
Подотчётность в сфере ИИ: Пособие для журналистов. Иллюстрация: Луиза Карагеоргиу для GIJN.
Руководство для журналистов по освещению ответственного использования ИИ
ЧИТАЙТЕ ЭТУ СТАТЬЮ НА ДРУГИХ ЯЗЫКАХ
Примечание редактора: Данное руководство — результат сотрудничества группы по вопросам подотчётности в сфере ИИ Пулитцеровского центра и GIJN. Карен Хао, Лаис Мартинс и Пабло Хименес Арандия совместно разработали некоторые материалы, описанные в этой статье.
Искусственный интеллект (ИИ) стал важнейшей силой во многих сферах жизни общества. Эта технология играет огромную роль во многих экономиках и оказывает влияние на работников интеллектуального труда во всем мире. Наиболее влиятельными игроками на этом рынке являются несколько компаний, в основном из США, Европы или Китая, многие из которых — частные крупные технологические корпорации, привлекшие миллиарды инвестиций и готовые задавать тон в развитии и внедрении этой технологии по всему миру.
Однако, начиная от цепочки поставок и заканчивая применением, ИИ вызывает немало споров. Центры обработки данных, необходимые для развития ИИ, потребляют воду и электроэнергию в невероятных количествах. Работники, занимающиеся разметкой данных, необходимых для ИИ, сталкиваются с низкой заработной платой и проблемами психического здоровья. Сами технологии ИИ оказались предвзятыми и склонными к галлюцинациям при использовании.
В сфере искусственного интеллекта можно найти множество историй для журналистских расследований. Это руководство призвано помочь журналистам понять некоторые тонкости технологии, лежащей в основе ИИ, и предоставить им базовые знания для её анализа.
Что такое ИИ?
Многие впервые познакомились с идеей искусственного интеллекта благодаря ChatGPT. Поэтому люди нередко воспринимают ChatGPT как ИИ, а ИИ — просто как ChatGPT.
Но на самом деле всё гораздо сложнее. Искусственный интеллект описывает процесс использования машин для имитации принятия решений человеком и, скорее, его следует рассматривать как набор самых разных терминов, охватывающих целый ряд технологий.
Этот термин был придуман учёными и исследователями в 1950-х годах, и с тех пор было найдено множество различных способов воссоздания человеческого интеллекта с помощью технологий.
Одним из самых популярных и широко используемых методов искусственного интеллекта в наши дни является машинное обучение и все его формы, включая его подвиды — глубокое обучение и генеративный ИИ.
Машинное обучение — это процесс анализа данных для выявления закономерностей, позволяющих делать прогнозы или принимать решения на основе полученных результатов. Для такого анализа используют различные математические методы, от обыкновенной статистики до сложных нейронных сетей, часто в зависимости от объёма обрабатываемых данных. Результатом обучения является компьютерная программа, или модель искусственного интеллекта, которая может принимать новые данные и делать прогнозы или генерировать новую информацию на основе этих старых данных. Во многом результаты машинного обучения можно представить как переработку старых данных. В одном из примеров использования государственные учреждения могут применять простые модели машинного обучения для оценивания потребностей и риска мошенничества со стороны потенциальных получателей социальной помощи или людей, подающих заявки на жилищные пособия.
Глубокое обучение — это подвид машинного обучения, требующий большего объёма данных, часто исчисляемого миллионами записей, и использующий для осмысления данных сложные аналитические методы, такие как нейронные сети, представляющие собой математические методы, которые имитируют структуру мозга и состоят из взаимосвязанных узлов. (Подробнее о нейронных сетях можно узнать здесь.) Этот вид машинного обучения часто используют крупные технологические компании для прогнозирования запросов в поисковых системах или для систем рекомендаций в потоковых сервисах.
Далее идёт генеративный ИИ, который является подвидом машинного обучения и требует ещё больше данных, а на этапе обучения — ещё больше энергии и сложных математических методов для создания своих моделей. Генеративный ИИ отличается от многих других методов машинного обучения тем, что он не просто выдает рекомендации для временной шкалы или прогноз, но и создаёт новый контент в виде текста или изображений. Именно с этой технологией мы сейчас сталкиваемся в виде больших языковых моделей (Large Language Models — LLM), в виде чат-ботов, таких как ChatGPT или Gemini, а также в приложениях, которые создают изображения на основе текстовых подсказок, таких как Midjourney.
На приведённой ниже диаграмме представлены все варианты машинного обучения.
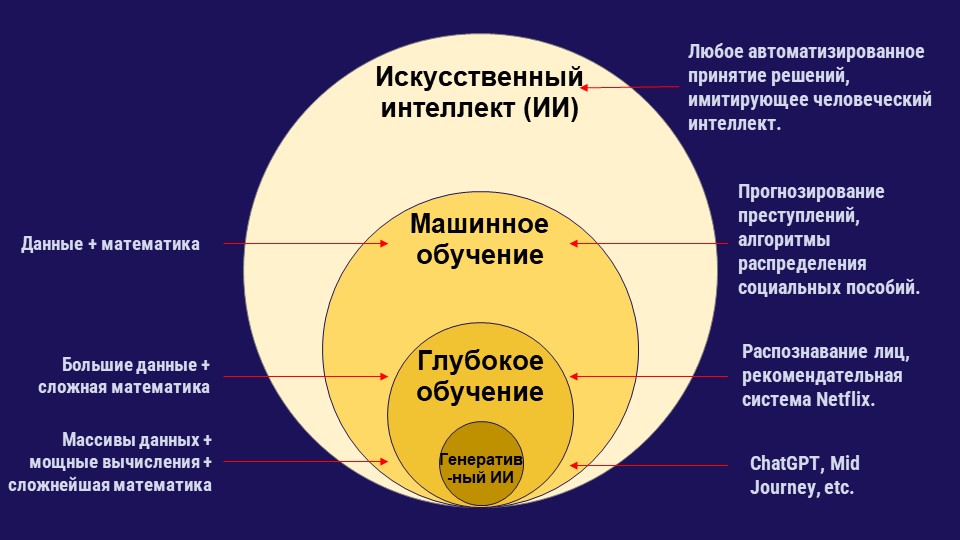
Искусственный интеллект и его подвиды, включая машинное обучение, глубокое обучение и генеративный ИИ. Изображение: Pulitzer Center (в переводе редактора GIJN).
Эта графическая схема основных подвидов машинного обучения может помочь журналистам находить способы говорить о нём, задавать обоснованные вопросы о технологии и эффективнее пояснять различные этапы развития ИИ в своих репортажах.
Истории о подотчётности в сфере ИИ
Когда мы вместе с Карен Хао только начинали разрабатывать серию статей об ИИ, мы постоянно возвращались к простому вопросу: что бы мы хотели знать, когда только начинали писать об ИИ? Ответом стала структура, позволяющая выявлять и представлять истории об ИИ.
Искусственный интеллект как понятие охватывает широкий спектр технологий и проблем, и разобраться, с чего начать, может быть непросто. Наша концепция основана на четырёх этапах развития современного ИИ. В основе лежат исходные данные, сами данные и вычислительные ресурсы, которые делают возможным функционирование современных систем. Затем создаются и обучаются модели, формируемые на основе данных и проектных решений. Наконец, эти модели применяют в реальном мире. Каждый из этих этапов развития сопровождается своим набором связанных с ним проблем, вовлечённых сторон и затронутых людей или структур.
Мы рассмотрим каждый из этих этапов, обсудим ключевые понятия и сюжеты-архетипы.
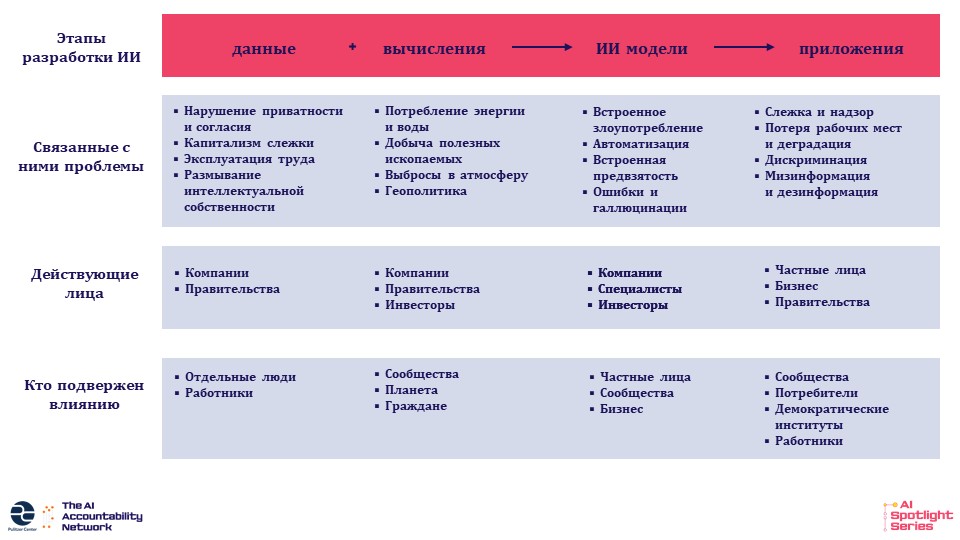
Структура, позволяющая выявлять и рассказывать истории об ИИ. Изображение: Pulitzer Center (в переводе редактора GIJN).
Изучение использованных данных
Простейшие модели ИИ могут использовать для обучения наборы данных, содержащие несколько сотен точек, в то время как наиболее сложные, такие как LLM, часто обучают на огромных массивах интернет-данных. Диапазон материала в обучающих данных может быть столь же широким. Он может представлять собой структурированные табличные данные, аккуратно организованные в строки и столбцы, или неструктурированный текст, собранный с платформ социальных сетей, новостных сайтов и онлайн-форумов. Всё чаще материалы также включают изображения и видео.
Большинство репортажей, посвященных этапу разработки данных, как правило, фокусируются на более сложных системах, обучающихся на огромных массивах данных в промышленных масштабах. Многие из этих статей посвящено вопросам конфиденциальности и интеллектуальной собственности. В частности, тому, как материалы, защищённые авторским правом, или личные данные попадают в обучающие конвейеры для моделей ИИ. Например, Atlantic рассматривает, как компания Meta предположительно использовала тысячи пиратских книг для обучения своей генеративной модели ИИ Llama. Представитель Meta отказался отвечать на вопросы журналистам Atlantic, сославшись на продолжающееся судебное разбирательство против компании. Статья The New York Times сообщает, что страховые компании покупают у, казалось бы, безобидных приложений, персональные данные о вождении для оценки рисков водителей .
Однако изучение данных также включает в себя анализ человеческого труда, сделавшего обучающие наборы данных пригодными для использования. Хотя компании, как правило, представляют сбор и обучение данных как высокоавтоматизированный процесс, в реальности очищением и классификацией обучающих наборов часто занимаются многочисленные специалисты по разметке данных, работающие через аутсорсинговые фирмы и цифровые платформы для трудоустройства преимущественно в странах Глобального Юга. Эти работники размечают изображения кошек и собак, которые подаются в классификаторы изображений, обводят рамки вокруг объектов на видеорегистраторах, используемых для обучения беспилотных автомобилей, или выявляют разжигание ненависти и насильственный контент, чтобы предотвратить его воспроизведение в обучающих системах.
Репортажи со всего мира показывают, что сотрудники, занимающиеся обработкой данных, подвергаются эксплуатации, получают низкую зарплату и иногда вынуждены работать с травмирующим контентом. Расследование Бюро журналистских расследований показывает, как низкооплачиваемые фрилансеры по всему миру, сами того не подозревая, помогают обучать системы распознавания лиц, используемые российским правительством. Материал Africa Uncensored посвящён растущей «индустрии ИИ-репетиторов», где высокообразованные специалисты обучают чат-ботов давать более качественные ответы.
Исследование вычислительных ресурсов
После сбора и очистки тренировочных наборов данных компании используют их для обучения моделей ИИ. В то время как простые модели ИИ можно обучить за доли секунды на обычном ноутбуке, более сложные модели, такие как ChatGPT компании OpenAI, требуют огромных вычислительных ресурсов. Эти вычислительные мощности, часто называемые вычислительными ресурсами или попросту «вычислителями» (англ.«compute»), обычно обеспечиваются специализированными компьютерными чипами, размещёнными в огромных центрах обработки данных.
Освещая стадии развития вычислительных мощностей, журналисты обычно уделяют основное внимание экологическому, социальному и экономическому воздействию разрастающейся и быстро расширяющейся физической инфраструктуры, обеспечивающей работу современных систем искусственного интеллекта. Когда мы впервые подготовили серию статей об ИИ в 2024 году, тема центров обработки данных была ещё относительно новой. С тех пор вышло множество репортажей из Латинской Америки, Азии, Африки и США, демонстрирующих, какие огромные объёмы энергии и воды потребляют центры обработки данных, а также попытки корпораций или правительств скрыть эти цифры. Например, в Бразилии Пулитцеровская стипендиатка Лаис Мартинс обнаружила, что центр обработки данных TikTok, похоже, потреблял столько же электроэнергии, сколько 2,2 миллиона человек; компания не ответила на запрос репортёра.
Репортажи о центрах обработки данных выходят за рамки простого анализа воздействия на окружающую среду. Журналисты также рассматривают, как центры обработки данных меняют местные сообщества, часто показывают невыполненные обещания экономического роста и интенсивные лоббистские усилия на местном и национальном уровнях по привлечению и строительству таких центров. Мартинс разработала адаптированную версию нашей концепции, сфокусированную исключительно на освещении центров обработки данных. Вы можете ознакомиться с ней в таблице ниже.
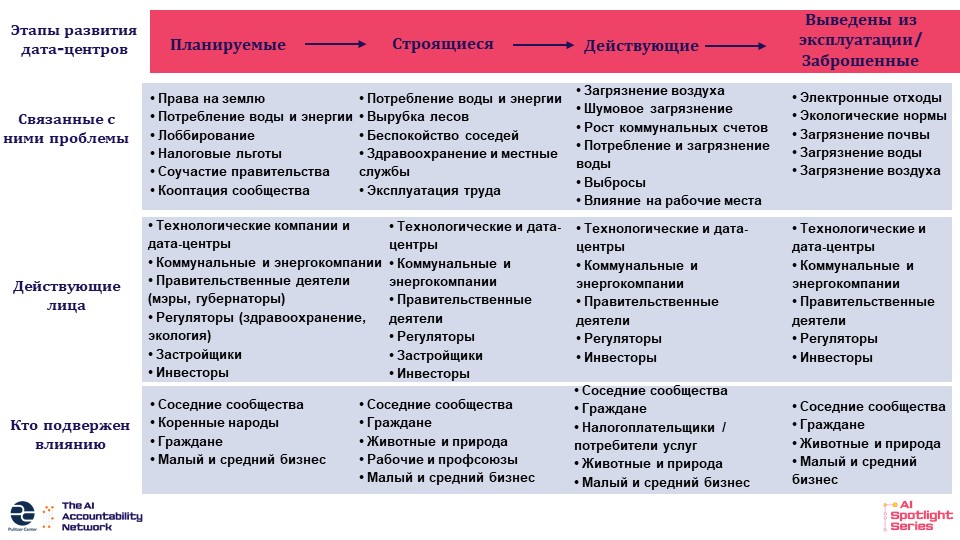
Как расследовать деятельность центров обработки данных. Изображение: Pulitzer Center (в переводе редактора GIJN).
Исследование моделей
Сочетание обучающих данных и вычислительных мощностей позволяет создать модель искусственного интеллекта — технический артефакт, который делает прогнозы, классифицирует данные или, в случае генеративного ИИ, создает совершенно новый контент. Также как данные и вычислительные ресурсы, модели ИИ различаются по сложности и масштабу: от относительно простых систем машинного обучения, используемых для расчёта страховых взносов на медицинское обслуживание, до усовершенствованных систем глубокого обучения, способных генерировать реалистичные изображения.
В статьях, посвященных моделям искусственного интеллекта, как правило, затрагивают вопросы, связанные с предвзятостью, ошибками или ужасающими последствиями автоматизации для общества и учреждений.
В ходе таких расследований можно тщательно изучать проектные решения, если они доступны, например, обучающие данные или параметры, используемые моделью. Например, El Confidencial в ходе расследования получили формулу системы искусственного интеллекта, используемой в каталонской тюремной системе для прогнозирования того, кто совершит преступление в будущем. По словам журналистов, модель систематически присваивала более высокие баллы риска определённым группам на основе дискриминационных или нерелевантных факторов.
Если такая информация недоступна, можно проанализировать результаты работы модели. Rest of World провели системный анализ 3000 изображений, созданных популярным инструментом для генерации изображений MidJourney AI, и обнаружили, что система воспроизводит грубые стереотипы о различных культурах. По словам журналистов, компания не ответила на их запросы о комментариях. Филиппинский центр журналистских расследований провёл обратное проектирование алгоритма Grab, популярного приложения для заказа такси, собрав тысячи вызовов от пользователей. Журналисты обнаружили, что Grab постоянно взимал с клиентов плату за повышенный спрос, которая должна действовать только в часы пик. В письменном ответе PCIJ филиппинское подразделение Grab заявило, что «полностью сотрудничало с расследованием [Управления по лицензированию и регулированию наземного транспорта]», участвуя в слушаниях.
Изучение приложений
И наконец, журналистам важно рассмотреть, как искусственный интеллект применяется в реальном мире. Когда технология ИИ работает не так, как задумано, или дает сбои, многие люди могут пострадать из-за решений, принимаемых автоматизированными системами, такими как алгоритмы или приложения генеративного ИИ.
В статье для Guardian репортёрка Йохана Бхуян показала, как чрезмерная зависимость правительства США от приложений-переводчиков на базе искусственного интеллекта привела к тому, что один проситель убежища шесть месяцев провёл в центре содержания под стражей ICE. Приложение плохо работало с некоторыми языками, ресурсы для которых были ограниченны, и из-за неправильного перевода человек не мог ни с кем пообщаться. Министерство внутренней безопасности США (DHS) не ответило на запрос Guardian.
В репортаже Херы Ризван об использовании индийским правительством технологии распознавания лиц выяснилось, что приложение, которое использовали чиновники для выдачи экстренных продовольственных пайков, не смогло идентифицировать некоторых беременных или кормящих женщин, поскольку их лица отличались от старых изображений, хранящихся в государственных базах данных. Министерство по делам женщин и детей не ответило на вопросы Ризван.
Освещение ответственного использования ИИ доступно каждому
Как показывают приведённые выше примеры, журналисты могут освещать тему подотчётности ИИ, имея различный уровень технических знаний и ресурсов. Истории могут быть короткими или длинными, в большей степени ориентированными на человека или на технические тонкости. Мы надеемся, что предложенные нами схемы, методы и примеры помогут другим журналистам найти свой собственный подход к освещению темы подотчётности в сфере ИИ.
Ресурсы
- Алгоритмическая грамотность для журналистов: ресурс с пояснениями и другими материалами.
- Открытая учебная программа AI Spotlight Series предлагает видеоуроки, примеры структуры и презентации в рамках инициативы Пулитцеровского центра по обучению журналистов со всего мира основам искусственного интеллекта.
- Руководство для журналистов по выявлению контента, созданного с помощью ИИ (на русском).
- Руководство по расследованию алгоритмов социальных сетей (на русском).
Исследовательские организации
- Algorithmic Justice League: организация, которая документирует и исследует вред, причиняемый алгоритмами.
- AI Now Institute: независимый институт, публикующий исследования в области искусственного интеллекта и алгоритмической подотчётности.
- Центр демократии и технологий: некоммерческая организация, публикующая отчёты о гражданских свободах в цифровую эпоху.
- Data and Society: некоммерческая исследовательская организация, специализирующаяся на технологиях, данных и политике.
- Algorithm Watch: некоммерческая организация, базирующаяся в Цюрихе и Берлине, и изучающая, как алгоритмы и искусственный интеллект (ИИ) влияют на демократию, справедливость и права человека.
- Privacy International: некоммерческая организация, базирующаяся в Лондоне, и требующая подотчётности институтов, которые разрушают общественное доверие.
- Derechos Digitales — некоммерческая организация по защите цифровых прав, специализирующаяся на Латинской Америке.
- African Digital Rights Network: панафриканская организация по защите цифровых прав.
 Габриэль Гайгер — журналист-расследователь из Афин, Греция, специализирующийся на освещении вопросов слежки и алгоритмической подотчётности. Сейчас он работает журналистом-расследователем в некоммерческой новостной организации Lighthouse Reports, базирующейся в Нидерландах. Его работы публиковали в WIRED, Le Monde, Der Spiegel, Guardian и других изданиях.
Габриэль Гайгер — журналист-расследователь из Афин, Греция, специализирующийся на освещении вопросов слежки и алгоритмической подотчётности. Сейчас он работает журналистом-расследователем в некоммерческой новостной организации Lighthouse Reports, базирующейся в Нидерландах. Его работы публиковали в WIRED, Le Monde, Der Spiegel, Guardian и других изданиях.
 Лем Тхюи Во — журналистка, которая сочетает анализ данных с репортажами с мест событий, чтобы изучить, как системы и политика влияют на отдельных людей. Журналистка-расследовательница Documented, независимой некоммерческой редакции, освещающей события вместе с иммигрантскими сообществами и для них, а также доцент кафедры журналистики данных в Высшей школе журналистики им.Крейга Ньюмарка. Ранее она работала в The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America и Planet Money на NPR.
Лем Тхюи Во — журналистка, которая сочетает анализ данных с репортажами с мест событий, чтобы изучить, как системы и политика влияют на отдельных людей. Журналистка-расследовательница Documented, независимой некоммерческой редакции, освещающей события вместе с иммигрантскими сообществами и для них, а также доцент кафедры журналистики данных в Высшей школе журналистики им.Крейга Ньюмарка. Ранее она работала в The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America и Planet Money на NPR.
Выявление контента, созданного с помощью ИИ: Пособие для журналистов

Расследования по открытым источникам с Хенком ван Эссом

Пособие по расследованию алгоритмов социальных сетей

Основы работы в Google Таблицах: Пошаговое руководство для журналистов

Как отличить настоящее изображение от ИИ-подделки: Конспект вебинара Хенка ван Эсса

Новые инструменты на основе ИИ и больших языковых моделей для журналистов: Что нужно знать

ChatGPT как инструмент для быстрого поиска: Советы расследователям

Как расследовать аудиодипфейки, созданные ИИ

Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Перепечатывайте наши статьи бесплатно по лицензии Creative Commons
Перепостить эту статью
Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Читать дальше
Поиск по открытым источникам Советы и инструменты
Как отличить настоящее изображение от ИИ-подделки: Конспект вебинара Хенка ван Эсса
Как отличить сгенерированный контент от настоящего, какие инструменты могут пригодиться в фактчеке и какие проверят материал на наличие синтетического контента — об этом на вебинаре Глобальной сети журналистов-расследователей (GIJN) рассказал Хенк ван Эсс, эксперт в области OSINT и цифровой верификации.
Журналистика данных Советы и инструменты
Новые инструменты на основе ИИ и больших языковых моделей для журналистов: Что нужно знать
Докладчики NICAR 2024 рассказали, какие чат-боты LLM и инструменты ИИ помогли в их расследованиях – особенно в работе с программным кодом и поиске разрозненных источников данных.
Советы и инструменты
ChatGPT как инструмент для быстрого поиска: Советы расследователям
Как использовать ChatGPT для поиска контактных данных новых источников и беглого анализа документов, чтобы ускорить начало расследования. Этими и другими советами поделился журналист-расследователь KUSA-TV Джереми Джоджола на конференции IRE24.
Ресурс Видео
Как расследовать аудиодипфейки, созданные ИИ
Сгенерированные искусственным интеллектом аудиосимуляции клонируют реальный голос для создания фальшивого сообщения с помощью инструмента машинного обучения. Такие подделки дёшевы в производстве и их легко распространить. На этом вебинаре трое экспертов поделились советами, инструментами и ресурсами для выявления, расследования и проверки потенциальных дипфейков. Сайлас Джонатан – менеджер по цифровым расследованиям в Центре инноваций и развития журналистики […]