
Ilustración: Louiza Karageorgiou para GIJN

Guía práctica para periodistas: colaboración con organizaciones de la sociedad civil y organizaciones no gubernamentales

Guía de GIJN para investigar emisiones de metano en vertederos y sus soluciones
Bases de datos de código abierto por país

Guía de fuente abierta para investigar a compañías chinas
Nota editorial: Esta guía es una colaboración entre el equipo de Rendición de Cuentas de IA, del Pulitzer Center, y GIJN. Karen Hao, Laís Martins y Pablo Jiménez Arandia co-desarrollaron algunos de los materiales descritos en este artículo.
En todo el mundo, la inteligencia artificial (IA) se ha convertido en una fuerza que influye en muchos aspectos de la sociedad. La tecnología juega un papel exageradamente importante en muchas economías y tiene implicaciones para los trabajadores intelectuales a nivel global. Los jugadores más poderosos en este campo son un puñado de entidades basadas sobre todo en Estados Unidos, Europa o China. Muchas de ellas son grandes compañías de tecnología que han reunido miles de millones de dólares en inversiones, y están en posición de fijar el tono de cómo se desarrolla y despliega esta tecnología.
Pero la IA también ha generado mucha controversia en cada etapa de su desarrollo, desde su cadena de suministros hasta sus usos. Los centros de datos necesarios para desarrollarla consumen extraordinarias cantidades de agua y energía. Los trabajadores que categorizan los datos que la IA necesita enfrentan bajos salarios y problemas de salud mental. Las tecnologías de IA en sí mismas han demostrado tener sesgos y alucinaciones.
El campo de la IA está repleto de historias para los periodistas de investigación. El propósito de esta guía es ayudar a los reporteros a entender los detalles de la tecnología sobre la que descansa la IA, y darles un marco a través del cual examinarla.
¿Qué es la IA?
Muchas personas piensan en la inteligencia artificial y la relacionan con ChatGPT.
Pero la verdad es mucho más compleja. La inteligencia artificial describe el proceso de usar máquinas para copiar la toma de decisiones humanas y puede pensarse como un término amplio que reúne varias tecnologías.
Los científicos e investigadores comenzaron a usar el término en la década de 1950 y desde entonces han encontrado muchas formas distintas de recrear la inteligencia humana a través de la tecnología.
Uno de los métodos de IA más populares y extendidos hoy en día es el aprendizaje automático y todas las formas que asume, incluyendo sus subconjuntos: el aprendizaje profundo y la IA generativa.
El aprendizaje automático es el proceso de analizar datos para encontrar patrones que nos permiten hacer predicciones o decisiones basadas en esos hallazgos. Estos análisis usan varios métodos matemáticos, desde estadísticas simples a redes neuronales complejas, a menudo dependiendo de la cantidad de datos que se procesan. El resultado de este entrenamiento es un programa de computador, o modelo IA, que puede reunir datos nuevos y hacer predicciones, o generar nueva información con base en estos datos antiguos. Puedes imaginar los productos del aprendizaje automático como una reorganización de datos antiguos. Como un ejemplo de su uso, los modelos de aprendizaje automático simple pueden emplearse por parte de agencias gubernamentales para asignar puntajes de riesgo a quienes podrían recibir ayudas estatales, o a quienes aplican para recibir beneficios de acceso a vivienda.
El aprendizaje profundo es un subconjunto del aprendizaje automático. Requiere de una gran cantidad de entrada de datos, a menudo millones, y usa complejos métodos de análisis, como las redes neuronales. Estas redes, para darle sentido a los datos, usan métodos matemáticos que copian la estructura del cerebro y consisten en nodos interconectados (puedes aprender más aquí sobre redes neuronales). Este tipo de aprendizaje automático a menudo se usa por parte de grandes compañías de tecnología. Lo emplean para predecir términos en motores de búsqueda o sistemas de recomendación para los servicios de streaming.
Luego está la IA generativa que es un subconjunto del aprendizaje automático. Requiere de todavía más datos, y durante su fase de entrenamiento, incluso de más energía y métodos matemáticos para construir sus modelos. La IA generativa se distingue de otros métodos de aprendizaje automático en que no sólo produce recomendaciones para una línea de tiempo o un puntaje predictivo, sino también crea nuevo contenido, como textos o imágenes. Esa es la tecnología que ahora encontramos en los Grandes Modelos de Lenguaje (LLM, por sus siglas en inglés) mediante chatbots como ChatGPT o Gemini, así como apps que crean imágenes a partir de instrucciones de texto, como Midjourney.
El diagrama a continuación presenta todas las versiones del aprendizaje automático.
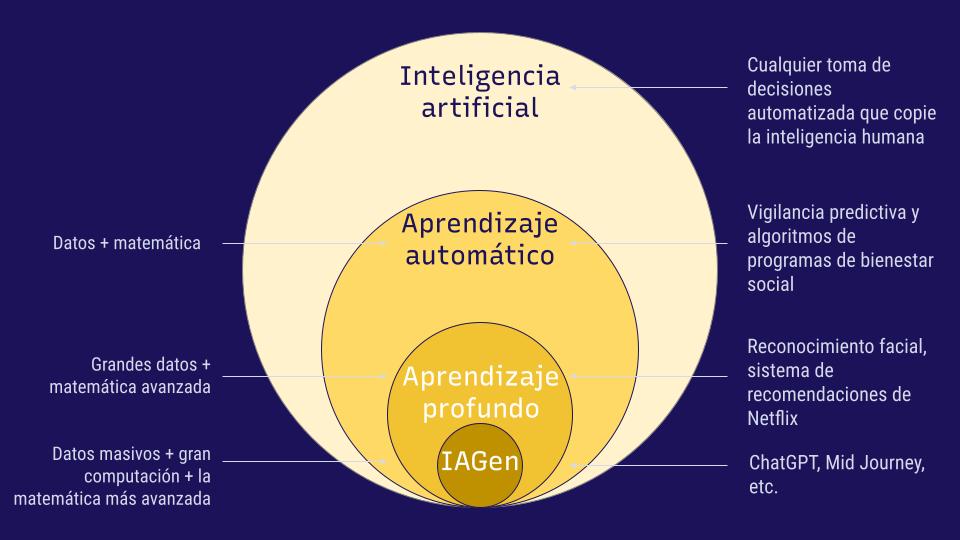
Representación gráfica de la inteligencia artificial y sus subconjuntos, incluyendo el aprendizaje automático, el aprendizaje profundo y la IA generativa. Imagen: Cortesía del Pulitzer Center.
Saber cómo funciona el aprendizaje automático a grandes rasgos les ayuda a los periodistas a hablar sobre el tema, hacer preguntas informadas sobre la tecnología y encontrar formas de acceder mejor a las distintas etapas del desarrollo de la IA para sus reportajes.
Marco de referencia para historias de rendición de cuentas de la IA
Cuando comenzamos a desarrollar la serie AI Spotlight, con Karen Hao, volvíamos sobre una misma pregunta: ¿qué nos habría gustado saber cuando comenzamos a hacer periodismo sobre IA? La respuesta fue un marco para identificar y darle forma a las historias de IA.
La IA cubre una serie amplia de temas y tecnologías, y puede resultar abrumador decidir dónde comenzar. Nuestro marco gira en torno a las cuatro etapas del desarrollo de la IA contemporánea. En la base están las entradas, los datos y la computación que hace posibles los sistemas de hoy. Desde allí, se construyen y entrenan los modelos, formados por datos y decisiones de diseño. Finalmente, estos modelos se aplican en el mundo real. Cada una de estas etapas de desarrollo viene con sus propios temas relacionados, actores involucrados, y personas o estructuras impactadas.
Veremos cada una de estas etapas, discutiendo los conceptos clave y las historias arquetípicas.
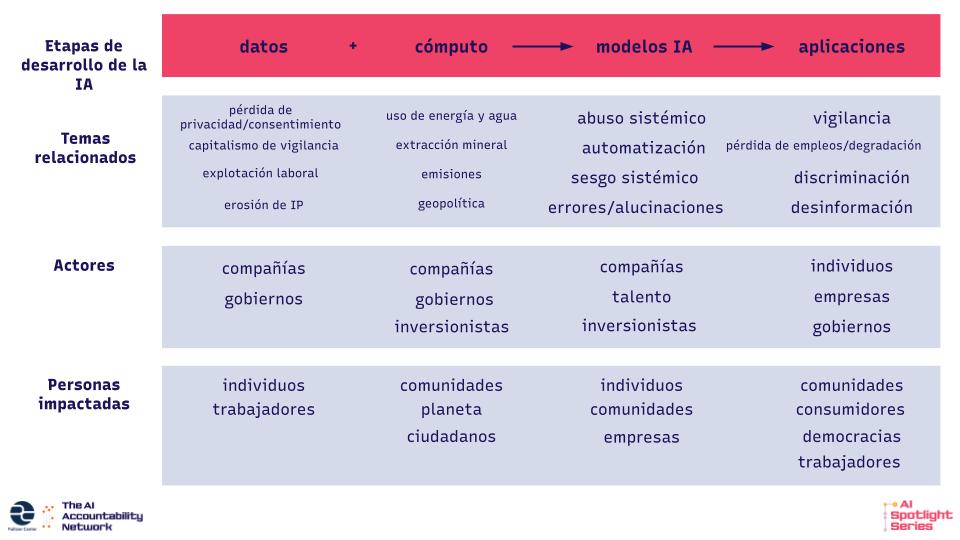
Toma de pantalla: Una representación gráfica del marco para hacer periodismo sobre la rendición de cuentas de la IA. Cortesía del Pulitzer Center
Investigar los datos utilizados
Los modelos IA más simples pueden usar conjuntos de entrenamiento que tienen algunos cientos de puntos de datos, mientras los modelos más complejos, como los LLM, a menudo se entrenan en grandes porciones del internet. Puede ser igualmente amplio el rango de material en los datos de entrenamiento. Pueden asumir la forma de datos estructurados y tabulares, organizados en filas y columnas, o texto sin estructura excavado de plataformas de redes sociales, portales de noticias o foros en línea. Con cada vez más frecuencia se incluyen también imágenes y videos en los entrenamientos.
La mayoría de los reportajes que se centran en la etapa de desarrollo de datos tiende a enfocarse en sistemas más avanzados, que se entrenan en conjuntos masivos de datos y propiedad intelectual. En particular, en cómo el material con derechos de autor o los datos personales terminan en los conductos para el entrenamiento de los modelos de IA. Esta historia de The Atlantic, por ejemplo, observa cómo Meta presuntamente usó miles de libros pirateados para entrenar a Llama, su modelo de IA generativo. Un vocero de Meta no quiso hacer comentarios a los periodistas de The Atlantic, citando un litigio contra la compañía. Otra historia, de The New York Times, halló que las compañías aseguradoras de automóviles están comprando datos de conducción personales de apps aparentemente inocuas para calificar el riesgo de los conductores.
Pero mirar los datos también implica mirar el trabajo humano que permite el uso de estos conjuntos de datos entrenados. Mientras las compañías tienden a presentar su recolección de datos y entrenamiento como procesos altamente automatizados, la realidad es que los conjuntos de entrenamiento a menudo se limpian y categorizan por parte de una subclase de categorizadores de datos, que se hallan predominantemente en el Sur Global, y operan mediante firmas de subcontratistas y plataformas de trabajo digital. Estos trabajadores categorizan imágenes de perros y gatos, que alimentan a clasificadores de imágenes; dibujan cajas alrededor de objetos en las grabaciones de las cámaras de tablero, para entrenar automóviles autónomos; o identifican discursos de odio y contenido violento, para impedir que los LLM lo reproduzcan.
Los reportajes alrededor del mundo han demostrado que los trabajadores de datos están explotados, reciben menos ingresos de los que deberían y a veces se les obliga a lidiar con contenido traumático. Esta investigación del Bureau of Investigative Journalism muestra cómo, alrededor del mundo, los trabajadores de bajos ingresos de economías de plataformas se usan sin que ellos lo sepan en sistemas de reconocimiento facial usados por el gobierno ruso. Otra historia de Africa Uncensored examinó la creciente industria del “tutor IA”, en la que trabajadores altamente educados entrenan chatbots de LLM para producir respuestas de calidad más alta.
Investigar la computación
Una vez los conjuntos de datos de entrenamiento se recogen y limpian, las compañías los usan para entrenar sus modelos de IA. Si bien los modelos simples de IA se pueden entrenar en una fracción de segundo con un portátil de uso personal, los modelos más complejos, como ChatGPT de OpenAI, exigen cantidades masivas de poder de computación. Chips de computadora especializados, que se almacenan de centros de datos, permiten el acceso a dicho poder de computación, que se conoce como “cómputo”.
Los reportajes sobre la etapa de desarrollo del “cómputo” se tiende a enfocar en los impactos ambientales, sociales y económicos de la extensa infraestructura física y su rápida expansión, que impulsa la IA moderna. Cuando desarrollamos por primera vez la serie AI Spotlight, en 2024, los centros de datos aún eran un tema relativamente nuevo en los reportajes. Desde entonces, se ha publicado una rica variedad de ellos en América Latina, Asia, África y los Estados Unidos, que demuestran la enorme cantidad de agua y energía que consumen los centros de datos, así como los esfuerzos corporativos y gubernamentales para esconder estas cifras. En Brasil, por ejemplo, la becaria del Pulitzer Laís Martins halló que un centro de datos de TikTok debía usar tanta electricidad como 2,2 millones de personas. La compañía no respondió a las solicitudes de comentarios de la periodista.
Los reportajes sobre los centros de datos se extienden más allá del impacto ambiental. También examinan cómo los centros de datos afectan el tejido social de las comunidades locales, sus promesas generalmente incumplidas de crecimiento económico y los intensos esfuerzos de lobby a un nivel tanto local como nacional para atraerlos y construirlos. Laís desarrolló una versión ajustada de nuestro marco, enfocada tan sólo en reportar sobre los centros de datos. Puedes encontrarlo a continuación.
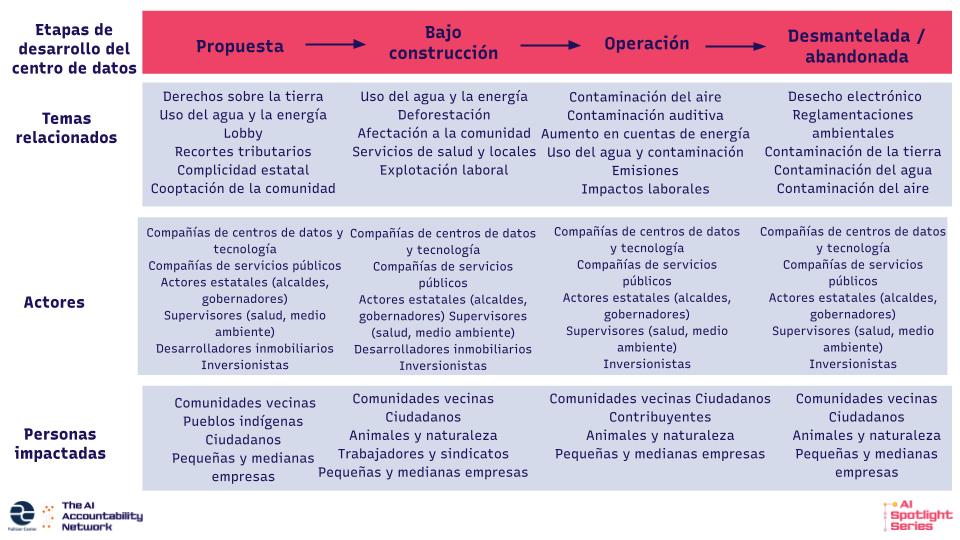
Imagen: Cortesía del Pulitzer Center
Investigar los modelos
La mezcla de datos de entrenamiento y computación produce un modelo IA, un artefacto técnico que hace predicciones, clasifica o, en el caso de la IA generativa, crea nuevo contenido. Al igual que los datos y la computación, los modelos IA varían en complejidad y escala, y van de los sistemas de aprendizaje automático relativamente simples, que se usan para calcular las primas de los seguros médicos, hasta sofisticados sistemas de aprendizaje profundo, capaces de generar imágenes realistas.
Las historias que se enfocan en los modelos IA tienden a centrarse en los temas relacionados con sesgos, errores o los efectos negativos que tiene la automatización sobre las comunidades y las instituciones.
Cuando se puede acceder a cómo los desarrolladores de la IA tomaron ciertas decisiones de diseño, como qué datos de entrenamiento o parámetros se usaron para un modelo, hay investigaciones que pueden profundizar en ellas. Esta investigación de El Confidencial, por ejemplo, obtuvo la fórmula para un sistema de IA que se usa en el sistema carcelario catalán, y que supuestamente predice quién cometería un delito en el futuro. Según los periodistas, el modelo sistemáticamente asignaba un riesgo más alto a ciertos grupos, basado en factores discriminadores o irrelevantes.
Cuando esta información no está disponible, puedes analizar en cambio lo que el modelo arroja. Una historia de Rest of World sistemáticamente analizó 3.000 imágenes producidas por MidJourney IA, una popular herramienta de generación de imágenes, y halló que el sistema reproduce estereotipos crudos sobre diversas culturas. Según los periodistas, la compañía no respondió a sus solicitudes de comentario. Otra investigación, del Philippine Center for Investigative Journalism, hizo ingeniería inversa de lo que arrojaba el algoritmo de Grab, una popular aplicación de transporte, al recoger miles de cotizaciones para sus trayectos. Halló que Grab siempre cobra a los consumidores tarifas adicionales que se supone sólo deben estar presentes durante horas de tráfico pesado. En una respuesta escrita a PCIJ por parte del centro de operaciones de Grab en Filipinas, éste dijo que había “cooperado plenamente con la solicitud del Comité de Regulación de Franquicias de Transporte Terrestre”, al participar en las audiencias.
Investigar las aplicaciones
Por último, es importante que los periodistas investiguen cómo la inteligencia artificial se usa en el mundo real. Cuando la tecnología IA funciona mal, o no como se pretende, pueden verse afectadas muchas personas que están sujetas a decisiones hechas por sistemas automáticos, como algoritmos o aplicaciones de IA generativa.
En una historia del Guardian, la periodista Johana Bhuiyan demostró cómo la excesiva dependencia del gobierno de los Estados Unidos en las aplicaciones de traducción dejó a una persona que buscaba asilo atrapada durante seis meses en un centro de detención de ICE. La aplicación, que se equivocó en idiomas para los que tenía pocos recursos, tradujo mal, y la persona no pudo comunicarse con nadie de forma adecuada. El Departamento de Seguridad Nacional de Estados Unidos no respondió a la periodista del Guardian.
La historia de Hera Rizwan, sobre el uso de reconocimiento facial por parte del gobierno indio, halló que la aplicación que usaban los funcionarios públicos para entregar raciones de alimentos de emergencia no logró reconocer algunas mujeres embarazadas o que estaban amamantando, porque sus rostros habían cambiado con respecto a las imágenes viejas de ellas en las bases de datos gubernamentales. El Ministerio de la Mujer y del Desarrollo del Niño no respondió a las preguntas de Rizwan.
Los reportajes sobre la rendición de cuentas en torno a la IA están al alcance de cualquiera
Como muestran los ejemplos que se han expuesto, nuestro marco de rendición de cuentas puede ayudar a los periodistas a hacer reportajes sobre la IA, de acuerdo con niveles diversos de recursos y esfuerzos técnicos. Las historias pueden ser más cortas o largas, con mayor impacto humano o centradas en aspectos técnicos. Esperamos que estas aproximaciones y ejemplos les ayuden a otros periodistas a encontrar su propia aproximación local a los reportajes sobre la rendición de cuentas en IA.
Recursos
- Algorithmic Literacy for Journalists: un recurso con explicaciones y otros recursos para periodistas.
- AI Spotlight Series Open-Sourced Curriculum: ofrece tutoriales de video, marcos, y diapositivas de la iniciativa del Pulitzer Center para educar a los periodistas del mundo sobre la IA.
- Guía para periodistas sobre cómo detectar contenido generado por IA
- Guía para investigar los algoritmos de las redes sociales
Investigación
- Algorithmic Justice League: una organización que documenta y examina el daño de los algoritmos.
- AI Now Institute: un instituto independiente que publica investigaciones sobre IA y la rendición de cuentas de los algoritmos.
- Center for Democracy and Technology: una organización sin ánimo de lucro que publica informes sobre libertades civiles en la era digital.
- Data and Society: una organización de investigación sin ánimo de lucro enfocada en la tecnología, los datos y las políticas públicas.
- Algorithm Watch: un grupo sin ánimo de lucro con sede en Zurich y Berlín.
- Privacy International: un grupo sin ánimo de lucro con sede en Londres.
- Derechos Digitales: una organización sin ánimo de lucro dedicada a los derechos digitales en América Latina.
- African Digital Rights Network: una organización panafricana sobre derechos digitales.
Gabriel Geiger es un periodista de investigación basado en Atenas, Grecia, especializado en reportajes de rendición de cuentas sobre vigilancia y algoritmos. Actualmente es un periodista de investigación en Lighthouse Reports, una organización sin ánimo de lucro con base en los Países Bajos. Su trabajo ha aparecido en WIRED, Le Monde, Der Spiegel y el Guardian, entre otros.
 Gabriel Geiger es un periodista de investigación basado en Atenas, Grecia, especializado en reportajes de rendición de cuentas sobre vigilancia y algoritmos. Actualmente es un periodista de investigación en Lighthouse Reports, una organización sin ánimo de lucro con base en los Países Bajos. Su trabajo ha aparecido en WIRED, Le Monde, Der Spiegel y el Guardian, entre otros.
Gabriel Geiger es un periodista de investigación basado en Atenas, Grecia, especializado en reportajes de rendición de cuentas sobre vigilancia y algoritmos. Actualmente es un periodista de investigación en Lighthouse Reports, una organización sin ánimo de lucro con base en los Países Bajos. Su trabajo ha aparecido en WIRED, Le Monde, Der Spiegel y el Guardian, entre otros.
 Lam Thuy Vo es una periodista que mezcla el análisis de datos con reportajes en el terreno, para examinar cómo los sistemas y políticas afectan a los individuos. Actualmente es una periodista de investigación que trabaja con Documented, una sala de redacción independiente, sin ánimo de lucro, dedicada a reportar con y para comunidades inmigrantes, y es profesora asociada de periodismo de datos en el Craig Newmark Graduate School of Journalism. Anteriormente, fue periodista en The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America y Planet Money de NPR.
Lam Thuy Vo es una periodista que mezcla el análisis de datos con reportajes en el terreno, para examinar cómo los sistemas y políticas afectan a los individuos. Actualmente es una periodista de investigación que trabaja con Documented, una sala de redacción independiente, sin ánimo de lucro, dedicada a reportar con y para comunidades inmigrantes, y es profesora asociada de periodismo de datos en el Craig Newmark Graduate School of Journalism. Anteriormente, fue periodista en The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America y Planet Money de NPR.
Guía práctica para periodistas: colaboración con organizaciones de la sociedad civil y organizaciones no gubernamentales
Guía de GIJN para investigar emisiones de metano en vertederos y sus soluciones
Bases de datos de código abierto por país
Guía de fuente abierta para investigar a compañías chinas

Consejos para investigar la relación entre pesticidas y cáncer

Cómo verificar un video grabado por un testigo

México eliminó su agencia de transparencia. Periodistas siguen investigando corrupción

Los Premios Sigma 2026 celebran la excelencia del periodismo de datos en diez proyectos internacionales

Esta obra está licenciada bajo un Creative Commons Reconocimiento-Sin Derivadas 4.0 Licencia Internacional
Republica nuestros artículos de forma gratuita, en línea o de manera impresa, bajo una licencia Creative Commons.
Republica este artículo
Esta obra está licenciada bajo un Creative Commons Reconocimiento-Sin Derivadas 4.0 Licencia Internacional
Leer siguiente
Herramientas y consejos para reportear
Consejos para investigar la relación entre pesticidas y cáncer
En la conferencia IRE de 2026, periodistas veteranos compartieron consejos sobre cómo sortear los problemas de causalidad y la jerga toxicológica en las investigaciones basadas en datos sobre la exposición a pesticidas.
Herramientas y consejos para reportear
Cómo verificar un video grabado por un testigo
Desde el tiroteo de Minneapolis hasta el secuestro de Guthrie, las habilidades de investigación visual son ahora imprescindibles. Aquí te explicamos cómo aplicarlas.
Periodismo de datos
México eliminó su agencia de transparencia. Periodistas siguen investigando corrupción
Un año después de que México disolviera el organismo autónomo que supervisaba la transparencia gubernamental, los periodistas siguen encontrando maneras de acceder a documentos públicos y realizar investigaciones basadas en datos.
Periodismo de datos Premios
Los Premios Sigma 2026 celebran la excelencia del periodismo de datos en diez proyectos internacionales
Diez proyectos periodísticos de datos sobresalientes, procedentes de otros tantos países, fueron seleccionados entre los 31 finalistas —26 proyectos individuales y cinco portafolios— por un diverso Comité de Premios compuesto por 17 jueces.