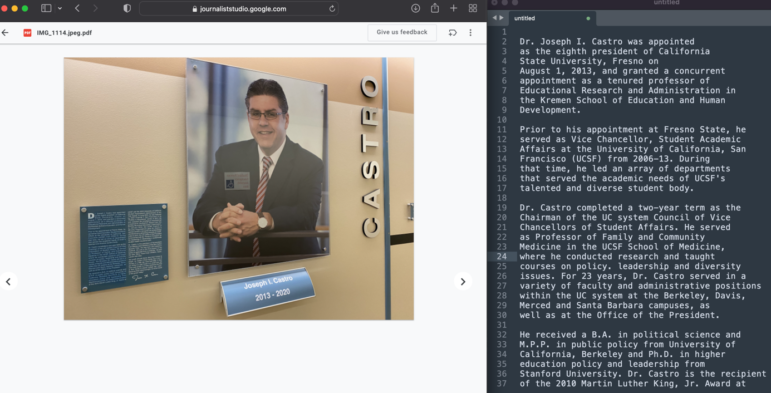
আইআরই২২-এর সাংবাদিকেরা জেনে অবাক হয়েছিলেন যে বিনামূল্যে ব্যবহারযোগ্য গুগল পিনপয়েন্ট টুলের অপটিক্যাল ক্যারেক্টার রিকগনিশন সক্ষমতা এই ছবির নীল ফলকের লেখার মতো ছোট লেখা পড়া এবং ট্রান্সক্রাইব করার জন্য যথেষ্ট শক্তিশালী। ছবি: কেনি জ্যাকবি
ওয়েবসাইটের ডেটার জন্য ইম্পোর্টএইচটিএমএল/ এক্সএমএল হ্যাক
সম্প্রতি প্রোপাবলিকার ক্রেগ সিলভারম্যান জিআইজেএনের গাইডে দেখিয়েছেন: যে কোনো ওয়েবসাইটের পেছনের সোর্স কোড অনুসন্ধানী সাংবাদিকদের জন্য প্রচুর অনুসন্ধান-টুলের যোগান দেয়, আর নন-কোডারদের জন্য কিছুটা ভীতিকর শোনালেও ব্যবহারের জন্য আসলে “কন্ট্রোল-এফ” বা “কমান্ড- এফ” এর বাইরে অন্য কোনো দক্ষতার প্রয়োজন নেই।”
আইআরই২২ সম্মেলনে, গুগল শিট থেকে স্ক্র্যাপিং বিষয়ক একটি সেশনে ফ্রিল্যান্স সাংবাদিক সামান্থা সান দেখিয়েছেন যে একটি কোড ব্যবহার করে ওয়েবসাইটে থাকা লম্বা সারণী বা নির্দিষ্ট ডেটা আইটেমগুলোকে কীভাবে সহজে, এবং সেকেন্ডের মধ্যে, আপনার পছন্দের ফরম্যাটে একটি স্প্রেডশিটে নিয়ে আসা যায়৷ এর ফলে ফাইলে আলাদাভাবে শত শত বক্স কপি ও পেস্ট করার দরকার পড়ে না। এই কৌশলে গুগল শিটকে দিকনির্দেশনা দেওয়ার জন্য শিটের সবচে ওপরে বামপাশের প্রথম বক্সে একটি ফর্মূলা (সূত্র) লিখেতে হয়। সেই সূত্রটি একটি ওয়েবপেজ থেকে আপনার প্রয়োজনীয় সোর্স কোড উপাদান সংগ্রহ করতে বলে (যে কোড পেইজ থেকে নিয়ে আপনার পছন্দের ডেটা টেবিল তৈরি করে)।
আসলে যে কোনো সাইটে একটি ভাল-ফরম্যাটের ডেটা টেবিল এক্সট্রাক্ট করতে আপনার সত্যিই কোনও কোড নিয়ে ভাবার দরকার নেই। শুধু এই পদক্ষেপগুলো অনুসরণ করুন:
একটি ওয়েবপেজ থেকে একটি একক ডেটা টেবিল নিতে – যত দীর্ঘই হোক না কেন – গুগল শিটে কেবল নিম্নলিখিত সূত্রটি টাইপ করুন: =IMPORTHTML(“URL”, “table”) যদি ডেটাগুলো লিস্ট বা তালিকা হিসেবে থাকে তাহলে “table” এর বদলে “list” লিখুন। আর যদি, ধরুন, ওয়েবপেজ থেকে দ্বিতীয় সারির ডেটা নিতে চান, তাহলে কমা এবং স্পেসের পরে সংখ্যায় 2 লিখুন: =IMPORTHTML(“URL”, “list”, 2)
ইউএস ফেডারেল ডিপোজিট ইন্স্যুরেন্স কর্পোরেশনের ওয়েবসাইট থেকে ৫৬৪টি দেউলিয়া ব্যাংকের একটি সারণী নেয়ার জন্য এই কৌশল ব্যবহারের চেষ্টা করেছিল জিআইজেএন। তখন এফডিআইসি সাইটের ইউআরএল কপি করা থেকে শুরু করে গুগল শিট খোলা পর্যন্ত এবং ব্যাংকগুলোর সম্পূর্ণ তালিকা পুরোপুরি কলামে ফরম্যাট করা পর্যন্ত গোটা প্রক্রিয়ায় ১৫ সেকেন্ডেরও কম সময় লেগেছে। যাই হোক, ইউআরএল-এর পর একটি কমা এবং বন্ধনীতে দুটি আইটেমের চারপাশে উদ্ধৃতি চিহ্নসহ সূত্রটির জন্য প্রয়োজনীয় বিরাম চিহ্ন ব্যবহার করা জরুরি। লক্ষণীয় বিষয় হলো: লাইভ ওয়েবসাইট ডেটায় কোনো পরিবর্তন হলে তা স্বয়ংক্রিয়ভাবে আপনার গুগল শিটেও দেখা যাবে। এতে করে অনুসন্ধানের সময়, চেক করার জন্য আপনাকে বার বার সেই সাইটে ফিরে যেতে হবে না – অবশ্য যদি না আপনি সেই আপডেট ফাংশনটি নিষ্ক্রিয় করে দেন।
সামান্থা সান বলেন, এরপরও, রিপোর্টারদের উচিত এইচটিএমএলের সঙ্গে অন্তত কিছুটা পরিচিত হওয়া এবং কম্পিউটারে পাশাপাশি পেজের ডেটাকে একত্র করার উপায় বোঝা, যেন অসম্পূর্ণভাবে ফরম্যাট করা তথ্য সহজে সামলানো যায় এবং আরও উন্নত সূত্র ব্যবহার করে আরও গভীরে যাওয়া যায়।
যে কোনো পেজ তৈরি হয় কোড দিয়ে, আর সেই কোড খুঁজে পেতে সাইটের যে কোনো খালি বা সাদা জায়গায় কেবল রাইট-ক্লিক করুন এবং “ভিউ পেজ সোর্স” বা “শো পেজ সোর্স” এ ক্লিক করুন। তাঁর মতে, সাধারণভাবে মনে রাখতে হবে যে, হিউম্যানফেসিং ওয়েবপেজে দেখা যে কোনো শব্দ অবশ্যই কম্পিউটার সোর্স কোডে আসবে। এরপর আপনি শুধু “কন্ট্রোল এফ (Ctrl-F)” ব্যবহার করে সেই কোড থেকে কাঙ্খিত ডেটা খুঁজে বের করতে পারবেন এবং দেখতে পারবেন যে সেই বিষয়টির সঙ্গে আর কী কী এলিমেন্ট ট্যাগ করা হয়েছে। তারপর আপনি সেই ট্যাগ ধরে আরও পরীক্ষা-নিরীক্ষা চালিয়ে যেতে পারবেন।
সান ব্যাখ্যা করে বলেন, “দরকারি হলেও, ইম্পোর্টএইচটিএমএল সূত্রটি শুধু টেবিল ও লিস্ট-ই আনতে পারে – তবে আরেকটি সূত্র আছে, ইম্পোর্টএক্সএমএল, যা যে কোনো এইচটিএমএল এলিমেন্টকে টেনে আনতে পারে। এটি দেখতে একই রকম – সমান চিহ্ন; সূত্রের নাম, ইউআরএল – তবে আপনি আরও সুনির্দিষ্টভাবে ফলাফল পাবেন।” এটি কীভাবে করবেন তা এখানে দেওয়া হলো:
একটি ওয়েবপেজে আলাদা টেবিলে থাকা ডেটার সারি, বা বোল্ড টেক্সট-অনলি, বা হেডিংয়ের মতো নির্দিষ্ট ডেটা আনতে – এ ধরনের একটি সূত্র ব্যবহার করুন (এটি ডেটা হেডিংয়ের জন্য): =IMPORTXML(“URL”, “//h2”) , অথবা (টেবিলে থাকা সারির জন্য) এটি: =IMPORTXML(“URL”, “//table/tr”)
“//h2” (হেডার) ও “/tr” (টেবিল রো) এর মতো প্রচলিত এইচটিএমএল এলিমেন্টের সংখ্যা অনেক। আর রিপোর্টারেরা এগুলো এইচটিএমএল অভিধানে খুঁজে পেতে পারেন। তবে সানের মতে, সাংবাদিকেরা যদি কেবল ডেটা সংশ্লিষ্ট জরুরি এলিমেন্টগুলো নোট করে নিতে পারেন এবং মূল কম্পিউটার জার্গন ট্যাগগুলো বের করতে পারেন তাহলেই চলবে। এটি তাদের পরবর্তী ডেটা ইম্পোর্ট ঠিক করতে সাহায্য করতে পারে। বড় বড় উইকিপিডিয়া সাইটে বেশ কিছু ডেটা তালিকা এবং টেবিল থাকে বিধায়, চর্চার জন্য এই দুটি ডেটা স্ক্র্যাপিং কৌশল ব্যবহারের চেষ্টা করতে পারেন।
নিরাপদে অফলাইনে ডেটা সংগ্রহের জন্য ইমেজম্যজিকের সঙ্গে টেসের্যাক্ট
ইউএসএ টুডে-এর কেনি জ্যাকবি বলেছেন, টেসের্যাক্ট নামে একটি ওপেন সোর্স ওসিআর ইঞ্জিন সংবেদনশীল নথির পাশাপাশি বিশাল ডেটা সংগ্রহশালার জন্য ডেটা এক্সট্রাকশনের একটি দুর্দান্ত উপায়। তবে শর্ত হলো: ইনপুট ডেটার মান যথেষ্ট ভাল হতে হবে। লক্ষণীয় বিষয় হলো, এর সর্বশেষ সংস্করণটি হিব্রু বা আরবি ভাষায় ডান-থেকে-বামে লেখা টেক্সটসহ ১০০ টিরও বেশি ভাষা চেনে।
টেসের্যাক্ট টেক্সট লেয়ারবিহীন ছবিকে এমন পিডিএফে রূপান্তরিত করে যেখান থেকে সিলেক্ট ও সার্চ করা যায়। আর জ্যাকবি বলেছেন, বিশেষ করে, বিপুল পরিমাণ “নিরেট” নথিকে লাইভ, কপি-পেস্টযোগ্য টেক্সটে রূপান্তরের জন্য এটি বেশ কার্যকর। তিনি আরও বলেন, মোটাদাগে এর অর্থ হলো, রিপোর্টারদের প্রথমে পিডিএফ ডকুমেন্টকে উচ্চ রেজুলেশনের ছবিতে রূপান্তর করতে হবে, এবং সবচেয়ে ভালো হয় যদি ওপেন সোর্স ইমেজম্যাজিক টুল ব্যবহার করে সেটি করা যায়। তারপর স্ক্র্যাপ করা ডেটা পেতে এগুলোকে টেসের্যাক্টে দিতে হবে।
“এটির ওসিআর পিনপয়েন্টের মত না হলেও বেশ ভালো,” জ্যাকবি বলছিলেন। “কিন্তু একটি বড় সুবিধা হলো এটি অফলাইনে কাজ করতে পারে – আপনি আপনার টার্মিনালে নিজের জায়গায় বসে সবকিছু করতে পারেন, তাই এটি সংবেদনশীল কাজের জন্য ভালো। একসঙ্গে অনেকগুলো নথিকে রূপান্তরের জন্য এটি সত্যিই কাজের; ১০০০ নথির প্রত্যেকটিকে এটি রূপান্তর করতে পারে, আপনি সবগুলোকে ওসিআরও করতে পারবেন।”
তিনি আরও বলেছেন: “আপনাকে ছবির মান বা কনট্রাস্ট বাড়াতে হতে পারে, আর ইমেজম্যাজিকেও আপনি ছবির মান বাড়াতে পারেন।”
এছাড়াও, টেসের্যাক্ট ও ইমেজম্যাজিক টুল নিয়ে একটি বিশদ নির্দেশিকা তৈরি করেছেন ওয়াল স্ট্রিট জার্নালের অনুসন্ধানী রিপোর্টার চ্যাড ডে। জ্যাকবি সেটি ব্যবহারের সুপারিশ করেছেন, যা এখানে গিটহাবে পাওয়া যাবে।
জ্যাকবি বলেছিলেন, টেসের্যাক্ট সল্যুশনের জন্য কিছু “মধ্যবর্তী” কোডিং দক্ষতা প্রয়োজন। তবে সেটি একবার হলেই চলে। কমান্ড-লাইনে দক্ষ যে কেউ একবার এসে প্রোগ্রাম সেট আপ করে দিলে এবং রিপোর্টারকে ছোট লাইনের দুটি কোড দিয়ে গেলে, রিপোর্টার ভবিষ্যতের প্রতিটি ডেটা এক্সট্রাকশনের জন্য সেই কোড যুক্ত করতে পারেন। পিডিএফ ফরম্যাটে প্রিন্ট করা টেবিল এক্সট্রাক্ট করতে ট্যাবুলা অ্যাপ ব্যবহারের সুপারিশ করেছেন জ্যাকবি। এই অ্যাপটি একটি সুপরিচিত ওপেন-সোর্স টুল, যা ওপেননিউজ ও প্রোপাবলিকার সাংবাদিকেরা তৈরি করেছেন। “এটি মূলত পিডিএফ থেকে ডেটা টেবিল আলাদা করে এবং সেগুলোকে স্প্রেডশিটে জমা করে,” তিনি ব্যাখ্যা করছিলেন।
ট্যাবুলা ব্যবহার করে রিপোর্টাররা তাঁদের কম্পিউটারের পর্দায় একটি টেবিলের চারপাশে বক্স আঁকতে পারেন যেন তাঁরা যে ডেটা চান, তা সংগ্রহ করতে পারেন এবং এটি বর্ডারহীন টেবিলসহ অন্যান্য টেবিল স্বয়ংক্রিয়ভাবে সনাক্ত করতে পারে। তিনি বলেছিলেন, ট্যাবুলার জন্য “সক্রিয়” বা ওসিআর করা নথি প্রয়োজন হলেও টুলটি টেসের্যাক্টের তৈরি টেক্সট ফাইলগুলোতে ভালো কাজ করে। তিনি বলেন, “এটিও অফলাইন, তাই খুব গোপনীয়তার সঙ্গে ব্যবহার করা যায়।”
আরও পড়ুন
ডিগিং আপ হিডেন ডেটা উইথ দ্য ওয়েব ইন্সপেকটর
হোয়াই ওয়েব স্ক্র্যাপিং ইজ ভাইটাল টু ডেমোক্রেসি
টিপস ফর বিল্ডিং এ ডেটাবেজ ফর ইনভেস্টিগেশন
 রোয়ান ফিলিপ জিআইজেএনের প্রতিবেদক। তিনি দক্ষিণ আফ্রিকার সানডে টাইমস পত্রিকার সাবেক প্রধান প্রতিবেদক ছিলেন। বিদেশি প্রতিনিধি হিসেবে বিশ্বের ২৪টির বেশি দেশে সংবাদ, রাজনীতি, দুর্নীতি ও সংঘাত নিয়ে রিপোর্ট করেছেন।
রোয়ান ফিলিপ জিআইজেএনের প্রতিবেদক। তিনি দক্ষিণ আফ্রিকার সানডে টাইমস পত্রিকার সাবেক প্রধান প্রতিবেদক ছিলেন। বিদেশি প্রতিনিধি হিসেবে বিশ্বের ২৪টির বেশি দেশে সংবাদ, রাজনীতি, দুর্নীতি ও সংঘাত নিয়ে রিপোর্ট করেছেন।

সাংবাদিকদের জন্য ক্রিপ্টোকারেন্সি অনুসন্ধান গাইড

টিপশিট: আপনার অনুসন্ধানে কীভাবে সামুদ্রিক ডেটা ব্যবহার করবেন

প্রতিবন্ধীদের নিয়ে অনুসন্ধানের রিপোর্টিং গাইড: সংক্ষিপ্ত সংস্করণ

যুদ্ধাপরাধ ও বেসামরিক ব্যক্তিদের ওপর হামলা নিয়ে অনুসন্ধানের টিপশীট

ডেটা স্টোরিটেলারদের হোয়াটসঅ্যাপ গ্রুপ: যেভাবে ভিজ্যুয়ালাইজেশনে একে অন্যকে সহায়তা করছে

অনুসন্ধানী পডকাস্ট সম্পাদনা করবেন কীভাবে- বিশেষজ্ঞরা দিয়েছেন সেই পরামর্শ

কীটনাশকের সঙ্গে ক্যানসারের সম্পর্ক নিয়ে অনুসন্ধান করতে ইচ্ছুক সাংবাদিকদের জন্য কিছু পরামর্শ
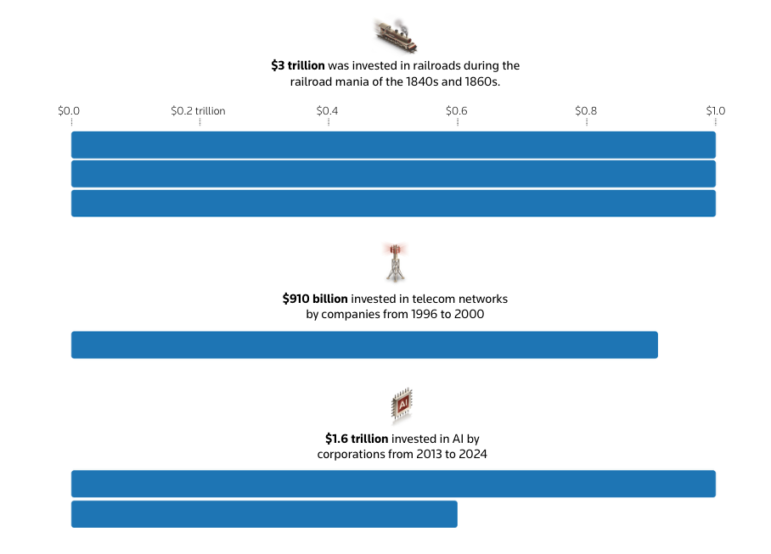
এআই খাতে ট্রিলিয়ন ডলার: রয়টার্স যেভাবে ভিজ্যুয়াল গল্পে এতো বড় ডেটা তুলে ধরেছে

এই লেখা যে লাইসেন্সের অধীনে ক্রিয়েটিভ কমন্স অ্যাট্রিবিউশন-নোডেরিভেটিভস ৪.০ ইন্টারন্যাশনাল লাইসেন্স
ক্রিয়েটিভ কমন্স লাইসেন্সের অধীনে আমাদের লেখা বিনামূল্যে অনলাইন বা প্রিন্টে প্রকাশযোগ্য
লেখাটি পুনঃপ্রকাশ করুন
এই লেখা যে লাইসেন্সের অধীনে ক্রিয়েটিভ কমন্স অ্যাট্রিবিউশন-নোডেরিভেটিভস ৪.০ ইন্টারন্যাশনাল লাইসেন্স
পরবর্তী
ডেটা সাংবাদিকতা
ডেটা স্টোরিটেলারদের হোয়াটসঅ্যাপ গ্রুপ: যেভাবে ভিজ্যুয়ালাইজেশনে একে অন্যকে সহায়তা করছে
বার্তাকক্ষ, বিশ্ববিদ্যালয় কিংবা বিভিন্ন প্রতিষ্ঠানে—তারা ডেটা রিপোর্টিং বা ডেটা ভিজ্যুয়ালাইজেশনের কাজ করতেন। পরস্পরের মতামত বিনিময়, প্রশ্ন করা, কিংবা কাজ করতে গিয়ে একই ধরনের চ্যালেঞ্জের মুখোমুখি হয়েছেন—এমন সহকর্মীদের সঙ্গে পরিচিত হওয়ার মতো কোনো নিদিষ্ট প্লাটফর্ম তাদের ছিল না। সাদামাঠা সেই আলাপ থেকেই শুরু।
পরামর্শ ও টুল
অনুসন্ধানী পডকাস্ট সম্পাদনা করবেন কীভাবে- বিশেষজ্ঞরা দিয়েছেন সেই পরামর্শ
যেসব ঘটনা লিখিত প্রতিবেদনের জন্য ‘পুরোনো’ বা ‘সময়োত্তীর্ণ’ বলে মনে হতে পারে, সেগুলো পডকাস্টের জন্য বরং বাড়তি সুবিধা। প্রচলিত অনুসন্ধানী প্রতিবেদনে সাম্প্রতিক ঘটনাকে বেশি গুরুত্ব দেওয়া হলেও, অতীতের কোনো ঘটনা বা একটি ঘটনার শুরু নিয়ে করা অনুসন্ধানগুলো পডকাস্টের জন্য বেশ উপযোগী।
পরামর্শ ও টুল
কীটনাশকের সঙ্গে ক্যানসারের সম্পর্ক নিয়ে অনুসন্ধান করতে ইচ্ছুক সাংবাদিকদের জন্য কিছু পরামর্শ
রোগ এবং কীটনাশকের সংস্পর্শের মধ্যে বৈজ্ঞানিকভাবে সরাসরি সম্পর্ক প্রমাণ করা কঠিন হলেও, স্বাস্থ্যবিষয়ক প্রতিবেদনে চারপাশের শক্তিশালী প্রমাণ পাঠকদের কাছে গুরুত্বপূর্ণ ও বিশ্বাসযোগ্য হয়ে ওঠে। পশ্চিমের অনেক দেশে এ বিষয়ে অনুসন্ধান করার জন্য অনলাইনে প্রচুর তথ্য পাওয়া যায়। অনেক ক্ষেত্রেই এসব তথ্য পেতে সরকারি নথি চেয়ে আনুষ্ঠানিক আবেদন করারও প্রয়োজন হয় না।
ডেটা সাংবাদিকতা
এআই খাতে ট্রিলিয়ন ডলার: রয়টার্স যেভাবে ভিজ্যুয়াল গল্পে এতো বড় ডেটা তুলে ধরেছে
সাংবাদিকরা যখন অর্থনৈতিক বিষয় নিয়ে প্রতিবেদন লেখেন, তখন কিন্তু তারা ডেটার ঘাটতি নয় বরং বর্ণনার ক্ষেত্রে সমস্যায় পড়েন। আর তা হচ্ছে, যে মানুষটি কখনও এক ট্রিলিয়ন ডলার চোখে দেখেননি, তাকে কীভাবে বিপুল এই অর্থের পরিমাণ সম্পর্কে ধারণা দেওয়া যায়?