
Kodlama Becerisi Gerektirmeyen Ücretsiz Veri Çekme Araçları
Bu Yazıyı Oku

Tweet Ekran Görüntüsünün Gerçek mi Sahte mi Olduğunu Doğrulamak İçin Basit İpuçları

Çevresel Araştırmalar için Uzaktan Algılama ve Veri Araçları

Bir Sonraki Araştırmanız İçin İnternet Arşivi Wayback Makinesini Kullanmanın İpuçları!

Gazeteciler İçin Kripto Para Araştırma Rehberi

Araştırmacı gazeteciler için en son ipuçlarını ve araçları araştırdığımız GIJN Araç Kutusu‘na tekrar hoş geldiniz. Bu yazıda muhabirlerin belgelerden veri kazımak için kullanabilecekleri üç ücretsiz aracı ve nispeten kolay çözüm yöntemleri keşfedeceğiz. Bu teknikler 2022 Araştırmacı Muhabirler ve Editörler konferansında (IRE22) anlatıldı. Gazeteciler büyük ilgi gösterdi. Muhabirler araştırmaları için ihtiyaç duydukları verileri nihayet elde ettiklerinde, genellikle ikinci bir sorunla karşı karşıya kalırlar: bu verilerin nasıl seçileceği ve çıkarılacağı, böylece e-tablolara aktarılıp nasıl kullanılacağı. Birçok küçük haber odası için manuel giriş, gelişmiş kodlama veya maliyetli ticari OCR (optik karakter tanıma) hizmetleri gerçekçi veri kazıma seçeneği olmayabilir.
![]() Dahası, IRE22’deki birkaç kıdemli gözlemci gazeteci, taranmış belgeler veya “düz” PDF’ler gibi yapılandırılmamış veya “ölü” biçimlerde yayınlanan kamuya açık belgelerin miktarında bir artış görmediklerini, aynı zamanda bazı devlet kurumlarının kasıtlı olarak kullandıklarını kaydetti. Bu formatlar habercililk sürecine yük bindiriyor.
Dahası, IRE22’deki birkaç kıdemli gözlemci gazeteci, taranmış belgeler veya “düz” PDF’ler gibi yapılandırılmamış veya “ölü” biçimlerde yayınlanan kamuya açık belgelerin miktarında bir artış görmediklerini, aynı zamanda bazı devlet kurumlarının kasıtlı olarak kullandıklarını kaydetti. Bu formatlar habercililk sürecine yük bindiriyor.
Son bir meydan okumada, dünya çapındaki birçok ajans, muhabir istenen veriler için web sayfalarını kontrol ederler, bunu tek tek kutuları tablolara kopyalayıp yapıştırırlar ve tam veri setinin sonuna ulaşmak için çok sayıda sekmeyi veya sayfayı manuel olarak tıklamaları gerekir.
Bugün ABD’de araştırmacı gazeteci olan Kenny Jacoby , “Bir ton kamuya açık kayıt talebinde bulunuyorum ve istediğim belge veya verileri istediğim formatta almamın artık son derece nadir olduğunu görüyorum” dedi . “Bazen size belgeyi veren ajans kasıtlı olarak hayatınızı zorlaştırmak istiyormuş gibi görünüyor metni bir PDF’den çıkarırlar veya göndermeden önce tararlar veya veriler sütunsuz ve yapılandırılmamış bir biçimdedir. Bu engeller bizi gerçekten yavaşlatabilir, bu yüzden bunlarla başa çıkmak için araçlara sahip olmak önemlidir.”
Google Pinpoint ve PDF’leri Fethetmek için Yeni Özellikleri
2020’de GIJN, Google Journalist Studio’dan yeni bir AI destekli belge ayrıştırma aracının kullanıma sunulduğunu ilk duyuranlardan biriydi ve şimdi ” Pinpoint ” olarak markalandı. Yeni piyasaya sürülen aracı, çok sayıda belge ve resimde hızla arama yapabilen gelişmiş OCR’ye sahip “turbo şarjlı bir Ctrl-F” işlevi olarak tanımladık. IRE22’deki bir veri oturumunda Jacoby, Pinpoint’in o zamandan beri profesyonel gazeteciler için kolay erişime sahip ücretsiz, dijital bir ana araca dönüştüğünü söyledi, kısmen geliştiricilerinin araştırmacı gazetecilerin girdileri sayesinde.Jacoby, Pinpoint’in veri özelliklerinin artık şunları içerdiğini gösterdi:
- “Fakülte” gibi tek bir anahtar kelime ararsanız, bu kelimeyi yalnızca yüklediğiniz araştırma dosyanızda bulmakla kalmaz, aynı zamanda “öğretmen” veya “kampüs” veya “profesör” gibi ilgili kelimeleri de vurgular. Ayrıca aranan terim için agresif varyasyonları da bulur; Portekizce, İspanyolca, Fransızca ve Lehçe dahil yedi dili destekliyor ve istenmeyen terimleri eksi işaretiyle hariç tutabilir.
- Taranmış veya PDF belgeleri demetleri – hatta elle yazılmış karalama sayfaları – yükleyin ve bunları hızla “canlı”, aranabilir, kopyalanabilir metin belgelerine dönüştürebilir. Yataydan farklı yönlerde çalışan kelimeleri bile okur.
- Araç, yalnızca görüntülerdeki tabelaları veya grafitileri tanıyıp metne dönüştürmekle kalmayacak, aynı zamanda görüntülerin arka planında plaketlerde veya duyuru panolarında fark ettiği uzun küçük metin pasajlarını yeniden üretebilir. (Pinpoint demosu sırasında, yoğun, açılı bir biyografik plaket üzerindeki küçük yazıları tek bir fotoğrafta okuyup işleyebildiğinde gazeteci katılımcılarından sesli bir nefes geldi. Bir NBC Telemundo muhabiri Valezka Gil , “Aman Tanrım! Sen! az önce hayatımı değiştirdim – bana çok zaman kazandıracak.”)
- Jacoby, sesli ve görüntülü deşifre özelliğinin artık o kadar gelişmiş olduğunu ve sesli röportajlarının aranabilir deşifrelerini oluşturmak için Trint veya Otter gibi küçük abonelik ücretleri olan özel deşifre hizmetleri yerine ücretsiz Pinpoint aracını kullandığını söylüyor. “Bu tek özellik, o araçlara benziyor, ancak ücretsiz” dedi. “Trint ve Otter’ın yapmadığı bir şey, kimin konuştuğunu tanımlamaması ve her kişiye bir isim atamaması örneğin ‘Hoparlör 2’ gibi. Ancak konuşmadaki mantıksal kırılmaları ve seslerdeki bükülme noktalarını belirler. Metin transkriptinde bir noktaya tıklayabilirsiniz ve o noktada oynatmaya başlayacaktır.”
Jacoby, Pinpoint’in özelliklerine ücretsiz erişimin artık çok kolay olduğunu ve teknisyenlerinden büyük projeler için ekstra depolama talep edilebileceğini söyledi.”Kullanmak için onay almanız gerekiyor, ancak ben ve karım gazeteci olduğumuz için kaydolduğumuzda neredeyse anında onaylandık” dedi. “Bir iş e-posta adresine ihtiyacınız olabilir, ancak içeri girmek zor değil ve oradaki ekip çok duyarlı.”Dezavantajı? Pinpoint tamamen çevrim içi bir hizmet. “Bu, bir internet bağlantısına ihtiyacınız olduğu ve belgelerinizi bir yerde bir sunucuya yüklediğiniz anlamına gelir ve diyelim ki Google mahkeme celbi aldıysa belgelerinizin teslim edilmesi olasıdır” diye uyardı. “Ayrıca, OCR belgesinin bir kopyasını indirmenize izin vermiyor Pinpoint’te yaşıyor, bu yüzden metni kopyalayıp yapıştırmanız gerekiyor. Ama muhtemelen sektördeki en iyi OCR’ye sahip.”
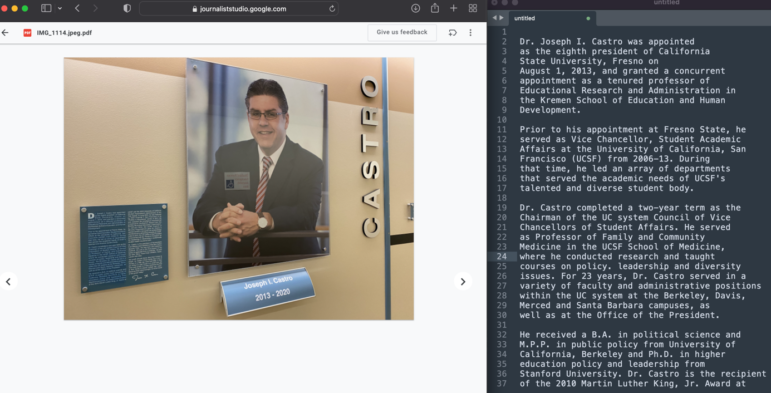 Kenny JacobyIRE22’deki gazeteciler, ücretsiz Google Pinpoint aracının optik karakter tanıma (OCR) özelliğinin, bu fotoğraftaki mavi biyografik plaket üzerindeki yazı kadar küçük metinleri okumak ve kopyalamak için yeterince güçlü olduğunu öğrenince şaşırdılar. Resim: Kenny Jacoby
Kenny JacobyIRE22’deki gazeteciler, ücretsiz Google Pinpoint aracının optik karakter tanıma (OCR) özelliğinin, bu fotoğraftaki mavi biyografik plaket üzerindeki yazı kadar küçük metinleri okumak ve kopyalamak için yeterince güçlü olduğunu öğrenince şaşırdılar. Resim: Kenny Jacoby
Web Sitelerindeki Veriler için ImportHTML/ XML Hack
ProPublica’dan Craig Silverman’ın kısa süre önce GIJN için gösterdiği gibi : Herhangi bir web sitesinin arkasındaki kaynak kodu, araştırmacı gazeteciler için çok sayıda kazma aracı sağlar ve kodlayıcı olmayanlar için ürkütücü görünümüne rağmen “Control-F” veya “Command-” dışında hiçbir beceri gerektirmez. F”, gezinmek için. Google E-Tablolar’da IRE22’de yapılan bir oturumda, serbest gazeteci Samantha Sunne , bu kodun web sitelerindeki uzun tabloları veya belirli veri öğelerini kolayca almak ve saniyeler içinde tüm verilerini ihtiyacınız olan biçimde doldurmak için nasıl kullanılabileceğini gösterdi. Bir elektronik tabloda. Dosyanıza yüzlerce kutuyu tek tek kopyalayıp yapıştırmanıza gerek yok. Teknik, Google E-Tablolar’a ilk, sol üst kutusunda ihtiyacınız olan bir kaynak kod öğesini bir web sayfasından (örneğin, karşıdaki sayfada beğendiğiniz bir veri tablosu oluşturan kod çıkarmak için talimat veren bir formül yazılır. Aslında, herhangi bir sitede iyi biçimlendirilmiş bir veri tablosu çıkarmak için gerçekten herhangi bir koda bakmanız gerekmez. Sadece şu adımları izleyin:
Bir web sayfasından tek bir veri tablosunu içe aktarmak için – ne kadar uzun olursa olsun – aşağıdaki formülü Google E-Tablolar’a yazmanız yeterlidir: =IMPORTHTML(“URL”, “tablo”) Veriler bir liste olarak biçimlendirilmişse, “liste”yi deneyin. ” yerine “tablo” – ve örneğin bir sayfadaki ikinci listeyi istiyorsanız, virgül ve boşluktan sonra 2 rakamını eklemeyi deneyin: =IMPORTHTML(“URL”, “list”, 2)
GIJN, US Federal Deposit Insurance Corp.’un web sitesinden 564 başarısız bankanın bulunduğu bir tabloyu içe aktarmak için bu hack’i denediğinde tüm süreç FDIC URL’sini kopyalamaktan Google E-Tablolar’ı açmaya ve tüm banka listesini mükemmel bir şekilde sütunlar halinde biçimlendirmeye kadar 15 saniyeden az sürdü. Ancak, URL’den sonra bir virgül ve parantez içindeki iki öğenin etrafında tırnak işaretleri dahil olmak üzere formül için gereken tam noktalama işaretlerini kullanmak önemlidir. Dikkat çekici bir şekilde, canlı web sitesi verilerinde yapılan güncellemeler de otomatik olarak Google E-Tablosunda görünecektir – bu nedenle, bu güncelleme işlevini devre dışı bırakmadığınız sürece, araştırmanız sırasında sayfayı sürekli kontrol etmeniz gerekmez.
Yine de Sunne, muhabirlerin html öğelerine en azından biraz aşina olmalarının, bilgisayarların karşılıklı sayfalarda gördüğümüz verileri nasıl paketlediklerini anlamalarının, hatalı biçimlendirilmiş bilgileri işlemeyi kolaylaştırmanın ve daha fazlasını kazmanın önemli olduğunu söyledi. Daha gelişmiş formüllerle daha derine inin.
Herhangi bir sayfayı oluşturan kodu bulmak için sitedeki herhangi bir boş veya beyaz alana sağ tıklayın ve “sayfa kaynağını görüntüle” veya “sayfa kaynağını göster” seçeneğine tıklayın. Genel olarak, hatırlanması gereken önemli nokta, insan odaklı web sayfasında gördüğünüz tüm kelimelerin bilgisayar kaynak kodu sayfasında da görünmesi gerektiğini söyledi, böylece herhangi bir veri terimini bulmak için basitçe “Ctrl-F” yapabilirsiniz.
Kodu, onu yakalamak için hangi öğe etiketlerinin kullanıldığını görün ve formüldeki bu etiketlerle denemeler yapın. Sunne, “Yararlı olsa da, ImportHTML formülü yalnızca tabloları ve listeleri çekebilir ancak başka bir formül, ImportXML, herhangi bir html öğesini çekebilir,” diye açıkladı. “Çok benziyor eşittir işareti; formül adı, URL ancak çok daha spesifik olabilirsiniz.” Bunu nasıl yapacağınız aşağıda açıklanmıştır:
Bir web sayfasındaki belirli veri öğelerini içe aktarmak için – tek tek tablo satırları veya yalnızca kalın metin veya başlıklar gibi – aşağıdaki gibi bir formül deneyin (veri başlıkları örneği için): =IMPORTXML(“URL”, “//h2”) veya bu (tablo satırları için): =IMPORTXML(“URL”, “//table/tr”)
Muhabirlerin html sözlüklerinde bulabileceği “//h2” (başlık) ve “/tr” (tablo satırı) gibi yaygın olarak kullanılan birçok html öğesi vardır ancak Sunne gazetecilerin verileri çevreleyen öğeleri basitçe not etmelerini önerir. İhtiyaç duyarlar ve bir sonraki veri içe aktarmalarını iyileştirmeye yardımcı olabilecek temel bilgisayar jargon etiketlerini tanımlarlar. Pratik yapmak için genellikle birkaç veri listesi ve tablosuna sahip olan büyük Wikipedia sitelerinde bu iki veri kazıma tekniğini kullanmayı deneyin.
Çevrimdışı Verileri Güvenli Bir Şekilde Ayıklamak için ImageMagick ile Tesseract
USA Today’den Kenny Jacoby, Tesseract adlı açık kaynaklı bir OCR motorunun , giriş verilerinin kalitesi yeterince iyiyse, hassas belgeler ve büyük veri arşivleri için harika bir veri çıkarma çözümü sunduğunu söyledi. Dikkat çekici bir şekilde, en son sürümü 100’den fazla dili ve İbranice veya Arapça sağdan sola yazılan metinleri de tanır.
Tesseract, metin katmanı olmayan görüntüleri seçilebilir ve aranabilir PDF’lere dönüştürür ve Jacoby, özellikle büyük toplu “düz” belgeleri canlı, kopyalanabilir metne dönüştürmede güçlü olduğunu söyledi. Bunun genel olarak, muhabirlerin önce PDF belgelerini yüksek çözünürlüklü görüntülere ideal olarak, açık kaynaklı ImageMagick aracını kullanarak dönüştürmesi ve ardından kazınmış verileri elde etmek için bunları Tesseract’a beslemesi gerektiği anlamına geldiğini söyledi.
Jacoby, “OCR’si Pinpoint kadar iyi değil ama oldukça iyi,” dedi. “Ancak büyük bir avantaj, çevrimdışı olması her şeyi yerel olarak, terminalinizde yapabilirsiniz, bu nedenle hassas işler için iyidir. Toplu dönüştürmeler için gerçekten iyidir. 1.000 belgenin her biri için hepsini OCR yapabilirsiniz.”
“Görüntünün kalitesini veya kontrastı artırmanız gerekebilir ancak ImageMagick ile görüntünün kalitesini artırabilirsiniz” diye ekledi. Ayrıca Jacoby, Wall Street Journal araştırmacı muhabiri Chad Day’in Tesseract ve ImageMagick araçları hakkında Github’da bulunabilecek ayrıntılı bir kılavuz önerdi .
Tesseract çözümü bazı “orta” kodlama becerileri gerektirse de Jacoby, bunun komut satırı becerilerine sahip bir kişinin programı tek bir ziyarette kurabileceği ve muhabire iki kısa satır sağlayabileceği tek seferlik bir senaryo olabileceğini söyledi. Daha sonra gelecekteki her veri ayıklaması için ekleyebilecekleri. Jacoby, PDF formatlarında basılmış tabloları çıkarmak için OpenNews ve ProPublica’dan gazeteciler tarafından oluşturulan daha iyi bilinen bir açık kaynak aracı olan Tabula uygulamasını önerdi.
“Aslında veri tablolarını PDF’lerden kurtarıyor ve bunları elektronik tablolara döküyor” diye açıkladı. Tabula, muhabirlerin istedikleri verileri çıkarmak için bilgisayar ekranlarında bir masanın etrafına basitçe bir kutu çizmelerine ve ayrıca kenarlıksız olanlar da dahil olmak üzere tabloları otomatik olarak algılamasına olanak tanır.
Tabula “canlı” veya OCR’lı belgeler gerektirirken, aracın Tesseract tarafından oluşturulan metin dosyalarıyla iyi çalıştığını söyledi. “Ayrıca çevrimdışı, bu yüzden çok özel” dedi.
Ek kaynaklar
Web Denetçisi ile Gizli Verileri Çıkarma
Web Scraping Neden Demokrasi İçin Çok Önemlidir?
Araştırmalar için Veritabanı Oluşturmaya Yönelik İpuçları
 Rowan Philp , GIJN için bir muhabirdir. Eskiden Güney Afrika Sunday Times baş muhabiriydi . Bir dış muhabir olarak, dünya çapında iki düzineden fazla ülkeden haberler, siyaset, yolsuzluk ve çatışmalar hakkında haber yaptı.
Rowan Philp , GIJN için bir muhabirdir. Eskiden Güney Afrika Sunday Times baş muhabiriydi . Bir dış muhabir olarak, dünya çapında iki düzineden fazla ülkeden haberler, siyaset, yolsuzluk ve çatışmalar hakkında haber yaptı.
Tweet Ekran Görüntüsünün Gerçek mi Sahte mi Olduğunu Doğrulamak İçin Basit İpuçları
Çevresel Araştırmalar için Uzaktan Algılama ve Veri Araçları
Bir Sonraki Araştırmanız İçin İnternet Arşivi Wayback Makinesini Kullanmanın İpuçları!
Gazeteciler İçin Kripto Para Araştırma Rehberi

Bu Çalışma Bir Lisans Altında Lisanslanmıştır Creative Commons Atıf-Türevi Olmayan 4.0 Uluslararası Lisansı
İçeriklerimizi bir Creative Commons Lisansı Altında Ücretsiz, Çevrim içi veya Basılı Olarak Yeniden Yayınlayın.
Bu Yazıyı Yeniden Yayınla
Bu Çalışma Bir Lisans Altında Lisanslanmıştır Creative Commons Atıf-Türevi Olmayan 4.0 Uluslararası Lisansı
Sonrakini Oku

Haber Yazım Araçları ve İpuçları Metodoloji
Bir Araştırmayı Mahvedebilecek 10 Basit Veri Hatası
GIJN, 2023 NICAR konferansında birkaç veri gazeteciliği uzmanıyla konuştu ve araştırmanızı mahvedebilecek 10 basit veri gazeteciliği hatasını listeledi.
Haber Yazım Araçları ve İpuçları
PDF’lerden Veri Çıkartmak için ChatGPT Kullanma Potansiyelinin Test Edilmesi!
PDF gibi metin belgelerini elektronik tablolara dönüştürmek sıkıcı ve pahalı bir iştir. Yapay zeka aracı ChatGPT’nin PDF’lerden ne kadar iyi veri çıkarabildiğini görmek için veri gazetecisi Brandon Roberts iki belge setini elektronik tablolara dönüştürmek için bir Python betiği yazdı.

Haber Yazım Araçları ve İpuçları
Favori Araçlarım: Gazeteci Rafael Soares Rio Polisinin İşlediği Cinayetleri Nasıl Araştırıyor?
Brezilyalı gazeteci Rafael Soares, Rio de Janeiro’da polisin görevi kötüye kullanmasını araştırmak için en sevdiği habercilik yöntemlerini ve araçlarını paylaşıyor.

Haber Yazım Araçları ve İpuçları
Matematiksel Hatalardan Kaçınmanın 4 Yolu
Pek çok insan ‘yüzde değişim’ ve ‘yüzde puanlık değişim’ kavramlarını karıştırır. Matematikle ilgili bu ipucu sayfası, veri gazeteciliği öncüsü Jennifer LaFleur’dan içgörüler içeriyor.