
Image: Shutterstock
Questions and Tips to Guide Website Investigations
Read this article in
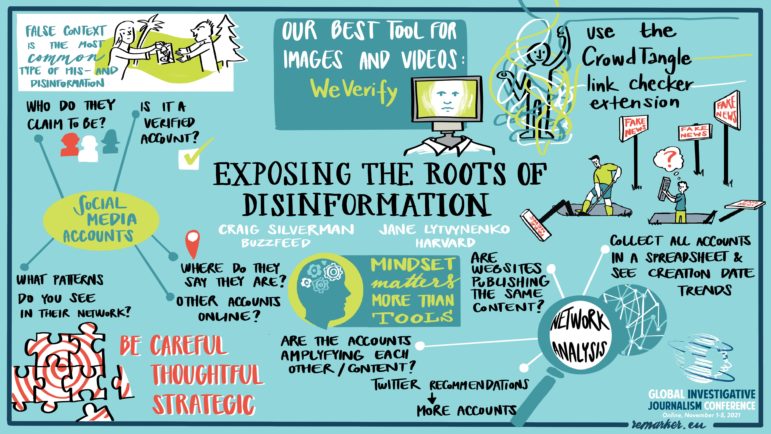


Image: Shutterstock
There are numerous methods for identifying the hidden individuals or organizations behind problematic websites, ranging from simple to highly complex. But successful investigations into anonymous sites that promote hate, scams, or disinformation tend to start with a similar set of questions.
Image: NICAR23
At the recent NICAR23 data journalism conference in Tennessee, a panel on website investigations, comprised of Pri Bengani, senior computational fellow at the Tow Center for Digital Journalism at Columbia University, and Jon Keegan, an investigative data reporter at The Markup, suggested a familiar reporting approach to tackle this often unfamiliar digital terrain. To find “the who” behind a website, they said to start by asking the what, why, when, and how questions around its creation and evolution. Reporters can then experiment with different ways to answer those questions.
Some of these are surprisingly straightforward. For instance, you could just copy-paste a chunk of text from a website’s terms-of-service or “about” page into Google to see if other sites use the same language. Other tactics — like those that require Python coding, or that dig into internet subdomains — can be so complicated that newsrooms need advanced computer science skills. And a few of the best methods seem complicated, but aren’t — like opening the source code of a webpage, and using ‘Control-F’ to easily locate the owner’s unique revenue code, to help you find other sites that use the same code. (See a detailed description of this technique — which uses the greed of bad actors to unmask their identities — by ProPublica’s Craig Silverman in Chapter 1 of GIJN’s Elections Guide for Investigative Reporters.)
An excellent primer to this complex investigative landscape — as well as several useful tools and techniques — was recently provided by Amnesty International Security Lab researcher Etienne Maynier. Earlier this year, he authored a sneak-preview chapter of GIJN’s Guide to Investigating Digital Threats, which will be to be released in full at the 2023 Global Investigative Journalism Conference in Sweden in September.
In general, reporters rely upon four sources for these investigations: on-page content and linked social media; human sources like ex-employees; “Whois” ownership information that was provided when the domain was registered; and the internet infrastructure associated with that domain.
However, the Whois data method has been weakened by several phenomena in the past five years, including Europe’s strict GDPR data privacy rules and many registrants opting to conceal their names and addresses. Still, reporters can often go back in time to when website owners didn’t seek to protect their privacy. As a result, experts suggest reporters dig into historical domain records, using commercial platforms such as DomainTools, Recorded Future, and Cisco Umbrella, or services with free tiers, like Whoxy.com and Whoisology.com.
There are also new tools to dig more deeply into where and how sites are hosted, and into the Domain Name System (DNS) protocol — the so-called “phonebook of the internet.”
Keegan and Bengani also highlighted the power of “passive DNS data” history, and pointed to powerful tools such as DNSDB Scout and RiskIQ, that can map IP addresses to domains, and vice versa. DNSDB is a vast database of passive DNS information that began in 2010 — it “exploits the fact that cyber criminals share and reuse resources” according to its website — and which is freely available to verified journalists who register and obtain an API key to explore it. “This process allows users to find the IP address a specific domain runs on, and then see what other websites live on that IP address,” explained Bengani. “Each of these can then be investigated independently.”
Recent Website-Digging Successes
While most conspiracist “news” sites reshare false stories from other accounts — which makes it easier to map the network with copy-pasted content searches — an increasing number use original disinformation content without true, individual bylines. Keegan pointed to one 2022 investigation into a highly influential, UK-based anti-vax and medical misinformation site as illustrating some useful techniques to track the hidden authors of original content. By simply clicking on the articles’ anonymous staff bylines, he said reporters at the watchdog site Logically found that a partial name for the owner of the site’s WordPress account popped up. An Internet Archive search then revealed the name of the company that originally hosted the page, and a Whois search then revealed the full name of the person who registered that company — a name that matched the partial author name.
“They found data that was probably not intended to be on the site,” said Keegan. “The reporters realized there was a PDF on the site containing a similar name, and saw those initials in the metadata field, and they were able to use that to find his employer. Also, [the site’s owners] were taking donations, which helped — remember, everyone wants to get paid.”
Uncovering secretive, government-backed domains can involve step-by-step progress over many months. Unmasking the WarOnFakes, a fake fact-checking site that appeared days after Russia’s invasion of Ukraine, is a prominent example. First, reporters at German public broadcaster Deutsche Welle used tools like Who.is, the Internet Archive, and ScamAdvisor to find sufficient crumbs — like vast amplification by Russian state media, and a mysterious contact address in Moscow — to flag the site as potential state propaganda, and find links to a cryptocurrency forum. Later, independently, Bengani used tools including RiskIQ and Crowdtangle to find that the site was quickly promoted by influential diplomatic channels, including a Russian consulate in a Chinese province. She said it took a full year before reporters discovered the name of the registered owner.
“This highlights the need to continuously track websites, as opposed to doing one sweep,” said Bengani. “Even if you can’t identify the [website owner], you might at least find its motivation, and clues which can lead you to the next bite.”

Deutsche Welle dug into the WaronFakes.com website for a year before discovering the name of one of its registered owners. Image: Screenshot, Deutsche Welle
Questions to Guide Website Ownership Investigations
- What is the apparent purpose of the site? “Ask: ‘Was it created to make money through ads or scams?’” said Keegan. “To run influence operations? Spread disinformation? Promote a social movement? Does it look like a copycat?” If money looks to be the primary motivation, that’s great news for your investigation. “Because you can then just follow the money,” he explained. “Accepting money or payments greatly increases the chance of identifying the entity.”
- Does it have a newsletter? “Email newsletters are often supposed to list the owners’ addresses,” Bengani noted. “Sign up to their newsletter if one exists.”
- Does the site name pop up on LinkedIn? “Sometimes I’ll search the name of a website I’m looking for in LinkedIn, and sometimes you find someone who worked on one of these sites,” Keegan said. “LinkedIn is great — its algorithm will often suggest other company names that are related — but try to come armed with some company information when reaching out to someone ‘cold.’”
- Is it a WordPress site? And does it use a free WordPress template without any real changes? “If you know it’s a WordPress site, there is a certain structure in the URL you can predict — there is always an author in the URL, and you can do a wildcard search on Google,” said Keegan. “A tool I use all the time is BuiltWith. They have a really great tool for ‘Relationship’ profiles, which will show you any digital forensic markers the URL shares with other domains. The technology tab gives a profile that will tell you, ‘Oh, it’s using WordPress or the Yoast SEO plugin,’ and other things.”
- How has the site changed over time? Try tools like the WayBack Machine and Whois.com. “Try to create a timeline of major changes,” Bengani advised.
- Does the site request payments via PayPal? If so, Keegan suggested a “cool trick,” in which the identity of the site owner can appear during PayPal’s final payment stage. “I was investigating scammy T-shirt companies, and found that when you get right to the button to actually order the thing, it will sometimes pop up a little name for the actual person about to get paid,” he explained.
- Does it use unique Google AdSense or Google Analytics tags? Right-click on any white space on the site in question, click on “page source,” and then type “UA” or “Pub” into Control-F to see if there are any of these tags in the source code. Then search these codes within tools like DNSlytics.com and BuiltWith. “Remember, someone wants to get paid in one place for ads from multiple sites they’re running,” Keegan noted.
- Are there clues or mentions of the time zone associated with the site? This could offer clues to where the owner or page author resides — and whether it is not located where it is claimed to be based.
- Are there portrait images you can investigate? “Images can have metadata that is very revealing,” said Keegan. “Download the photo and open it in your image viewer, and look at the metadata. Sometimes it has information on things like when it was edited, when it was taken — maybe it has GPS if it was a photo taken from a phone, especially on a personal site.”
- Does the site have a Facebook page? While warning that the feature offers “very limited” data, Bengani said Facebook’s Transparency tool can be surprisingly helpful in these investigations. “Facebook Transparency pages are better than nothing,” she said. “They are supposed to show the address and phone number of the organizations that manage the page, and the organizations that ‘partner’ with the page.”
- Is the content published somewhere else? “What we see a lot is the same article shared across multiple websites,” said Bengani. “In some cases it’s search engine spam, in some cases entities are running everything across multiple sites, or stealing data.”
- Was an email address registered with the domain? If so, check if it’s a valid address, and see what accounts are linked to it. Keegan suggested reporters try the Have I Been Pwned service, to check whether emails have been reported in data breaches. You can use the new Epieos reverse email search tool, which can not only confirm if an address exists, but can also find Skype and social media accounts linked to that address. You can also try “guessing” an owner’s address with hunter.io.
“Registering and setting up any online presence — be it a website or a social media account — leaves digital breadcrumbs, which we can follow,” said Bengani. “Sometimes this can lead to the silver bullet, but even in cases that it doesn’t, it should yield ample information that can then be used during further reporting.”
For a list of more advanced techniques for tracking the publishers of anonymous websites, see this checklist on GitHub by Keegan and Bengani.
Additional Resources
Investigating Digital Threats: Digital Infrastructure
Investigating Digital Threats: Trolling Campaigns
Digging Up Hidden Data with the Web Inspector
 Rowan Philp is a reporter for GIJN. Rowan was formerly chief reporter for South Africa’s Sunday Times. As a foreign correspondent, he has reported on news, politics, corruption, and conflict from more than two dozen countries around the world.
Rowan Philp is a reporter for GIJN. Rowan was formerly chief reporter for South Africa’s Sunday Times. As a foreign correspondent, he has reported on news, politics, corruption, and conflict from more than two dozen countries around the world.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
News & Analysis
GIJN Unveils New Website, Logo Ahead of GIJC23 and 20th Anniversary
After 20 years of existence, it was time for GIJN to revamp both is website and visual identity. Welcome to our new website and new look.

Tipsheet Investigative Techniques Reporting Tools & Tips
4 More Essential Tips for Using the Wayback Machine
Based on an interview with Wayback Machine’s director, Mark Graham, ProPublica’s Craig Silverman shares more essential tips on using it, including how to bulk archive pages, compare changes, and see when elements of a page were archived.

Reporting Tools & Tips
5 Online Search Tools to Make Journalists’ Lives Easier
Internet search expert and author Tara Calishain used JavaScript to create a collection of tools that save time for journalists conducting research. Here, she explains how to use them.

Reporting Tools & Tips
My Favorite Tools 2020: Top Investigative Journalists Tell Us What They’re Using
This year, in our My Favorite Tools series, we asked 12 of the world’s top journalists what their go-to tools are. From VeraCrypt and OnionShare to Aleph and the Wayback Machine, here are GIJN’s favorites.