
डेटा के माध्यम से खोजी रिपोर्टिंग


पत्रकारिता में डेटा का उपयोग कोई नई बात नहीं है। विगत दशकों में इसने लंबा सफर तय किया है। 1960 के दशक में फिलिप मेयर ने ‘डेट्रॉइट फ्री प्रेस‘ में कंप्यूटर के जरिए डेटा प्रोसेसिंग का प्रयोग शुरू किया। उन्होंने रिपोर्टिंग में सामाजिक विज्ञान विधियों का भी उपयोग किया। वर्ष 1973 में अपनी पुस्तक Precision Journalism: A Reporter’s Introduction to Social Science Methods में इसका विवरण प्रस्तुत किया।
बाद में काफी पत्रकारों ने फिलिप मेयर की राह पर चलना शुरू किया। वर्ष 1989 में Investigative Reporters and Editors (आईआरई) ने यूएसए में National Institute for Computer-Assisted Reporting कार्यक्रम शुरू किया। इसे मिसौरी स्कूल ऑफ जर्नलिज्म का सहयोग मिला। पत्रकारों को जांच में डेटा का उपयोग करने तथा डेटा आधारित खोजी खबरें बनाने का प्रशिक्षण मिलने लगा।
इसके बाद इंटरनेट का उपयोग बढ़ा, तो बड़ी मात्रा में डेटा निकलकर सामने आने लगा। पत्रकारों ने रिपोर्टिंग तथा जांच का वर्णन करने के लिए ‘डेटा पत्रकारिता‘ शब्द का उपयोग शुरू किया। इस प्रक्रिया में डेटा एकत्र करना और विश्लेषण एक महत्वपूर्ण हिस्सा है। इसने सार्वजनिक हित की कहानियों की रिपोर्टिंग में काफी मदद की। इसके कारण सिस्टम की खामियों को उजागर करना, पैटर्न को समझना और असामान्य चीजों की पहचान करना भी आसान हुआ।
इसके कारण दुनिया भर में कंप्यूटर की सहायता लेकर डेटा आधारित रिपोर्टिंग का सिलसिला तेज हुआ। ‘इन्वेस्टिगेटिव रिपोर्टर्स एंड एडिटर्स‘ के पूर्व कार्यकारी निदेशक ब्रैंट ह्यूस्टन लिखते हैं– ”दुनिया भर के पत्रकारों ने व्यक्तिगत रूप से अथवा किसी क्षेत्रीय या अंतरराष्ट्रीय संगठन से जुड़कर खोजी रिपोर्टिंग के लिए डेटा पत्रकारिता का उपयोग शुरू किया। दुनिया भर के विश्वविद्यालयों ने डेटा पत्रकारिता पर प्रशिक्षण प्रारंभ किया। ग्लोबल इन्वेस्टिगेटिव जर्नलिज्म नेटवर्क जैसे संगठनों ने भी डेटा पत्रकारिता को आगे बढ़ाया।
जैसा कि पहले बताया गया, फिलिप मेयर ने 60 साल पहले कंप्यूटर के साथ यह प्रयोग शुरू किया था। अब कई बड़ी खोजी रिपोर्टिंग परियोजनाएं सामने आ रही हैं। यह कंप्यूटर के जरिए बड़ी संख्या में रिकॉर्ड को संसाधित करने और डेटा विश्लेषण का परिणाम हैं। लेकिन इसमें पारंपरिक रिपोर्टिंग तकनीक का भी उपयोग हुआ है। जैसे मानव स्रोतों से बात करना, जनता तक पहुंच और जमीन पर रिपोर्टिंग करना। पत्रकारिता के पारंपरिक तरीकों के साथ डेटा पत्रकारिता का मिश्रण करके सार्वजनिक हित की खबरें निकालने के लिए रिकॉर्ड और दस्तावेज़ों का शानदार उपयोग हो रहा है।
डेटा कहां खोजें
डेटा हर जगह उपलब्ध है। प्रौद्योगिकी में तेज प्रगति के कारण अब हम पहले से कहीं अधिक जानकारी का संग्रह करके उन्हें संसाधित (प्रोसेसिंग) कर सकते हैं। कोई डेटा एकत्रित रूप में या विस्तृत रूप में आ सकता है। पत्रकार विस्तृत डेटा पसंद करते हैं ताकि सभी पहलुओं से विश्लेषण कर सकें। लेकिन हमेशा ऐसा डेटा मिलना संभव नहीं होता।
कई देशों में डेटा को सार्वजनिक किया जाता है। शुरूआत के लिए यहां कुछ स्रोत दिए गए हैं –
- व्यवसाय रजिस्ट्रेशन कार्यालय
- न्यायालय के रिकॉर्ड
- भौतिक संपत्ति रजिस्ट्रेशन कार्यालय
- बौद्धिक संपत्ति रजिस्ट्रेशन कार्यालय
- आधिकारिक राजपत्र (सरकारी गजट, अधिसूचना)
- सरकारी या एनजीओ वेबसाइटों से हटाया गया सार्वजनिक डेटा (ऐसे मामलों में डेटा होस्ट करने वाली कंपनियों की वैधता का पता लगा लें क्योंकि कुछ देशों में स्क्रैप डेटा के उपयोग पर प्रतिबंध या विशेष नियम हैं।)
- खनन अधिकार या खनन पट्टा – विभिन्न देशों में इसकी जानकारी सार्वजनिक है। यहां तक कि कांगो (डीआरसी) (DRC) और बुर्किना फासो जैसे अपारदर्शी देश ऐसी जानकारी प्रकाशित करते हैं।
- सरकारी अधिकारियों और कानून प्रवर्तन एजेंसियों के सोशल मीडिया, वेबसाइटों और आधिकारिक चैनलों पर अपडेट से काफी डेटामिल सकता है। इस लिंक में केन्या की एक प्रेस रिलीज का उदाहरण देखें।
- संयुक्त राष्ट्र संघ जैसे अंतर्राष्ट्रीय संगठनों के डेटा भी महत्वपूर्ण हैं।
कोई संगठन या सरकारी एजेंसी कोई आंकड़ा या सांख्यिकी प्रकाशित करे, तो उससे संबंधित मौलिक डेटा मांगना भी किसी डेटासेट तक पहुंचने का एक तरीका है।
सार्वजनिक रूप से उपलब्ध कुछ डेटा का उदाहरण –
- यूके लैंड रजिस्ट्री (UK Land Registry)
- कार्बन ऑफसेट और क्रेडिट डेटाबेस (Carbon offsets and credits database)
- सीआईटीईएस ट्रेड डेटाबेस (CITES trade database)
- कांगो खनन कडेस्टर (रजिस्ट्री) (Congo Mining Cadastre)
- इसी तरह भारत में भी कई विभाग अपनी वेबसाइट पर डेटा डालते हैं
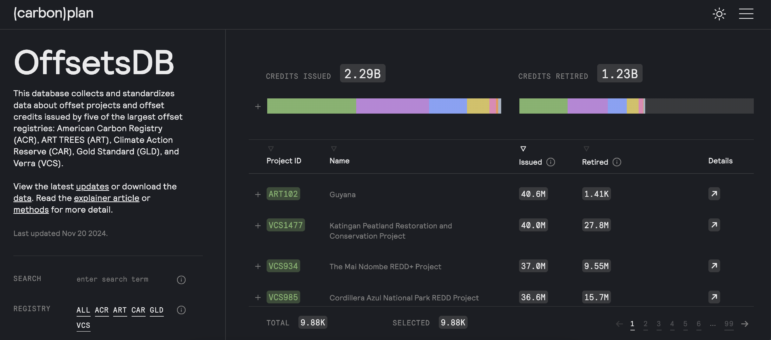
फोटो: कार्बनप्लान के ऑफसेट डेटाबेस को कार्बन ऑफसेट और क्रेडिट की जांच को आसान बनाने और पांच सबसे बड़ी ऑफसेट रजिस्ट्रियों से डेटा जुटाने के लिए डिज़ाइन किया गया था। इमेज : स्क्रीनशॉट, ऑफसेट्सडीबी
डेटा पत्रकारिता की प्रक्रिया
डेटा पत्रकारिता कोई चार्ट और इन्फोग्राफिक्स तैयार करने से कहीं अधिक बड़ा काम है। यह स्प्रेडशीट में संरचित डेटा के साथ काम करने तक सीमित नहीं है। दरअसल जो छिपाया गया है, उसे उजागर करने के लिए डेटा का उपयोग असली काम है। यही लक्ष्य आपको प्रभावशाली रिपोर्टिंग के लिए प्रेरित करेगा।
खबर में डेटा का प्रभावी उपयोग करना चाहते हों, तो पहला काम सही डेटा की तलाश करना है। डेटा खोजने से पहले खुद से पूछें –
- डेटा के स्रोत की प्रकृति क्या है? डेटा कहां मिलेगा? यह किस प्रारूप में होगा?
- डेटासंरचित होगा या असंरचित? सुव्यवस्थित होगा या अव्यवस्थित?
- आपकी कहानी का फोकस क्या है? इसे किस प्रारूप में बताएंगे?
- आपकी टीम की क्षमता क्या है?
- कैसा डेटा उपलब्ध है? यदि कोई डेटा नहीं है, तो इसे कैसे बनाया जा सकता है?
इसके बाद काम शुरू कर दें:
1. डेटा प्राप्त करें – एक बार जब आगे बढ़ाने लायक बातों पर विचार हो जाए, तो अगला कदम डेटा प्राप्त करना है। यह कई तरीकों से मिल सकता है। जैसे दस्तावेज लीक होना, सूचना का अधिकार के तहत मांगना, किसी मानवीय स्रोत से दस्तावेज मिलना इत्यादि। इसके अलावा, प्रोग्रामिंग के जरिए दस्तावेज़ों या वेब पेजों से डेटा स्क्रैप करके भी डेटा निकाला जा सकता है। पीडीएफ और अन्य फोटो दस्तावेज़ों से भी डेटा मिलता है।
डेटा मिल जाए तो उसे संरचित या सुव्यवस्थित डेटा में बदलना पड़ता है। ऐसा करने से विश्लेषण करना आसान होता है। कुछ मामलों में पत्रकारों को खुद अपना डेटासेट बनाना पड़ता है, यदि वह संरचित प्रारूप में मौजूद नहीं है। दस्तावेज़ों या अन्य स्रोतों के माध्यम से ऐसा किया जाता है।
2. डेटा की प्रकृति को समझें – वह डेटा किसने बनाया है? यह समझने का प्रयास करें। डेटा का स्रोत निर्धारित करें। स्रोत की साख को सत्यापित करें। स्रोत की विश्वसनीयता का आकलन करें। डेटा कैसे एकत्रित किया गया, यह जानने के लिए डेटा स्रोत से जुड़े दस्तावेज़ों को पढ़ें। यह चेक करें कि यह प्राथमिक डेटा है, अथवा अन्य स्रोतों से बना द्वितीयक डेटा है। डेटा में क्या है? चरों यानी वेरियेबल्स को समझें। वे क्या दर्शाते हैं? वे कैसे संग्रहित हैं? पता लगाएं कि यह संपूर्ण डेटासेट है या केवल एक भाग है।
इसके बाद, यह समझने का प्रयास करें कि यह डेटा किन प्रश्नों का उत्तर दे सकता है। क्या इसमें कोई कमी है, जिसके लिए अतिरिक्त डेटा स्रोतों की जरूरत होगी? क्या कोई अन्य डेटासेट है जिसे आप मूल सेट को बढ़ाने या उससे तुलना करने के लिए प्राप्त करना चाहेंगे।
3. डेटा का सत्यापन करें – सुनिश्चित करें कि आपको मिला डेटा प्रामाणिक है और इसकी पुष्टि हो सकती है। डेटा को अन्य डेटासेट तथा अन्य दस्तावेज़ों के साथ क्रॉस-रेफ़रेंस करके की जांच करें। विशेषज्ञों से बात करके सत्यापन करें। इसके बाद उस डेटासेट में जिन व्यक्तियों या संस्थाओं का नाम आया है, उनसे संपर्क करें। रिपोर्टिंग प्रक्रिया के दौरान उनकी टिप्पणी लें और उनसे डेटा का सत्यापन करें। डेटा के साथ काम करते समय आपको उसके सटीक, पूर्णता और संगतिपूर्ण होने पर ध्यान देना जरूरी है।
यह जांचना महत्वपूर्ण है कि क्या डेटा में कोई समस्या है? कहीं यह जानकारी अप्रामाणिक, पुरानी या अधूरी तो नहीं। यदि इन चीजों पर ध्यान नहीं दिया, तो आपकी कहानी ताश के पत्तों से बने महल की तरह बिखर सकती है।
4. डेटा का दस्तावेजीकरण करें और सुरक्षित रखें – यदि आप डेटा का पुनर्गठन करते हैं, तो डेटा और अपनी कार्यप्रणाली के बारे में एक रीड-मी फ़ाइल बना लें। इसे निर्देशों का दस्तावेज़ कहा जाता है। डेटा के साथ काम करते समय अपनी प्रक्रियाओं के नोट्स रखें। इससे त्रुटियों को कम करने में मदद मिलेगी। मूल डेटा की एक प्रति सुरक्षित रखें। कोई त्रुटि होने पर मूल दस्तावेज की आवश्यकता होगी। यह भी निर्धारित करें कि डेटा के साथ कौन काम कर रहा है। डेटा की संवेदनशीलता के आधार पर यह तय करें कि डेटा तक कौन पहुंचेगा? इसे कैसे साझा किया जाएगा? डेटा को फ़ोल्डर्स में, गूगल ड्राइव पर, फ्लैश डिस्क के माध्यम से संग्रह कर सकते हैं। यदि इंटरनेट पर स्टोर करने के लिए डेटा संवेदनशील है, तो ऐसी सावधानी जरूरी है।
इसके अलावा, साझा करने योग्य एसक्यूएल डेटाबेस का उपयोग कर सकते हैं। Aleph, Datashare, NINA जैसे उन्नत टूल का उपयोग भी संभव है।
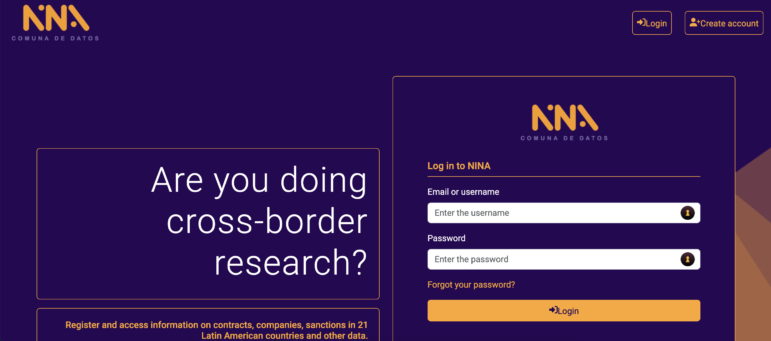
नीना, लैटिन अमेरिकन सेंटर फॉर इन्वेस्टिगेटिव जर्नलिज्म (ईएल क्लिप) का डेटा प्लेटफॉर्म। यह लैटिन अमेरिकी सरकारों द्वारा अनुबंधित कंपनियों और व्यक्तियों के बीच संबंध खोजने के लिए खुले डेटाबेस को जोड़ता है। इमेज : स्क्रीनशॉट, नीना
‘द ओरगेनाइज्ड क्राइम एंड करप्शन रिपोर्टिंग प्रोजेक्ट‘ (ओसीसीआरपी) और ‘इंटरनेशनल कंसोर्टियम ऑफ इंवेस्टिगेटिव जर्नलिस्ट्स‘ (आईसीआईजे) के डेटा देखें। ऐसे संगठन किसी साझेदारी प्रोजेक्ट पर काम करने वाले पत्रकारों की मदद और सुविधा के लिए अपना डेटा साझा करते हैं। इन संगठनों का सख्त प्रोटोकॉल है, जो यह निर्धारित करता है कि डेटासेट तक कौन पहुंच सकता है। स्रोतों और पत्रकारों को जोखिम से बचाने के लिए ऐसे नियम बनाए गए हैं। जो पत्रकार ऐसे डेटा तक पहुंच चाहते हैं, उनके पास डेटासेट को समझने के लिए आवश्यक जानकारी और संदर्भ होना भी जरूरी है। दूसरे शब्दों में कहें तो डेटा केवल उन लोगों के साथ साझा किया जाता है, जो उस तक पहुंच पाने योग्य हैं।
5. अंतर्दृष्टि के लिए डेटा का विश्लेषण करें – एक बार जब आप डेटा को समझकर सहयोगियों के साथ साझा कर लेते हैं, तो यह दिलचस्प खोज का समय है। हमेशा डेटा के साथ वैसा ही व्यवहार करें, जैसा आप मानव स्रोतों के साथ करते हैं। यानी आप डेटा का साक्षात्कार करें। खुद से पूछें कि डेटा किन प्रश्नों का उत्तर दे सकता है? नोट करें कि आप उन उत्तरों तक कैसे पहुँचते हैं। किसी निष्कर्ष या अंतर्दृष्टि पर पहुंचने के लिए उठाए गए कदमों की एक डेटा डायरी रखें। इससे तथ्य-जांच के दौरान आपको मदद मिलेगी। यदि संपादक या वकील आपसे प्रश्न पूछेंगे तो जवाब देना आसान होगा।
- इसके अलावा, बाद में प्रश्नों का उत्तर देने के लिए संदर्भ और प्रतिलिपि प्रस्तुत करने योग्य प्रक्रिया का उपयोग करें। इनमें डेटा को कॉपी-पेस्ट करने के बजाय एक्सेल फ़ार्मुलों का उपयोग करें। प्रोग्रामिंग कोड का उपयोग कर सकते हैं। कार्य पर नज़र रखने के लिए गिटहब रिपॉजिटरी या अन्य तरीकों का उपयोग कर सकते हैं।
- अपने निष्कर्षों को इस तरह रिकॉर्ड करें कि आप और टीम के अन्य सदस्य आसानी से उसका अनुसरण कर सकें। अपनी गणनाओं का संग्रह करने के लिए व्यवस्थित तरीके विकसित करें। स्प्रेडशीट, डैशबोर्ड, पायथन कोड या विकी पेज के माध्यम से यह संभव है।
विश्लेषण के दौरान अन्य डेटासेट के साथ जानकारी को क्रॉस-रेफ़रेंस करना संभव है। एक उदाहरण देखें। आईसीआईजे और 150 से अधिक मीडिया साझेदारों ने राजनेताओं और सार्वजनिक हस्तियों से जुड़े चर्चित पेंडोरा पेपर्स निकाले। इनमें दिखाई देने वाले अपतटीय क्षेत्राधिकारों में पंजीकृत संस्थाओं के साथ क्रॉस-रेफ़रिंग डेटा ने गोपनीय स्वामित्व वाली कई संपत्तियों को उजागर करने में मदद की। इसके लिए यूके, फ्रांस और यूएसए (कैलिफ़ोर्निया, मियामी और अन्य राज्यों) में भूमि रजिस्ट्रियों के डेटा के साथ क्रॉस-रेफ़रिंग की गई।
6. अतिरिक्त रिपोर्टिंग के साथ अपने निष्कर्षों की जांच करें – आपके निष्कर्ष सार्थक हैं, यह सुनिश्चित करने के लिए कि डेटा विश्लेषण को प्रमाणित करना होगा। उपलब्ध नियम कानूनों तथा पिछले शोध और रिपोर्टिंग के आधार पर इनकी समीक्षा करनी होगी। विशेषज्ञों से बात करें। सहकर्मियों के साथ अपने विश्लेषण की जांच करें।
फिर खुद से पूछें –
- क्या डेटा किसी गलत काम को उजागर कर रहा है? जैसे, मनी लॉन्ड्रिंग, भ्रष्टाचार, टैक्स चोरी, पर्यावरण उल्लंघन, कोई अन्य अपराध।
- क्या डेटा की वैधता को लेकर कोई समस्या है?
- क्या डेटा में नई जानकारी शामिल है?
- क्या सिस्टम से जुड़ी किसी समस्या को यह डेटा उजागर करता है?
- क्या डेटा में कोई खास बात है, जो एक महत्वपूर्ण खबर बने?
अंत में, एक बात ध्यान रखें। कहा जाता है कि यदि आप डेटा के साथ मनमानी करते हैं, तो यह कुछ भी कबूल कर लेगा। किसी निष्कर्ष का समर्थन करने के लिए आंकड़ों में हेरफेर न करें।
7. खबर प्रकाशित करने की योजना – अपना विश्लेषण पूरा करने और परिणामों की तथ्य-जांच करने के बाद कहानी लिखने और समीक्षा करने के लिए समय की योजना बनाएं। देख लें कि डेटा सही संदर्भ में प्रस्तुत किया गया है। अन्य जांच कार्यों की तरह एक कानूनी समीक्षा निर्धारित करें। स्टोरी के उत्पादन के लिए समय आवंटित करें। क्या स्टोरी के साथ एक विज़ुअलाइज़ेशन या इंटरैक्टिव प्रकाशित करने की योजना है? अगर हां, उसे भी अपनी योजना में शामिल करें।
डेटा से कहानी तक
एक डेटा स्टोरी का लेखन उसी तरह शुरू हो सकता है, जैसे अन्य कहानियां शुरू होती है। किसी अन्य कहानी, लीक, अथवा अवलोकन रिपोर्टिंग के दौरान सार्वजनिक हित के कुछ मुद्दे भी डेटा के उत्पादन को प्रेरित कर सकते हैं। इन मामलों में डेटा अक्सर कहानियों को संचालित करता है। फिर भी, पारंपरिक रिपोर्टिंग के साथ डेटा रिपोर्टिंग का संयोजन अच्दे परिणाम दे सकता है। लेकिन मानवीय घटक और सार्वजनिक हित को ध्यान में रखना महत्वपूर्ण है। पाठकों को इस स्टोरी में दिलचस्पी क्यों होगी? यह किस प्रणालीगत मुद्दे को उजागर कर रहा है? उस मुद्दे से कौन प्रभावित है?
डेटा से कहानी तक: एक चेकलिस्ट
1. अपनी कहानी के एंगिल को पहचानें। डेटा का विश्लेषण करने के बाद आप निष्कर्षों से उत्साहित हो सकते हैं। आगे बढ़ने के लिए आपके पास कई कोण एंगिल होंगे। पिच के बारे में सोचने से सर्वोत्तम एंगिल चुनने में मदद मिलेगी। यदि आप अब भी निर्णय नहीं कर सके, तो अपने सहकर्मियों या संपादकों से बात करें। ताज़ा विचार के जरिए सर्वोत्तम एंगिल तक पहुंचना, एक नया निर्माण करने और मूल्यवान प्रतिक्रिया पाने में मदद मिल सकती है।
2. स्टोरी बोर्ड बनाना और कहानी योजना
निष्कर्षों को स्टोरीबोर्ड में मैप कर लें। इससे एक अच्छी कहानी के पहलुओं को व्यवस्थित और परिभाषित करने में मदद मिलती है। जैसे- पात्र, संघर्ष, कथानक, संरचना आदि। आपके प्रमुख निष्कर्षों में आकर्षक कहानी क्या है? इसकी पहचान करें।
3. स्टारी की पिच लिखें। यह बताएं कि डेटा आपको कहां ले जा रहा है। इससे संपादक तथा अन्य लोग इसे समझ सकेंगे और संबंधित पेज पर प्रकाशन संभव होगा।
4. डेटा को रिपोर्ट करें। ध्यान रखें कि अच्छी रिपोर्टिंग के जरिए बेहतरीन डेटा स्टोरी हो सकती है। एक उदाहरण देखें। आप सरकार के निवेश पर आधारित आवास निर्माण के लिए अनुबंधित कंपनियों पर रिपोर्ट करना चाहते हैं। आप आवास परियोजनाओं का गहराई से विश्लेषण कर रहे हैं। इसके लिए आप आंकड़ों में बताए गए साइटों पर जाते हैं। लेकिन वहां कोई इमारत नहीं है। यह आपके लिए स्टोरी है। डेटा में क्या बताया गया है, और धरातल पर क्या सच्चाई है, इन दोनों के बीच का फर्क आपके लिए खबर है।
5. कहानी लिखें – डेटा-आधारित कहानियों के लिए सबसे बड़ी चुनौती उसे सुसंगत और आकर्षक बनाना है। स्टोरी के निष्कर्षों को जीवंत बनाने का प्रयास करें। लिखना शुरू करने से पहले कहानी की रूपरेखा या रेखाचित्र बनाना उपयोगी है।
6. डेटा डाउनलोड की सुविधा, स्पष्टीकरण और विज़ुअलाइज़ेशन: प्रकाशन की योजना बनाते समय विचार करें कि कौन-सा डेटा प्रस्तुत करना आवश्यक है। स्टोरी में पूरा डेटा देना संभव नहीं होता। लेकिन जिस विषय पर आपकी स्टोरी है, उसके बारे में पाठकों की समझ को बढ़ाने के लिए सार्वजनिक रूप से आवश्यक डेटा उपलब्ध कराया जा सकता है। इसे एक इंटरैक्टिव ग्राफ़िक के माध्यम से प्रस्तुत कर सकते हैं। संभव हो तो इसके माध्यम से पाठकों को डेटा डाउनलोड करने की सुविधा भी प्रदान करें। जांच की अपनी कार्यप्रणाली की जानकारी देने वाला एक अंश लिखना भी महत्वपूर्ण है। इसमें डेटा की प्रकृति और डेटा के साथ काम कैसे किया गया, इसकी व्याख्या करनी चाहिए। इससे पाठकों को स्टोरी की बेहतर समझ बनेगी।
ध्यान रखें! पाठक कच्चा या रफ डेटा पसंद नहीं करते। इसलिए डेटा को समझने योग्य बनाएं। सावधानी के साथ रचनात्मक तरीके से कहानी सुनाने और दृश्य प्रस्तुति का प्रयास करें।
डेटा कहानियों में डेटा प्रस्तुत करने के लिए आप कई तरीकों से खेल सकते हैं। जैसे, निष्कर्षों को एक ट्वीट या टिकटॉक पोस्ट के रूप में प्रस्तुत किया जा सकता है। इसे एक इन्फोग्राफिक या एक वीडियो के माध्यम से भी प्रस्तुत कर सकते हैं। मीडिया संस्थान अक्सर अपनी प्रिंट या वीडियो स्टोरीज़ के लिए एक से अधिक तरीकों का इस्तेमाल करते हैं। डेटा का विज़ुअलाइज़ेशन रिपोर्टिंग प्रक्रिया में मदद कर सकता है। एक अंतिम उत्पाद भी हो सकता है। अंततः, ग्राफ़िक्स और अन्य टीमों को शीघ्र शामिल करके इस प्रक्रिया में आगे बढ़ें। उन्हें देर से लाने पर डेटा के विज़ुअलाइज़ेशन के लिए उनके पास बहुत कम समय बचेगा।
अन्य विचारणीय पहलू
तथ्यों की जांच कैसे करें?
तथ्य-जांच के लिए भी समय आवंटित करें:
- यदि किसी स्प्रेडशीट में मैन्युअल डेटा है, तो यह जांच जरूरी है कि प्रविष्टियाँ सही ढंग से की गई हैं। यदि संसाधन उपलब्ध हैं, तो अपनी टीम से डेटा प्रविष्टियों की जांच करा लें। डेटा की जटिलता के अनुसार ऐसे सत्यापन के लिए दो या तीन दौर की योजना बना सकते हैं।
- यदि किसी अन्य ने कोई विश्लेषण किया है, तो उसी विश्लेषण को दोहराएं। यह सत्यापन करें कि समान परिणाम प्राप्त हुए हैं। ऐसे विश्लेषण को पुनः करने और तथ्य-जांच में मदद के लिए किसी अन्य व्यक्ति की भूमिका महत्वपूर्ण है।
- विश्लेषण के परिणामों को कहानी में कैसे प्रस्तुत किया गया है, इसकी जांच के लिए भी समय निकालें। क्या उन्हें सही संदर्भ में प्रस्तुत किया गया है? विज़ुअलाइज़ेशन और इंटरैक्टिव की भी जांच करके यह सुनिश्चित करें कि इनमें डेटा विश्लेषण की जानकारी और परिणामों को सही प्रतिबिंबित किया गया है।
ध्यान रखें : डेटा को बुलेटप्रूफ़ करने से अपनी प्रकाशित कहानी को बुलेटप्रूफ़ करने में मदद मिलती है।
डेटा के साथ साझेदारी
सामान्य डेटा स्टोरी पर कोई अकेला पत्रकार काम कर सकता है। लेकिन बड़ी स्टोरी के लिए एक डेटा टीम शामिल हो सकती है। अक्सर ऐसे डेटासेट पर काम करने के लिए डेटा की मात्रा और संगठन के संसाधनों के अनुसार अधिक लोगों की आवश्यकता होगी।
डेटा टीम बनाने में अलग-अलग कौशल के लोगों का मिश्रण हो सकता है। एक ही टीम में अनुसंधान और डेटा विश्लेषण के विशेषज्ञ और डेवलपर्स भी शामिल हो सकते हैं। डेटा अगर बड़े पैमाने पर हो तो इसकी संरचना और प्रारूप में जटिलता होती है। ऐसे मामले में एक अंतर विषय टीम बनाना अच्छा है। इससे काम को आगे बढ़ाने में मदद मिल सकती है। बड़े डेटासेट वाली खोजी परियोजनाओं के लिए बड़ी टीम बनाई जाती है। इसमें पत्रकार, डेटा पत्रकार, शोधकर्ता, तथ्य-जांचकर्ता, ऑनलाइन निर्माता, संपादक और गैर-पत्रकार भी शामिल हो सकते हैं।
ऐसी साझेदारी काफी उपयोगी है। जैसे, यदि आपकी टीम में कोई इंजीनियर हो, तो वह ऐसा उपकरण विकसित कर सकता है, जो पत्रकारों की जांच में मदद करें। लाखों रिकॉर्ड की स्क्रीनिंग के लिए मशीन लर्निंग मॉडल विकसित किया जा सकता है। पत्रकारों की सुविधा के लिए प्रौद्योगिकी का उपयोग करते हुए लाखों रिकॉर्ड को संसाधित करने में मदद करना संभव है। अंतरराष्ट्रीय साझेदारी के द्वारा काफी शक्तिशाली डेटा निकल सकता है। एक साथ काम करते समय यह विभिन्न देशों के पत्रकारों के लिए एक कनेक्टर बन जाता है।
कुछ मामलों में उन बड़े संगठनों के साथ साझेदारी करके सहायता लेना आवश्यक होता है, जिनके पास बड़ी तथा अनुभवी डेटा टीम हो। आईसीआईजे (ICIJ), ओसीसीआरपी (OCCRP), पुलित्जर सेंटर (Pulitzer Center) या लाइटहाउस रिपोर्ट्स (Lighthouse Reports) जैसे संगठनों के साथ काम करना सार्थक हो सकता है। किसी विश्वविद्यालय के कंप्यूटर विज्ञान विभाग के साथ साझेदारी पर भी विचार कर सकते हैं। इन संगठनों के पास सामान्य मीडिया संस्थानों की तुलना में बड़ी डेटा टीमें होती हैं। जबकि संभव है कि किसी मीडिया संस्थान के पास केवल एक या दो डेटा कर्मचारी हो।
साझेदारों तथा अपनी टीम के साथ डेटा साझा करते समय पूरी तरह से पारदर्शी रहें। आपने डेटा कहां से प्राप्त किया, इसका विश्लेषण कैसे किया गया, और डेटा की सीमाएं क्या हैं, यह स्पष्ट बताना सही तरीका है।
अंतर विषय टीमों के साथ काम के दौरान टीमों के बीच समुचित संचार आवश्यक है। यह करें कि परियोजना के लक्ष्यों को समझने और इसे निष्पादित करने के तरीकों को लेकर हर कोई एक ही तरह सोचता है।
उपकरण बॉक्स (टूल बॉक्स)
अगर आप डेटा के मामले में नए हैं, तो इन पाठ्यक्रमों और उपकरणों का समझना उपयोगी होगा:
- स्प्रैडशीट्स में महारत हासिल करें। इसके लिए मार्क होर्विट द्वारा लिखित Basics of Google Sheets देखें। Coursera तथा edX ने एक्सेल के बारे में मुफ्त वीडियो पाठ्यक्रम बनाया है। इनके अलावा, ब्रेंट ह्यूस्टन की स्टोरी पढ़ें- Let the Sheet Do the Math so You Can Focus on the Story ।
- यूरोपीय जर्नलिज्म सेंटर का ‘डेटा जर्नलिज्म हैंडबुक‘ – खंड एक ( 1) और दो ( 2 )।
- Python , R , SQL , Open Refine
- पीडीएफ प्रसंस्करण उपकरण – Tabula , Poppler , pdfplumber/pdfminer
- फ़ाइल प्रसंस्करण, अन्वेषण और साझेदारी उपकरण – Aleph, Datashare , Nina
- कमांड लाइन का उपयोग करें। Missing Semester at MIT से आप कमांड लाइन को समझ सकते हैं। एरिक बैरेट नामक एक सहकर्मी ने यह संसाधन ओसीसीआरपी टीम के साथ साझा किया था, जो कमांड लाइन सीखना चाहते थे।
- कोलंबिया विश्वविद्यालय ने भी डेटा पत्रकारिता संसाधनों का यह सारांश प्रस्तुत किया है। ‘द नाइट सेंटर फॉर जर्नलिज्म इन द अमेरिका, डेटा जर्नलिज्म डॉट कॉम, और आईआरई ने भी पाठ्यक्रम और संसाधन प्रदान किए हैं। इनसे कई टूल और प्रोग्रामिंग भाषाओं का उपयोग समझने में मदद मिलती है।
आप दुनिया के विभिन्न खोजी पत्रकारिता सम्मेलनों में भी प्रशिक्षण प्राप्त कर सकते हैं। जीआईजेएन का जीआईजेसी (GIJC), डेटाहार्वेस्ट (Dataharvest), अफ्रीकन इन्वेस्टिगेटिव जर्नलिज्म कांफ्रेंस (एआईजेसी) ( African Investigative Journalism Conference (AIJC)), लैटिन अमेरिकी कांफ्रेंस कोल्पिन ( COLPIN), एआरआईजे एनुअल फोरम ( ARIJ’s Annual Forum) या आईआरई द्वारा एनआईसीएआर (Nicar by IRE) आदि प्रमुख हैं।
केस स्टडीज
कैप्चर्ड (Captured) – अफ्रीका अनसेंसर्ड
खोजी रिपोर्टिंग की इस श्रृंखला ने केन्या में बड़े पैमाने पर सरकारी भ्रष्टाचार को उजागर किया। सरकारी एजेंसियों में खरीद और संदिग्ध निविदा घोटालों पर रिपोर्ट की। सार्वजनिक खरीद की समीक्षा करके सरकारी अधिकारियों और अन्य हितधारकों भ्रष्ट संबंधों का पता लगाया। ऐसे लोगां ने कंपनियों की एक श्रृंखला के माध्यम से निविदा प्रक्रियाओं में अनुचित लाभ प्राप्त किया।
एजेंट्स ऑफ सिक्रेसी (Agents of Secrecy) – फाइनेंस अनकवर्ड, बीबीसी, सेशेल्स ब्रॉडकास्टिंग कॉर्पोरेशन
यह पत्रकारों की साझेदारी परियोजना पर आधारित खोजी रिपोर्टिंग है। इसमें सार्वजनिक रूप से उपलब्ध यूके कंपनियों के डेटा और हजारों लीक हुए दस्तावेज़ों के डेटा विश्लेषण का उपयोग किया था। इसमें रूस की विभिन्न कॉरपोरेट गोपनीयता एजेंसियों के मास्टरमाइंड और गुर्गों को ट्रैक करने के लिए पूर्व सोवियत संघ में मनी लॉन्ड्रर्स द्वारा यूनाइटेड किंगडम में गुमनाम फर्मों के उपयोग की समीक्षा की गई।
इनसाइड द सस्पीशन मशीन (Inside the Suspicion Machine ) – लाइटहाउस रिपोर्ट्स, वायर्ड, वर्स बेटन, ओपन रॉटरडैम
‘लाइटहाउस रिपोर्ट्स‘ ने दो वर्ष तक एल्गोरिथम जवाबदेही से जुड़े तीन पहलुओं पर जांच की- प्रशिक्षण डेटा, मॉडल फ़ाइल, और एक सरकारी एजेंसी का प्रणाली कोड। इस कोड का उपयोग सरकारी सेवाओं की तलाश करने वाले नागरिकों के लिए जोखिम मूल्यांकन को स्वचालित करने के लिए हो रहा था। ऐसा डेटा निकालने के बाद पत्रकारों ने जोखिम स्कोरिंग एल्गोरिदम का विश्लेषण किया। पाया कि यह लोगों को उनकी मूल भाषा, लिंग और उनके कपड़े पहनने के तरीके के आधार पर कैसे लक्षित कर रहा था।
पेंडोरा पेपर्स (Pandora Papers ) – आईसीआईजे और 150 मीडिया पार्टनर
लगभग दो वर्षों तक पत्रकारों ने 14 अलग-अलग अपतटीय सेवा प्रदाताओं से जुड़े कई प्रारूपों में 11.5 मिलियन से अधिक रिकॉर्डों की छानबीन की। इस आधार पर उनका नाम बताते हुए एक छाया वित्तीय प्रणाली को उजागर करने वाली कहानियां लिखी गईं, जो दुनिया के सबसे अमीर और शक्तिशाली लोगों को लाभ पहुंचाती है। इस जांच में पारंपरिक खोजी रिपोर्टिंग तकनीकों को उन्नत डेटा विश्लेषण के साथ जोड़ा गया। टीम ने दुनिया भर के 600 से अधिक पत्रकारों के साथ फ़ाइलों को सुरक्षित रूप से संसाधित करने और साझा करने के लिए डेटाशेयर का उपयोग किया। डेटा विश्लेषण के लिए विभिन्न उपकरणों और दृष्टिकोणों का उपयोग किया। इनमें शामिल हैं- मशीन लर्निंग, पायथन जैसी प्रोग्रामिंग भाषाएं, मैन्युअल डेटा कार्य और ग्राफ़ डेटाबेस (निओ फॉर जे (neo4j ) ) और लिंकुरियस (Linkurious) )।
 प्यूरिटी मुकामी एक सांख्यिकीविद् से डेटा पत्रकार बनी हैं। सात वर्षों तक उन्होंने अपने डेटा कौशल के साथ फिनसेनफाइल्स, पेंडोरा पेपर्स, एजेंट ऑफ सेक्रेसी और कैप्चर्ड जैसी खोजी कहानियों और परियोजनाओं में योगदान किया। वह अफ्रीका अनसेंसर्ड, बीबीसी अफ्रीका आई, फ़ाइनेंस अनकवर्ड में भी काम कर चुकी हैं। अब ओसीसीआरपी में अफ्रीकी डेटा पत्रकार के रूप में उन्होंने भ्रष्टाचार की जांच, पैसे की जांच, चुनावों के दौरान गलत सूचनाओं पर नज़र रखने वाले संगठनों के साथ साझेदारी की है।
प्यूरिटी मुकामी एक सांख्यिकीविद् से डेटा पत्रकार बनी हैं। सात वर्षों तक उन्होंने अपने डेटा कौशल के साथ फिनसेनफाइल्स, पेंडोरा पेपर्स, एजेंट ऑफ सेक्रेसी और कैप्चर्ड जैसी खोजी कहानियों और परियोजनाओं में योगदान किया। वह अफ्रीका अनसेंसर्ड, बीबीसी अफ्रीका आई, फ़ाइनेंस अनकवर्ड में भी काम कर चुकी हैं। अब ओसीसीआरपी में अफ्रीकी डेटा पत्रकार के रूप में उन्होंने भ्रष्टाचार की जांच, पैसे की जांच, चुनावों के दौरान गलत सूचनाओं पर नज़र रखने वाले संगठनों के साथ साझेदारी की है।
 एमिलिया डिआज़-स्ट्रक जीआईजेएन की कार्यकारी निदेशक हैं। पहले वह इंटरनेशनल कंसोर्टियम ऑफ इन्वेस्टिगेटिव जर्नलिस्ट्स (आईसीआईजे) में डेटा एंड रिसर्च एडिटर तथा लैटिन अमेरिकी समन्वयक थीं। एक दशक से अधिक समय तक वह बीस से अधिक आईसीआईजे पुरस्कार विजेता खोजी साझेदारी में शामिल रहीं। जैसे- ऑफशोर लीक्स, इंप्लांट फाइल्स, फिनसीएन फाइल्स, पेंडोरा पेपर्स और पुलित्जर विजेता पनामा पेपर्स। अपने मूल स्थान वेनेजुएला में डेटा पत्रकारिता और खोजी साझेदारी में वह अग्रणी हैं। उन्होंने सैकड़ों लैटिन अमेरिकी पत्रकारों का मार्गदर्शन किया। उन्होंने कोलंबिया विश्वविद्यालय (न्यूयॉर्क) में डेटा पत्रकारिता और सीमा पार खोजी साझेदारी पर ग्रीष्मकालीन सेमिनारों में पढ़ाया है। वह वेनेजुएला के केंद्रीय विश्वविद्यालय में प्रोफेसर रही हैं। वाशिंगटन पोस्ट, मैगजीन पोडर वाई नेगोसियोस, वेनेजुएला मीडिया एल यूनिवर्सल, एल मुंडो और आरमंडो डॉट इन्फो में योगदानकर्ता रही हैं। वह इसकी सह-संस्थापक भी हैं।
एमिलिया डिआज़-स्ट्रक जीआईजेएन की कार्यकारी निदेशक हैं। पहले वह इंटरनेशनल कंसोर्टियम ऑफ इन्वेस्टिगेटिव जर्नलिस्ट्स (आईसीआईजे) में डेटा एंड रिसर्च एडिटर तथा लैटिन अमेरिकी समन्वयक थीं। एक दशक से अधिक समय तक वह बीस से अधिक आईसीआईजे पुरस्कार विजेता खोजी साझेदारी में शामिल रहीं। जैसे- ऑफशोर लीक्स, इंप्लांट फाइल्स, फिनसीएन फाइल्स, पेंडोरा पेपर्स और पुलित्जर विजेता पनामा पेपर्स। अपने मूल स्थान वेनेजुएला में डेटा पत्रकारिता और खोजी साझेदारी में वह अग्रणी हैं। उन्होंने सैकड़ों लैटिन अमेरिकी पत्रकारों का मार्गदर्शन किया। उन्होंने कोलंबिया विश्वविद्यालय (न्यूयॉर्क) में डेटा पत्रकारिता और सीमा पार खोजी साझेदारी पर ग्रीष्मकालीन सेमिनारों में पढ़ाया है। वह वेनेजुएला के केंद्रीय विश्वविद्यालय में प्रोफेसर रही हैं। वाशिंगटन पोस्ट, मैगजीन पोडर वाई नेगोसियोस, वेनेजुएला मीडिया एल यूनिवर्सल, एल मुंडो और आरमंडो डॉट इन्फो में योगदानकर्ता रही हैं। वह इसकी सह-संस्थापक भी हैं।
अनुवाद: डॉ. विष्णु राजगढ़िया

यह कार्य लाइसेंस के अन्तर्गत है क्रिएटिव कॉमन्स एट्रिब्यूशन-नोडेरिवेटिव्स 4.0 अंतर्राष्ट्रीय लाइसेंस
क्रिएटिव कॉमन्स लाइसेंस के तहत हमारे लेखों को निःशुल्क, ऑनलाइन या प्रिंट माध्यम में पुनः प्रकाशित किया जा सकता है।
आलेख पुनर्प्रकाशित करें
यह कार्य लाइसेंस के अन्तर्गत है क्रिएटिव कॉमन्स एट्रिब्यूशन-नोडेरिवेटिव्स 4.0 अंतर्राष्ट्रीय लाइसेंस
अगला पढ़ें

डेटा पत्रकारिता रिपोर्टिंग टूल्स और टिप्स
गूगल शीट्स का उपयोग कैसे करें पत्रकार
सूचना के अधिकार के जरिए भी काफी डेटा मिलते हैं। इनका विश्लेषण करने में स्प्रेडशीट काफी उपयोगी है। इसे जानना एक महत्वपूर्ण कौशल है। इससे आपको भारी-भरकम डेटा में संभावित खबरें निकालने में मदद मिलती है। स्प्रेडशीट का उपयोग करके आप पाठकों के लायक मनपसंद प्रस्तुति कर सकते हैं।

डेटा पत्रकारिता समाचार और विश्लेषण
भारत में खोजी पत्रकारिता : चुनावी वर्ष में छोटे स्वतंत्र मीडिया संगठनों का बड़ा प्रभाव
भारत में खोजी पत्रकारिता लगभग असंभव होती जा रही है। सरकारी और गैर-सरकारी दोनों प्रकार की ताकतें प्रेस की स्वतंत्रता के प्रति असहिष्णु हो रही हैं। उल्लेखनीय है कि विश्व के 180 देशों के प्रेस स्वतंत्रता सूचकांक में भारत वर्ष 2022 में 150वें स्थान पर था। लेकिन वर्ष 2023 में इससे भी नीचे गिरकर 161वें स्थान पर आ गया।

टिपशीट डेटा पत्रकारिता
‘डेटा माइनर’ के जरिए वेबसाइटों से उपयोगी डेटा कैसे निकालें?
Data Miner डाटा निकालने का एक निःशुल्क उपकरण और ब्राउज़र एक्सटेंशन है। यह आपको वेब पेजों को खंगालने और सुरक्षित डेटा को शीघ्रता से एकत्र करने में सक्षम बनाता है। यह स्वचालित रूप से वेब पेजों से डेटा एकत्र करके एक्सेल, सीएसवी, या जेएसओएन प्रारूपों में सेव करता है।
डेटा पत्रकारिता
डेटा जर्नलिज़्म: पत्रकारों के लिए ‘मानक विचलन’ से सबंधित 4 जरूरी बातें
डेटा के मानकीकरण की प्रक्रिया में प्रत्येक संख्यात्मक डेटा बिंदु को डेटासेट के ‘मानक विचलन’ से विभाजित किया जाता है। ऐसा करने से माप की इकाइयों में परिवर्तन होता है। सामान्य इकाइयों जैसे औंस, इंच, पाउंड या किलोग्राम का उपयोग करके निष्कर्ष बताने के बजाय इन्हें ‘मानक विचलन’ के रूप में रिपोर्ट करना चाहिए।