
Підзвітність у сфері ШІ: Посібник для журналістів-розслідувачів. Ілюстрація: Луїза Карагеоргіу для GIJN.
Посібник журналіста із висвітлення відповідального використання ШІ
Read this article in



Примітка редактора: Цей посібник — результат співпраці групи з питань підзвітності у сфері ШІ Пулітцерівського центру та GIJN. Карен Хао, Лаїс Мартінс та Пабло Хіменес Арандія спільно розробили деякі матеріали, описані в цій статті.
Штучний інтелект (ШІ) став найважливішою силою у багатьох галузях життя суспільства. Ця технологія відіграє величезну роль у багатьох економіках і впливає на працівників у сфері інтелектуальної праці в усьому світі. Найбільш впливовими гравцями на цьому ринку є кілька компаній, зокрема зі США, Європи або Китаю, багато з яких — великі приватні технологічні корпорації, що залучили мільярди інвестицій і готові задавати тон у розвитку та впровадженні цієї технології по всьому світу.
Однак, починаючи від ланцюжка постачання і закінчуючи застосуванням, ШІ викликає чимало суперечок. Центри обробки даних, необхідні для розвитку ШІ, споживають неймовірну кількість води та електроенергії. Працівники, які займаються розміткою даних, необхідних для ШІ, стикаються з низькою заробітною платою та проблемами психічного здоров’я. Самі технології ШІ виявилися упередженими та схильними до галюцинацій під час використання.
У сфері штучного інтелекту можна знайти багато історій для журналістських розслідувань. Цей путівник має на меті допомогти журналістам зрозуміти деякі тонкощі технології, що лежить в основі ШІ, та надати їм базові знання для її аналізу.
Що таке ШІ?
Багато хто вперше дізнався про ідею штучного інтелекту завдяки ChatGPT. Тому люди часто сприймають ChatGPT як ШІ, а ШІ просто як ChatGPT.
Але насправді все набагато складніше. Штучний інтелект описує процес використання машин для імітації прийняття рішень людиною, і його швидше слід розглядати як набір різноманітних термінів, що охоплюють низку технологій.
Цей термін був вигаданий вченими та дослідниками у 1950-х роках, і відтоді було винайдено безліч різних способів відтворення людського інтелекту за допомогою технологій.
Одним із найпопулярніших і широко використовуваних методів штучного інтелекту в наші дні є машинне навчання та всі його форми, зокрема, його підвиди — глибоке навчання та генеративний ШІ.
Машинне навчання — це процес аналізу даних для виявлення закономірностей, що дозволяють робити прогнози або ухвалювати рішення з урахуванням отриманих результатів. Для такого аналізу використовують різні математичні методи: від звичайної статистики до складних нейронних мереж, часто залежно від обсягу даних, що обробляються. Результатом навчання є комп’ютерна програма або модель штучного інтелекту, яка може приймати нові дані та робити прогнози чи генерувати нову інформацію на основі цих старих даних. Багато в чому результати машинного навчання можна порівняти з переробкою старих даних. В одному з прикладів використання державні установи можуть застосовувати прості моделі машинного навчання для оцінювання потреб і ризику шахрайства з боку потенційних отримувачів соціальної допомоги або людей, які подають заявки на житлову допомогу.
Глибоке навчання — це підвид машинного навчання, який вимагає більшого обсягу даних, обчислюваних часто мільйонами записів, і використовує для осмислення цих даних складні аналітичні методи, зокрема нейронні мережі, тобто математичні методи, що імітують структуру мозку й складаються з взаємопов’язаних вузлів. (Докладніше про нейронні мережі можна дізнатися тут.) Цей вид машинного навчання часто використовують великі технологічні компанії для прогнозування запитів у пошукових системах або для систем рекомендацій у потокових сервісах.
Генеративний ШІ також є підвидом машинного навчання й вимагає ще більше даних, а на етапі навчання — ще більше енергії та складніших математичних методів для створення своїх моделей. Генеративний ШІ відрізняється від багатьох інших методів машинного навчання тим, що він не просто видає рекомендації для часової шкали або прогнозу, а й створює новий контент у вигляді тексту чи зображень. Саме з цією технологією ми зараз стикаємося у вигляді великих мовних моделей (Large Language Models — LLM), чат-ботів, таких як ChatGPT або Gemini, а також додатків на кшталт Midjourney, які створюють зображення на основі текстових підказок.
Наведена нижче діаграма показує підвиди машинного навчання.
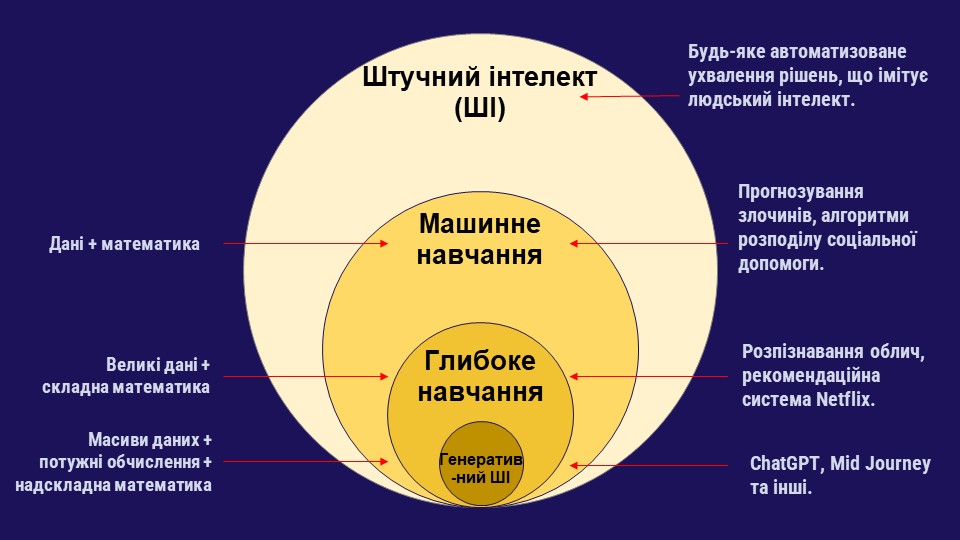
Штучний інтелект та його підвиди, зокрема машинне навчання, глибоке навчання та генеративний ІІ. Зображення: Pulitzer Center (у перекладі редактора GIJN).
Ця графічна схема основних підвидів машинного навчання може допомогти журналістам знаходити способи говорити про нього, ставити обґрунтовані питання щодо технології та більш ефективно пояснювати різні етапи розвитку ШІ у своїх репортажах.
Історії про підзвітність у сфері ШІ
Коли ми разом з Карен Хао тільки починали розробляти серію статей про ШІ, ми постійно поверталися до простого питання: що ми хотіли б знати, коли тільки починали писати про штучний інтелект? Відповіддю стала структура, що дозволяє виявляти й представляти історії про ШІ.
Штучний інтелект як поняття охоплює широкий спектр технологій і проблем, тож розібратися, з чого почати, може бути непросто. Наша концепція ґрунтується на чотирьох етапах розвитку сучасного ШІ. В основі лежать вихідні дані, самі дані та обчислювальні ресурси, що забезпечують функціонування сучасних систем. Потім створюють і навчають моделі, що формуються на основі даних і проєктних рішень. Зрештою, ці моделі застосовують у реальному світі. Кожен із цих етапів розвитку супроводжується низкою пов’язаних із ним проблем, залучених сторін, а також людей чи структур, на яких впливає розвиток ШІ.
Ми розглянемо кожен із цих етапів, обговоримо ключові поняття та сюжети-архетипи.
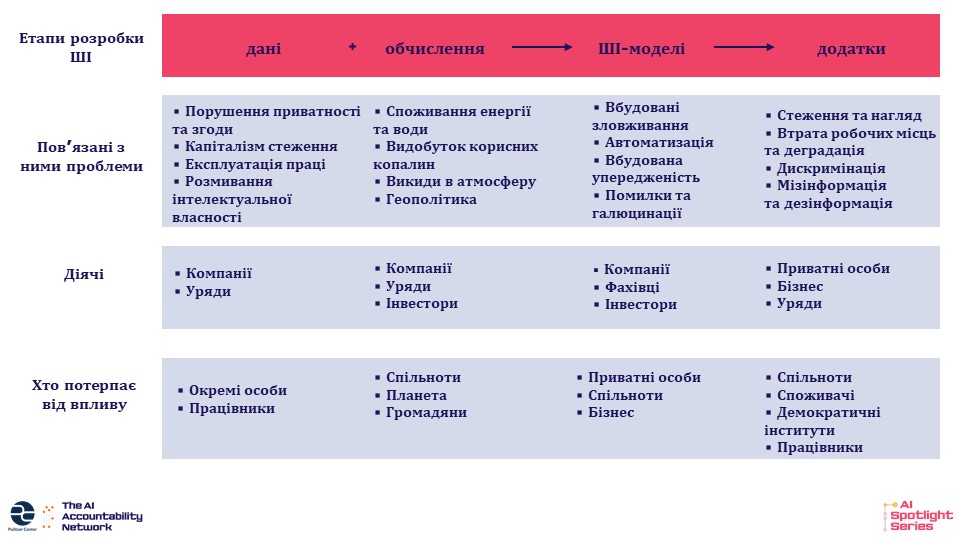
Структура, що дозволяє виявляти та розповідати історії про ШІ. Зображення: Pulitzer Center (у перекладі редактора GIJN)
Вивчення використаних даних
Найпростіші моделі ШІ можуть використовувати для навчання набори даних, що містять кілька сотень точок, водночас, найскладніші, такі як LLM, часто навчають на величезних масивах інтернет-даних. Діапазон матеріалу в навчальних даних може бути настільки ж широким. Він може представляти собою структуровані табличні дані, акуратно організовані в рядки та стовпці, або неструктурований текст, зібраний з платформ соціальних мереж, сайтів новин і онлайн-форумів. Дедалі частіше матеріали також включають зображення та відео.
Більшість розслідувань, присвячених етапу розробки даних, як правило, фокусуються на складніших системах, які навчаються на величезних масивах даних у промислових масштабах. Багато з цих статей присвячені питанням конфіденційності та інтелектуальної власності. Зокрема, репортажі про те, як матеріали, захищені авторським правом, або персональні дані потрапляють до навчальних конвеєрів для моделей ШІ. Наприклад, Atlantic розглядає, як компанія Meta ймовірно використовувала тисячі піратських книг для навчання своєї генеративної моделі ШІ Llama. Представник Meta відмовився відповідати на запитання журналістів Atlantic, пославшись на незавершене судове провадження проти компанії. Стаття The New York Times повідомляє, що страхові компанії купують у, здавалося б, нешкідливих додатків персональні дані про водіння для оцінки ризиків водіїв.
Однак вивчення даних також передбачає аналіз людської праці, яка зробила навчальні набори даних придатними для використання. Хоча компанії, як правило, представляють збір та навчання даних як високоавтоматизований процес, насправді очищенням та класифікацією навчальних наборів часто займаються численні фахівці з розмітки даних, які працюють через аутсорсингові фірми та цифрові платформи для працевлаштування переважно у країнах Глобального Півдня. Ці працівники розмічають зображення кішок і собак, які подаються в класифікатори зображень, обводять рамки навколо об’єктів на відеореєстраторах, які потім використовують для навчання безпілотних автомобілів, або виявляють розпалювання ненависті та насильницький контент, щоб запобігти його відтворенню в навчальних системах.
Репортажі з усього світу показують, що співробітники, які займаються обробкою даних, стають жертвами експлуатації, отримують низьку зарплату й іноді змушені працювати з травмуючим контентом. Розслідування Бюро журналістських розслідувань показує, як низькооплачувані фрілансери по всьому світу, самі того не підозрюючи, допомагають навчати системи розпізнавання осіб, які використовує російський уряд. Матеріал Africa Uncensored присвячений зростаючій «індустрії ШІ-репетиторів», де високоосвічені фахівці навчають чат-ботів давати якісніші відповіді.
Дослідження обчислювальних ресурсів
Після збору та очищення тренувальних наборів даних компанії використовують їх для навчання моделей ШІ. Якщо прості моделі ШІ можна навчити за частки секунди на звичайному ноутбуці, то складніші моделі, зокрема ChatGPT компанії OpenAI, потребують величезних обчислювальних потужностей, які часто називають обчислювальними ресурсами або просто «обчислювачами» («compute»). Зазвичай їхню роботу забезпечують спеціалізовані комп’ютерні чіпи, розміщені у величезних центрах обробки даних.
Висвітлюючи стадії розвитку обчислювальних потужностей, журналісти зазвичай приділяють основну увагу екологічному, соціальному та економічному впливу фізичної інфраструктури, що швидко масштабується й розширюється, забезпечуючи роботу сучасних систем штучного інтелекту. Коли ми вперше підготували серію статей про ШІ у 2024 році, тема центрів обробки даних була ще порівняно новою. З того часу вийшло безліч репортажів з Латинської Америки, Азії, Африки та США, які демонструють, які величезні обсяги енергії та води споживають центри обробки даних, а також викривають спроби корпорацій чи урядів приховати ці цифри. Наприклад, у Бразилії Пулітцерівська стипендіатка Лаїс Мартінс виявила, що центр обробки даних TikTok, схоже, споживав стільки ж електроенергії, скільки 2,2 мільйона людей; компанія не відповіла на запит репортерки.
Репортажі про центри обробки даних виходять за межі простого аналізу впливу на довкілля. Журналісти також розглядають, як центри обробки даних змінюють місцеві спільноти, часто показують невиконані обіцянки економічного зростання та інтенсивні лобістські зусилля на місцевому та національному рівнях щодо залучення та будівництва таких центрів. Мартінс розробила адаптовану версію нашої концепції, сфокусовану виключно на висвітленні центрів обробки даних. Ви можете ознайомитися з нею у таблиці нижче.
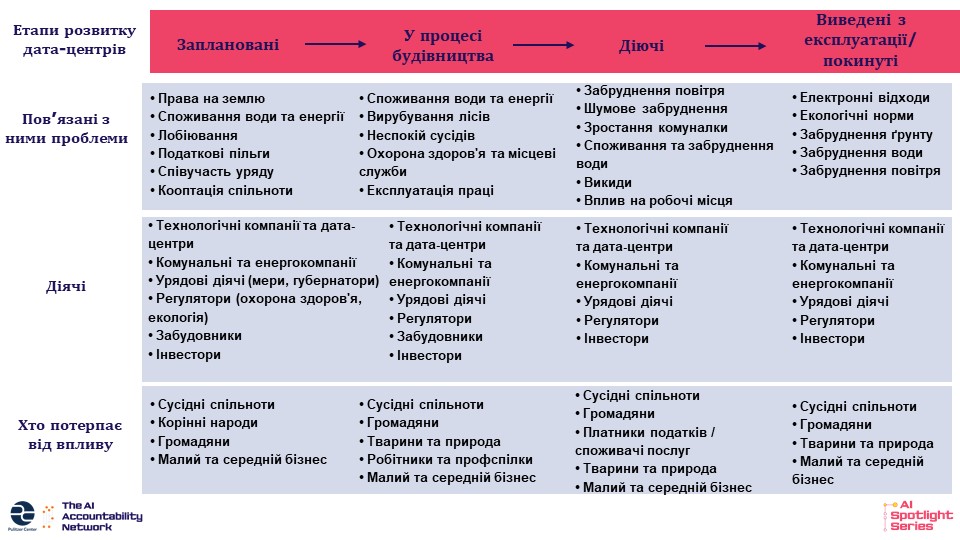
Як розслідувати діяльність центрів обробки даних. Зображення: Pulitzer Center (переклад редактора GIJN).
Дослідження моделей
Поєднання навчальних даних та обчислювальних потужностей дає змогу створити модель штучного інтелекту — технічний артефакт, який робить прогнози, класифікує дані або, у випадку генеративного ШІ, створює новий контент. Так само, як дані та обчислювальні ресурси, моделі ШІ відрізняються за складністю та масштабом: від відносно простих систем машинного навчання, що їх використовують для розрахунку страхових внесків на медичне обслуговування, до вдосконалених систем глибокого навчання, здатних генерувати реалістичні зображення.
Статті, присвячені моделям штучного інтелекту, як правило, порушують питання щодо упередженості, помилок або жахливих наслідків автоматизації для суспільства та інституцій.
Під час таких розслідувань можна ретельно вивчати проєктні рішення, якщо вони доступні, наприклад, навчальні дані або параметри, які використовує модель. Наприклад, El Confidencial під час свого розслідування отримали формулу системи штучного інтелекту, яку використовують в каталонській тюремній системі для прогнозування того, хто вчинить злочин у майбутньому. За словами журналістів, модель систематично ставила вищі бали ризику певним групам на основі дискримінаційних або нерелевантних факторів.
Якщо така інформація недоступна, можна проаналізувати результати роботи моделі. Rest of World провели системний аналіз 3000 зображень, створених популярним інструментом для генерації зображень MidJourney AI, і виявили, що система відтворює грубі стереотипи щодо різних культур. За словами журналістів, компанія не відповіла на їхні запити щодо коментарів. Філіппінський центр журналістських розслідувань (PCIJ) провів зворотне проєктування алгоритму Grab — популярного додатка для замовлення таксі — зібравши інформацію про тисячі викликів від користувачів. Журналісти виявили, що Grab постійно стягував з клієнтів плату за підвищений попит, яка має застосовуватися лише в години пік. У письмовій відповіді PCIJ філіппінський підрозділ Grab заявив, що «повністю співпрацював з розслідуванням [Управління з ліцензування та регулювання наземного транспорту]», беручи участь у слуханнях.
Аналіз додатків
І нарешті, журналісти можуть розслідувати, як штучний інтелект застосовують у реальному світі. Коли технологія ШІ працює не так, як задумано, або дає збої, чимало людей можуть постраждати внаслідок рішень, прийнятих автоматизованими системами, зокрема алгоритмами або програмами генеративного ШІ.
У статті для Guardian репортерка Йохана Бхуян показала, як надмірна залежність уряду США від додатків-перекладачів на базі штучного інтелекту призвела до того, що один шукач притулку шість місяців провів у центрі тримання під вартою ICE. Додаток погано працював з деякими мовами, ресурси для яких були обмежені, і через неправильний переклад людина не могла ні з ким поспілкуватися. Міністерство внутрішньої безпеки США (DHS) не відповіло на запит Guardian.
Хери Різван у репортажі про використання індійським урядом технології розпізнавання облич з’ясував, що додаток, який використовували держпосадвці для надання екстрених продовольчих наборів, не зміг ідентифікувати деяких вагітних або жінок в період лактації, оскільки їхні обличчя відрізнялися від старих зображень, збережених в державних базах даних. Міністерство у справах жінок та дітей не відповіло на запитання Різван.
Висвітлення відповідального використання ШІ доступне кожному
Як показують наведені вище приклади, журналісти можуть висвітлювати тему підзвітності ШІ, маючи різний рівень технічних знань і ресурсів. Історії можуть бути короткими або довгими, переважно орієнтованими на людину чи на технічні тонкощі. Ми сподіваємося, що запропоновані нами схеми, методи та приклади допоможуть іншим журналістам знайти свій власний підхід до висвітлення теми підзвітності у сфері ШІ.
Ресурси
- Алгоритмічна грамотність для журналістів — ресурс із поясненнями та іншими матеріалами.
- Відкрита навчальна програма AI Spotlight Series пропонує відеоуроки, приклади структури та презентації в межах ініціативи Пулітцерівського центру із навчання журналістів з усього світу основам штучного інтелекту.
- Посібник для журналістів із виявлення контенту, створеного за допомогою ШІ (українською).
- Посібник з розслідування алгоритмів соціальних мереж (українською).
Дослідницькі організації
- Algorithmic Justice League — організація, яка документує та досліджує шкоду, завдану алгоритмами.
- AI Now Institute — незалежний інститут, що публікує дослідження в галузі штучного інтелекту та алгоритмічної підзвітності.
- Центр демократії та технологій — некомерційна організація, що публікує звіти про громадянські свободи у цифрову епоху.
- Data and Society — некомерційна дослідницька організація, що спеціалізується на технологіях, даних та політиці.
- Algorithm Watch — некомерційна організація, що базується в Цюріху та Берліні, і вивчає, як алгоритми та штучний інтелект впливають на демократію, справедливість та права людини.
- Privacy International — некомерційна організація, що базується в Лондоні, і вимагає підзвітності інститутів, які руйнують суспільну довіру.
- Derechos Digitales — некомерційна організація захисту цифрових прав, що спеціалізується на Латинській Америці.
- African Digital Rights Network — панафриканська організація захисту цифрових прав.
 Габріель Гайгер — журналіст-розслідувач з Афін, Греція, що спеціалізується на висвітленні питань стеження та алгоритмічної підзвітності. Зараз він працює журналістом-розслідувачем у некомерційній організації Lighthouse Reports, що базується в Нідерландах. Його роботи публікували у WIRED, Le Monde, Der Spiegel, The Guardian та інших виданнях.
Габріель Гайгер — журналіст-розслідувач з Афін, Греція, що спеціалізується на висвітленні питань стеження та алгоритмічної підзвітності. Зараз він працює журналістом-розслідувачем у некомерційній організації Lighthouse Reports, що базується в Нідерландах. Його роботи публікували у WIRED, Le Monde, Der Spiegel, The Guardian та інших виданнях.
 Лем Тхюї Во — журналістка, яка поєднує аналіз даних із репортажами з місць подій, щоб вивчити, як системи та політика впливають на окремих людей. Журналістка-розслідувачка Documented, незалежної некомерційної редакції, що висвітлює події разом з іммігрантськими спільнотами та для них, а також доцентка кафедри журналістики даних у Вищій школі журналістики ім.Крейга Ньюмарка. Раніше вона працювала в The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America та Planet Money на NPR.
Лем Тхюї Во — журналістка, яка поєднує аналіз даних із репортажами з місць подій, щоб вивчити, як системи та політика впливають на окремих людей. Журналістка-розслідувачка Documented, незалежної некомерційної редакції, що висвітлює події разом з іммігрантськими спільнотами та для них, а також доцентка кафедри журналістики даних у Вищій школі журналістики ім.Крейга Ньюмарка. Раніше вона працювала в The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America та Planet Money на NPR.

Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Читати далі

Поради та інструменти Приклади розслідувань
Від друкованих медіа до подкастів: Як журналістам опанувати аудіосторітелінг
Наративні подкасти стали потужним інструментом розслідувальної журналістики. На GIJC25 редактори та продюсери розповіли, як журналісти можуть використати їхній потенціал.

Поради та інструменти Приклади розслідувань
Відстеження олігархів через кордони
Як збирати досьє на олігархів, працювати із корпоративними та санкційними базами даних, а також використовувати витоки інформації та дані «сірого ринку», водночас мінімізуючи юридичні та безпекові ризики. Про це розповіли журналісти з авторитарних країн різних континентів на GIJC25.

Дослідження Методологія Поради та інструменти Приклади розслідувань
Як українські журналісти розслідують воєнні злочини на окупованих територіях
Не маючи доступу до окупованих територій, українські редакції поєднують OSINT, супутникові знімки, перехоплені розмови, дані від джерел в українських правоохоронних органах, свідчення очевидців та збір доказів на місцях після деокупації, щоб задокументувати воєнні злочини й скласти цілісну картину з розрізнених фрагментів інформації.

Поради Поради та інструменти
Information Laundromat: Як працює інструмент для аналізу вмісту та метаданих сайтів
Безкоштовний інструмент Альянсу за безпеку демократії Information Laundromat можна застосовувати для пошуку зачіпок, виявлення зв’язків між сайтами та автоматизації вашого розслідування про поширення фейкових новин та дезінформації.