
Here’s Why Investigative Reporters Need to Know Knowledge Graphs

Much of the response for a Google search is structured information from Google’s knowledge graph, rather than web links.
In 2012, Google announced that users of its search engine would soon be able to search for “things, not strings” (of text).
In other words, Google would return what is known as structured information about people, places, events, movies, and other concepts, not just the traditional list of web links containing words matching the search terms. This information is drawn from what is known as a knowledge graph.
It’s not just Google. Across the data science community, knowledge graphs have become a growing phenomenon in recent years, driving many applications, including virtual assistants like Siri and Alexa. At the same time, there’s some debate about what actually constitutes a knowledge graph. (They’re a bit of a buzzword.) But one common definition describes a knowledge graph as knowledge bases plus data integration.
Knowledge bases are data sets that have been translated to a common ontology, turning them into a network of things and relationships. The “classics” here are public data from Wikipedia (its knowledge graph is called Wikidata) or domain-specific sites like the movie database IMDb.
Data integration refers to a set of techniques for linking objects together across multiple data sets. Sometimes this is easy, like when two separate data sets mention the same phone number, email address, tax identifier, or international bank account number. Sometimes it’s much harder.
Since OCCRP’s data platform, Aleph, first went online in 2016, it has gone through a transformation similar to Google’s — from “strings” to “things.”
Aleph began as a tool to search text documents, but we soon realized that the data collected for our investigations didn’t fit into that paradigm all the time. A table of payment details, for example, would simply be interpreted as a large gob of words, not the intricate network of people, companies, and transactions that our reporters saw it as, and wanted to analyze further.
In response, we decided to change what Aleph did. Instead of just searching the text in documents, we realized we had to index concepts and how they were connected to each other, so we could produce a knowledge graph that allowed us to consider data in terms of semantics, not just text.
Creating a New Language
To do this, we needed to create an ontology, an abstract language, that mapped out the types of things we were interested in. In the case of IMDb, its users may want to know who was in what movie when, or who that guy in that movie was.
What do investigative reporters care about? The answer to that question, like any other in journalism, can be found at the hotel bar of an industry conference. You’ll hear sentences like: “I have this document that links the prime minister to a company owned by organized crime. Now I need to know if it’s getting contracts from the government.” Later in the evening, a network of suspects might even be sketched out on a cocktail napkin.
These sketches capture the essence of what we do, the nouns and verbs of investigative reporting. Instead of films and directors, we trawl company registries, leaked documents, and sanctions data to learn more about people, companies, contracts, real estate, mining licenses, ships, or email messages, linked by ownership, payments, and family ties. (Sometimes we enjoy movies, too, don’t worry.) Each investigation we conduct might demand the introduction of one or two new nouns, or teach us about new ways they can be connected to each other.
Deciding what nouns and verbs should be captured in software is often a matter of judgement, involving a trade-off between precision and comprehensibility. For example, we do not yet distinguish between companies and trusts. While that decision will make the backs of the entire British legal professional crawl, we simply haven’t seen enough raw data about trusts to justify the distinction on a practical basis.
We’ve called our ontology Follow The Money (FtM) and it underpins every piece of data in the Aleph platform. FtM data, or entities, can be created in many ways. Some are extracted from the contents of a leaked email inbox (people sending, receiving, and responding to messages). Some are sketched as part of a network diagram in Aleph, or, at large scale, generated via a set of annotations from structured data like the table of payments mentioned above.

The OCCRP’s Aleph program uses key nouns, or so-called “things,” in Follow The Money. A second group of entities focuses on describing the verbs, or the links, between these entities. Screenshot
Of course, documents like PDF files, Word documents, and email archives are still an important part of our data collection. But on a technical level, they are merely a type of entity that can be linked to, for example, a company or a government procurement contract.
It’s a Thing, but Is It the Same Thing?
One of the most common tasks for an investigative reporter is to figure out whether one thing is the same as another: is that person receiving cash from an Azerbaijani money laundering scheme really the same guy who is running for president in my country?
A multitude of factors might provide hints that allow us to make that inference. Do they have the same name, birth date, nationality, tax number? Do we know about links to others that also get mentioned in both data sets? Can we find documents from other sources that would solidify this inference? Take, for example, the name “Donald John Trump” — that label could equally refer to the 45th US president (born 1946), or his eldest son (born 1977).

A screenshot of Aleph.
In Aleph we have implemented a simple form of gleaning and compiling these hints: data set cross-reference. The function allows users to treat one data set (let’s say, all the politicians in a given country, or all the companies in a network diagram) as a bulk search against all the other data sets in the system. Matches are scored using all of the candidates’ known properties — names, birth and incorporation dates, nationalities, identifiers, addresses — as ranking criteria.
If you were, through an act of evil magic, to turn one of OCCRP’s investigators into a Python script, I suspect that is the basis for what they would do: find matching fragments of evidence in a multitude of locations, and then patch those together into a compelling narrative.
This is where knowledge graphs are going to intersect with machine learning: techniques like graph embeddings can turn FtM objects into representations that let us compare complex data. And we can learn from the feedback of our reporters to judge what makes a good link between two data sets, and which matches are too weak to be shown to a user.
Once each entity in Aleph is turned into such an embedding (essentially a vector) we can also attempt to do the same thing to the queries sent by our users, so that queries are no longer based on text, but on a comparison of user context and all the dimensions.
Human reporters would also tell you, though, that the standards for what can be reported as a link are incredibly high. They need to ask questions, like ‘Would I stake my reputation on this?,’ or ‘Would this stand up in UK libel court?’ The answer to that question is almost always that you’d need still more data to tell, beyond a reasonable doubt.
This post was originally published on Medium. It is republished here with permission.
 Friedrich Lindenberg is a civic technologist working on effective tools and methods for data-driven journalism and advocacy. He works for the Organized Crime and Corruption Reporting Project and lives between Berlin and Sarajevo.
Friedrich Lindenberg is a civic technologist working on effective tools and methods for data-driven journalism and advocacy. He works for the Organized Crime and Corruption Reporting Project and lives between Berlin and Sarajevo.

GIJC23 – The Future of Data Journalism: New Analytical Tools, Data Visualization, and AI

GIJC23 – The Basics of Using Google Sheets

GIJC23 – Using Pinpoint to Organize Unstructured Data

GIJC23 – Measuring Impact

Mexico Scrapped Its Transparency Agency — Journalists Are Still Investigating Corruption
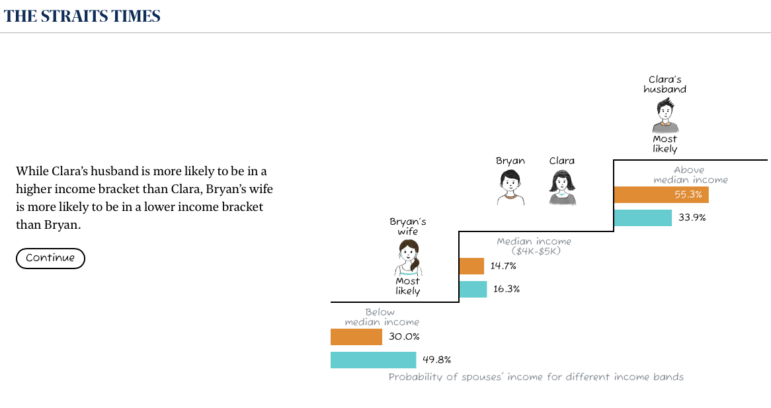
Data Journalism Top 10: Spanish Marital Rates, Gender Income Disparities in Singapore, and Tropical Deforestation
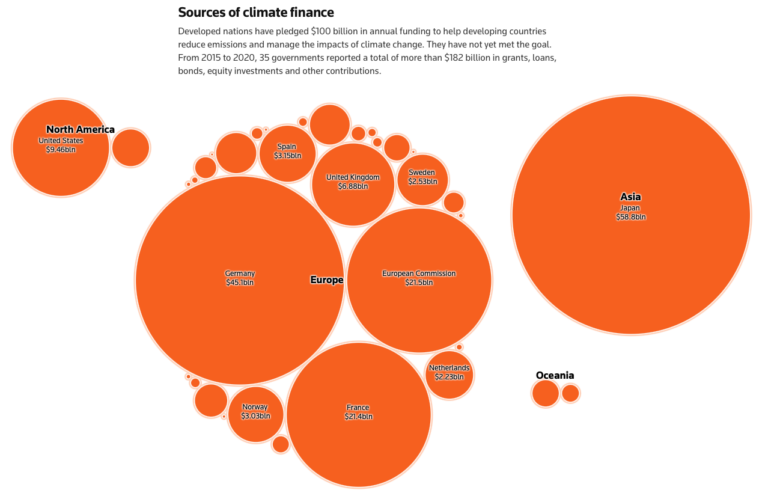
Data Journalism Top 10: Dodgy Climate Finance Deals, Tracking Dark Fleets, and the Rise and Fall of Argentine Kidnappings
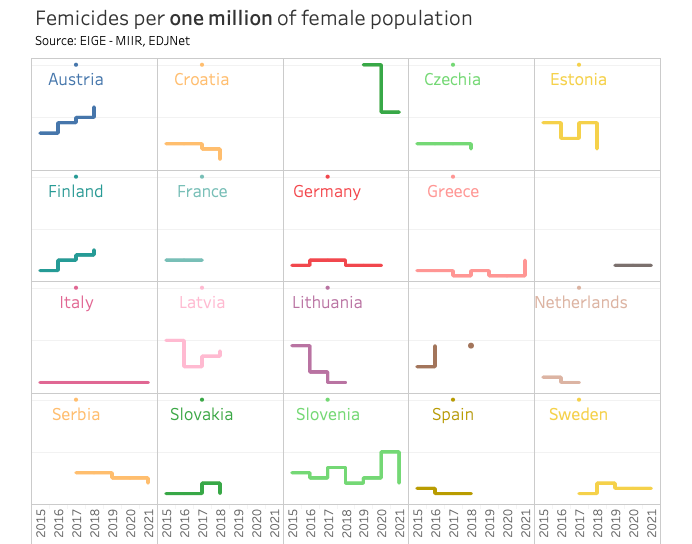
Data Journalism Top 10: Algorithm Bias, Mapping Femicide, India’s Deadly Cold, Bisexual Superman

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
Data Journalism
Mexico Scrapped Its Transparency Agency — Journalists Are Still Investigating Corruption
A year after Mexico dissolved the autonomous body that oversaw government transparency, journalists are still finding ways to access public documents and conduct data-based investigations.
Data Journalism Data Journalism Top 10
Data Journalism Top 10: Spanish Marital Rates, Gender Income Disparities in Singapore, and Tropical Deforestation
This week in GIJN’s Top 10 in Data Journalism, we highlight stories on marital status across Spain, tropical deforestation around the world and, especially, the Amazon, and gender income disparities in Singapore.
Data Journalism Data Journalism Top 10
Data Journalism Top 10: Dodgy Climate Finance Deals, Tracking Dark Fleets, and the Rise and Fall of Argentine Kidnappings
In this week’s Top 10 in Data Journalism, GIJN features a look at dodgy climate finance deals, a hidden fleet of ships moving Russian oil, and the historical rise and fall of ransom kidnappings in Argentina.
Data Journalism Data Journalism Top 10
Data Journalism Top 10: Algorithm Bias, Mapping Femicide, India’s Deadly Cold, Bisexual Superman
GIJN’s weekly round-up of the best in data journalism looks into algorithmic bias in welfare investigations in Rotterdam, mapping the rise of femicides in Europe, and the deadly impact of cold temperatures in India.