
Image: Shutterstock
ٹک ٹاک پر مِس انفارمیشن: ڈاکیومنٹڈ نے مختلف زبانوں میں سینکڑوں ویڈیوز کا کیسے جائزہ لیا؟
یہ مضمون ان زبانوں میں بھی دستیاب ہے
ایڈیٹرز نوٹ: یہ رپورٹ پلٹزر سینٹر کے ساتھ مشترکہ طور پر شائع کی گئی تھی۔ اصل تحقیق ڈاکیومنٹڈ کی ویب سائٹ پر شائع ہوئی تھی۔
گزشتہ سال، ڈاکیومینٹڈ نے مختلف کہانیاں شائع کیں جو ایسے مہاجرین پر ٹک ٹاک کے اثرات کے بارے میں تھیں جنہوں نے اس پلیٹ فارم پر موصول ہونے والی معلومات کی بنیاد پر نیویارک شہر تک کا سفر طے کیا۔ نیویارک میں تارکین وطن کی کمیونٹیز کے لیے رپورٹنگ کرنے والا ایک غیر منافع بخش نیوز روم معلومات کے اس ذریعے پر گہری نظر ڈالنا چاہتے تھے۔
مختلف زبانوں میں مِس انفارمیشن اور ڈِس انفارمیشن کی تحقیق سے کئی مسائل سامنے آئے: غلط معلومات پھیلانے والے افراد اکثر اپنے اکاؤنٹس حذف کر دیتے ہیں۔ اس لیے صحافیوں کو اکاؤنٹس کے غیر فعال ہونے سے پہلے ہی انہیں محفوظ کرنا پڑتا ہے۔ اس کے علاوہ، زیادہ تر مواد جسے ہم دیکھ رہے ہوتے ہیں آڈیوویژول فارمیٹ میں ہوتا ہے، جس کی وجہ سے ان میں موجود موضوعات پر سادہ تجزیے کرنا مشکل ہو جاتا ہے۔ جب ہم اس مواد کو سمجھنے کی کوشش کرتے ہیں تو ہمیں بہت زیادہ مواد ملتا ہے جس کی وجہ سے کسی بھی دستی طریقہ سے اس میں موجود معلومات کو سمجھنا خاص طور پر مشکل ہو جاتا ہے۔
کئی ماہ تک مختلف پسِ منظر رکھنے والے کمیونٹی نامہ نگاروں کے ساتھ کام کر کے، ڈاکیومینٹڈ نے ٹک ٹاک کے متعلق مِس انفارمیشن رپورٹنگ کے منصوبوں کو مکمل کرنے کے لیے تکنیکی اور تحقیقی طریقہ کار بنائے۔
ہم اس پوسٹ میں ان میں سے کچھ عالمی صحافتی برادری کو اس امید کے ساتھ بتا رہے ہیں کہ وہ اس موضوع میں دلچسپی رکھنے والے افراد کے لیے کار آمد ثابت ہوں گے۔
مواد کا محفوظ کرنا
اکثر غلط اور گمراہ کن معلومات کی مہمات اچانک شروع ہوتی ہیں اور جیسے شروع ہوتی ہیں ویسے ہی تیزی سے غائب ہو جاتی ہیں۔ اس وجہ سے مس انفارمیشن کی تحقیقات میں عام طور پر دلچسپی کے حامل اکاؤنٹس کی شناخت اور انہیں آرکائیو یا محفوظ کرنے کی ضرورت ہوتی ہے۔
دلچسپی کے اکاؤنٹس کی شناخت ایک سوچا سمجھا ادارتی فیصلہ ہوتا ہے۔ ہمارے معاملے میں، ہم نے مہاجرین سے بات کی اور کچھ کے ساتھ مل کر کام کیا تاکہ ان کے ٹک ٹاک کے استعمال کو بہتر طور پر سمجھ سکیں۔ ہمیں معلوم ہوا کہ بہت سے مہاجرین کو امریکی امیگریشن سسٹم کے بارے میں بہت زیادہ آن لائن مِس انفارمیشن موصول ہوتی ہیں۔ اس کے بعد ماہرین نے ہمیں عام مسائل (جیسے کہ دھوکہ دہی کرنے والے دھوکے بازوں) کی شناخت کرنے میں مدد دی اور ہمیں وہ طریقے سکھائے جن کے ذریعے ہم متعلقہ اکاؤنٹس کو تلاش کر سکتے تھے جیسے کہ مخصوص الفاظ کی تلاش کرنا۔
جب ہمارے پاس کچھ ایسے اکاؤنٹس کی فہرست بن گئی جنہیں ہم مزید جانچنا چاہتے تھے تو ہم نے ان کی پروفائلز ویب براؤزر میں کھولیں، مکمل صفحہ اسکرول کیا یہاں تک کہ تمام ویڈیوز لوڈ ہو گئیں اور پھر پورا ایچ ٹی ایم ایل صفحہ ڈاؤن لوڈ کر لیا۔ اس کے بعد ہم نے ہر اکائونٹ کے ویڈیو کا لنک حاصل کرنے کے لیے ایک پائتھون سکریپر لکھا۔
ہم نے yt-dlp ٹول کا استعمال کر کے ہر ویڈیو اور اس کے میٹا ڈیٹا کو ڈاؤن لوڈ کیا اور انہیں ایک مقامی ڈرائیو پر محفوظ کر لیا۔ (اس لائبریری کی طرف ہماری رہنمائی کرنے پر ہم دا واشنگٹن پوسٹ کی کیتلین گلبرٹ اور بیلنگ کیٹ کا خصوصی شکریہ ادا کرتے ہیں۔)
خودکار نقل (آٹو ٹرانسکرپشن)
ویڈیوز کے ساتھ کام کرنا مشکل ہو سکتا ہے کیونکہ انہیں ایک ایک کر کے دیکھنا بہت وقت لے سکتا ہے۔ کام کو کم کرنے اور یہ سمجھنے میں مدد حاصل کرنے کے لیے کہ ہم کس قسم کے مواد کا جائزہ لے رہے ہیں، ہم نے ڈائونلوڈ کی گئی ویڈیوز کو وِسپر کے اوپن سورس ورژن کے ذریعے خودکار طریقے سے ٹرانسکرائب کرنے کا فیصلہ کیا۔ یہ ٹرانسکرپشن اسپیچ ریکگنیشن (تقریر کی شناخت) ماڈل اوپن اے آئی نے شائع کیا ہے اور یہ مختلف زبانوں میں دستیاب ہے۔
اس ماڈل کی کارکردگی ہر زبان کے لحاظ سے مختلف تھی: ہم نے اس لائبریری کو دو زبانوں، ویتنامی اور ہسپانوی میں جانچا۔ ہمیں پتہ لگا کہ ویتنامی ٹرانسکرپشن ناقابلِ استعمال تھی۔ جبکہ ہسپانوی ورژن میں کچھ مسائل تھے لیکن اس کی درستگی اتنی تھی کہ ہم کام جاری رکھ سکیں۔
وِسپر (جو کہ ٹرانسفارمر نامی ایک مشین لرننگ ماڈل کی خاص قسم ہے) جیسے مشین لرننگ ماڈلز کتنا اچھا کام کریں گے، اس بات کا انحصارمکمل طور پر اس ڈیٹا پر ہوتا ہے جس پر اس ماڈل کی تربیت کی جاتی ہے اور تربیت کے لیے کن زبانوں کو ترجیح دی جاتی ہے۔
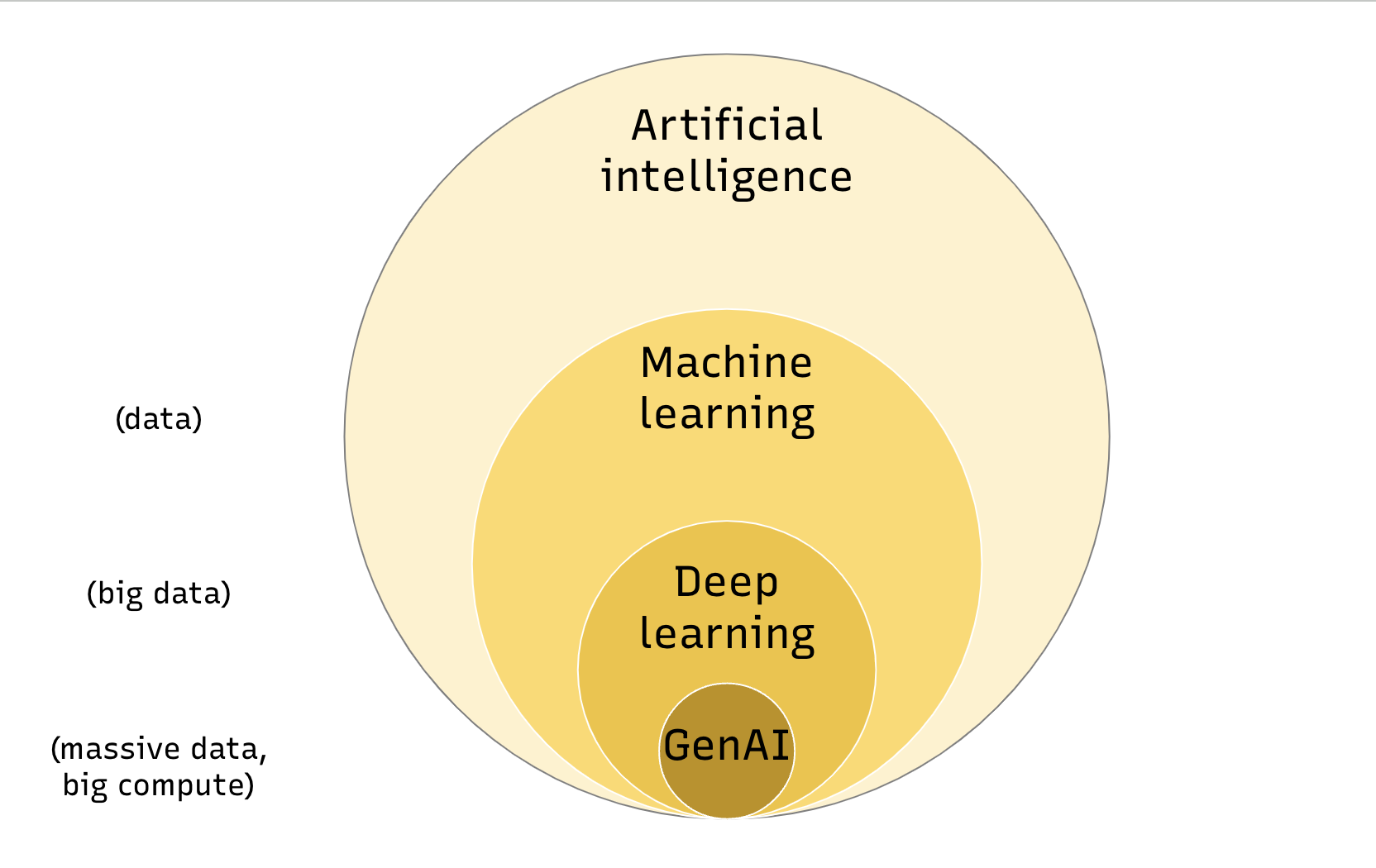
ڈیٹا پروویننس انیشی ایٹو کی ایک نئی تحقیق جس میں ٹیکنالوجی انڈسٹری اور جامعات کے 50 سے زائد محققین شامل ہیں، سے پتہ چلا کہ 90 فیصد سے زیادہ ڈیٹا سیٹس جو اے آئی کی تربیت کے لیے استعمال کیے گئے وہ یورپ اور شمالی امریکہ سے آئے تھے، ایم آئی ٹی ٹیک ریویو نے رپورٹ کی۔ افریقہ سے حاصل کردہ ڈیٹا 4 فیصد سے بھی کم تھا۔
مشین لرننگ ماڈلز اور دیگر ٹیکنالوجیز جنہیں مجموعی طور پر مصنوعی ذہانت (اے آئی) کہا جاتا ہے، کے استعمال کرنے کے ساتھ ایک بڑا مسئلہ جڑا ہوا ہے: ان ماڈلز کے ذریعے کیا گیا کام ہمیشہ 100 فیصد درست نہیں ہوگا۔
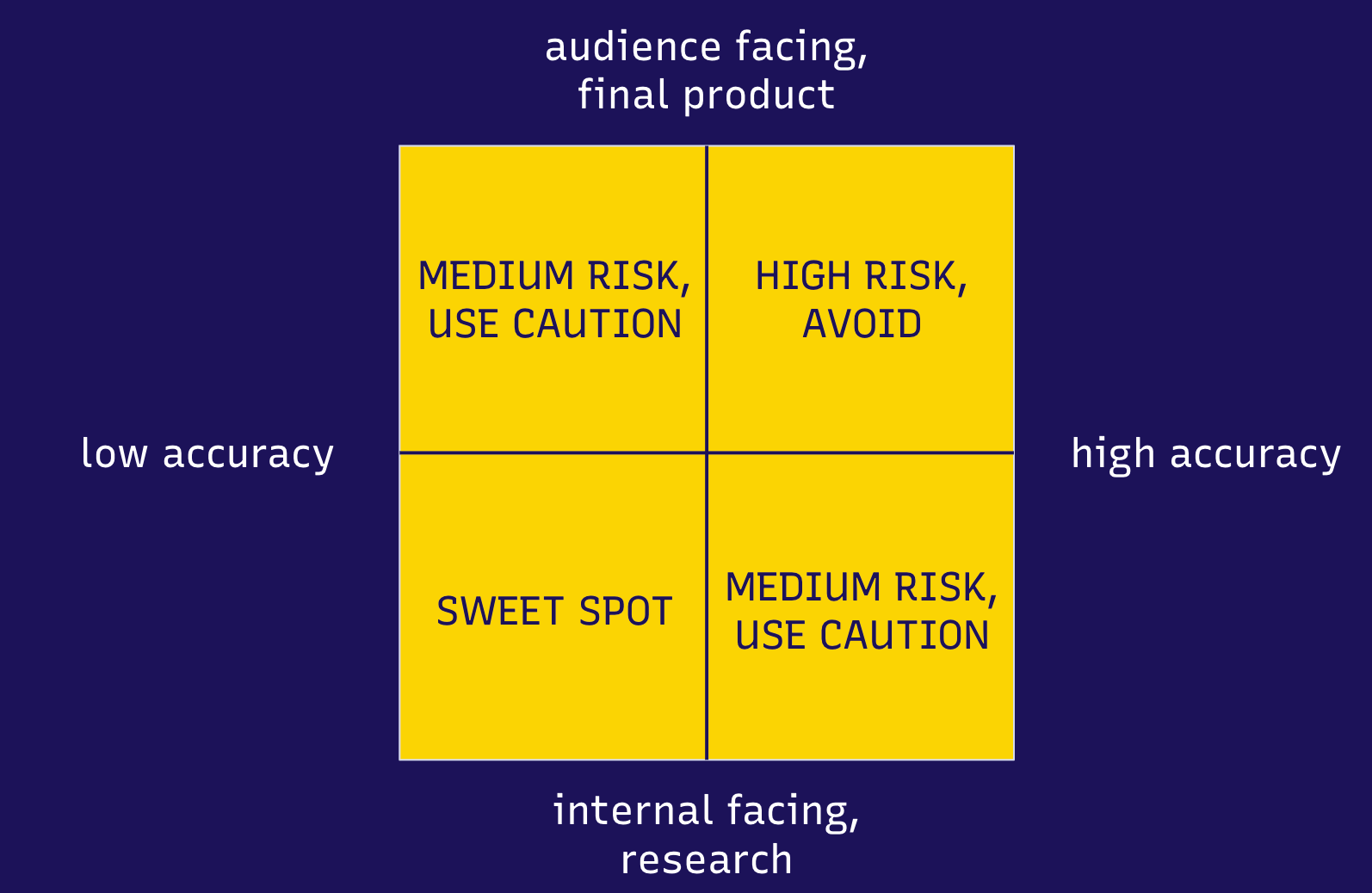
جب صحافی کیرن ہاؤ، گیبریل گائگر اور میں نے پلٹزر سینٹر کے ساتھ مصنوعی ذہانت (اے آئی) پر ورکشاپس کی ایک سیریز پر کام کیا تو ہم نے یہ سوچنا شروع کیا کہ مشین لرننگ اور اس کی ایک مقبول ذیلی قسم جنریٹو اے آئی صحافت کے شعبے میں کتنی مفید ہو سکتی ہے۔ ہم نے ایک ایسا فریم ورک تیار کیا جو صحافیوں کو اس بارے میں سوچنے میں مدد دے سکتا ہے کہ جنریٹو اے آئی کے خیالی یا غیر حقیقی معلومات تخلیق کرنے کے رجحان اور دیگر مشین لرننگ ماڈلز میں ممکنہ غلطیوں کےباوجود اے آئی کس حد تک کارآمد ہو سکتی ہے۔
نیچے ایک گراف دیا گیا ہے جو ہمارے خیالات کی وضاحت کرتا ہے: آپ کی رپورٹنگ میں اے آئی کا استعمال "محفوظ” ہو سکتا ہے اگر اے آئی سے انجام دیا گیا کام انتہائی درست ہونے کی ضرورت نہ رکھتا ہو اور اس نے شائع نہ ہونا ہو۔ مثال کے طور پر، آپ جنریٹو اے آئی یا دیگر مشین لرننگ ماڈلز کو بڑی تعداد میں دستاویزات کی درجہ بندی کرنے کے لیے استعمال کر سکتے ہیں تاکہ اس میں سے آپ کی جانچ کے لیے ایک ذیلی سیٹ الگ کیا جا سکے۔ ہوسکتا ہے کہ آپ کی درجہ بندی 100% درست نہ ہو، جس کا مطلب ہے کہ آپ کی دلچسپی کی کوئی دستاویز آپ کی جانچ میں نہ آ سکے لیکن یہ پھر بھی اس قابل ہو کہ آپ فیصلہ کر سکیں کہ آپ ان کچھ دستاویزات پر مزید تحقیق کرنا چاہتے ہیں یا نہیں۔
دوسری طرف، اے آئی کو کسی ایسے کام کے لیے استعمال نہیں کرنا چاہیے جو انتہائی درست ہونا ضروری ہو اور جسے شائع کیا جانا ہو۔ مثال کے طور پر جنریٹو اے آئی کی مدد سے مکمل مضامین لکھ کر انہیں شائع کرنا مناسب نہیں ہے کیونکہ بڑے لینگویج ماڈلز کے بارے میں یہ معلوم ہے کہ وہ غلط معلومات تخلیق کر سکتے ہیں۔
اس تحقیق میں وِسپر کا استعمال معنی رکھتا ہے۔ اگرچہ آٹو ٹرانسکرپٹ مکمل طور پر درست نہیں تھیں لیکن انہوں نے ہمیں زیادہ تر ویڈیوز کے مفہوم کو سمجھنے میں مدد دی اور ہمیں ان ویڈیوز کی شناخت میں مدد کی جن کی ہم مزید تفصیل سے دیکھنا چاہتے تھے۔ چونکہ اس کام کے نتائج براہ راست اشاعت کے لیے نہیں تھے، اس لیے ہمیں ہمارے کام کے لیے مشین لرننگ کے اس طریقے کا استعمال محفوظ لگا۔
بے تحاشا مواد کو کم کرنا
ٹرانسکرپشنز نے ہمیں مشین لرننگ کے مزید دو طریقوں کے ذریعے مواد کو ایک بہتر طریقے سے جانچنے میں مدد دی۔ یہ دو طریقے نیچرل لینگویج پروسیسنگ اور ٹاپک ماڈلنگ ہیں۔
نیچرل لینگویج پروسیسنگ (این ایل پی) مشین لرننگ کی ایک قسم ہے جو ڈویلپرز کو بڑی مقدار میں متن کو ڈیٹا میں تبدیل کرنے کی سہولت دیتی ہے تاکہ ہم اس کا تجزیہ کر سکیں۔ آپ این ایل پی کی مدد سے آسان تجزیے بنا سکتے ہیں جیسے کہ الفاظ کی فہرست اور کسی بھی متن میں وہ کتنی بار آ رہے ہیں۔ گوگل جیسی بڑی ٹیکنالوجی کمپنیاں اسے ورڈ پریڈکشن (لفظ کی پیش گوئی) کے لیے استعمال کرتی ہیں، پریڈکٹو سرچ میں استعمال ہونے والی قسم کی طرح۔
ٹاپک ماڈلنگ این ایل پی پر مبنی ایک اور طریقہ ہے: یہ بغیر نگرانی پر مبنی مشین لرننگ کی ایک قسم ہے جو الفاظ دیکھتی ہے اور ایسے الفاظ کا گروہ بنانے کی کوشش کرتی ہے جو شماریاتی طور پر ایک دوسرے کے قریب ظاہر ہوتے ہیں۔ الفاظ کے درمیان یہ قربت یا تعلق ان موضوعات کی نشاندہی کر سکتا ہے جو آپس میں جڑے ہوتے ہیں اور جن کی محققین آسانی سے تشریح کر سکتے ہیں۔

ہماری ٹرانسکرپشن کی بدولت، ہم اپنے کام میں کچھ بنیادی ٹاپک ماڈلنگ کر سکے تھے۔ اس سے ہمیں ایسے موضوعات کی شناخت کرنے میں مدد دی جن سے متعلقہ مزید ویڈیوز کا مزید گہرائی سے جائزہ لے سکتے تھے۔ ان موضوعات میں خدا کے حوالہ جات، امیگریشن، اور سی بی پی وَن جو ایک ایسی ایپ ہے جسے مہاجرین کو امریکہ میں داخل ہونے کے لیے استعمال کرنی ہوتی ہے)۔
یہ بھی مفید ہو سکتا ہے کہ مخصوص ویڈیوز کا جائزہ لینے اور وضاحت کرنے کے لیے یا جائزے کے لیے ویڈیوز کے ایک محدود ذخیرے کو چھانٹنے کے لیے ایک طریقہ کار تیار کیاجائے۔ بعض اوقات ایسی ویڈیوز کو اپنی آڈئینس کو تفصیل سے بیان کرنا مددگار ثابت ہو سکتا ہے جنہیں ناظرین نے سب سے زیادہ دیکھا ہو۔ جب آپ معلومات کے ایک بہت بڑے زخیرے جیسے کہ ہزاروں ویڈیوز پر کام کر رہے ہوں تو ایک اکائونٹ میں موجود ویڈیوز کے نمائندہ ایک ہزار ویڈیوز کے رینڈم سیمپل پر ایک گہری نظر ڈالنا اچھا ہو سکتا ہے۔
مِس افارمیشن پر لکھتے ہوئے یہ مؤثر ہوسکتا ہے کہ مواد کے بڑے ذخیرے کے میکرو لیول تجزیے کو ایسی انفرادی ویڈیوز کی مائیکرو لیول وضاحت کے ساتھ ملایا جائے جو تحقیق میں ظاہر ہونے والے موضوعات کی نمائندگی کرتی ہیں۔
دا ٹیک
اس پورے عمل کے دوران، ہم نے پائتھون پر مبنی ایک کوڈ پائپ لائن تیار کی، جس میں درج ذیل اسکرپٹس شامل ہیں:
- ایک ٹک ٹاک ویڈیو سے ویڈیوز کے لنکس نکالنا
- ویڈیوز کو ایک لوکل ڈرائیو پر ڈاؤنلوڈ کرنا
- مختلف زبانوں میں ویڈیوز کی آٹو ٹرانسکرپشن کرنا
- ٹرانسکرپٹس کے ساتھ بنیادی ٹاپک ماڈلنگ کرنا
آپ ان تمام اسکرپٹس کو یہاں سے ڈاؤن لوڈ کر سکتے ہیں:
https://github.com/lamthuyvo/tiktok-analysis-pipeline.
لام تھوی وو ایک صحافی ہیں جو ڈیٹا کے تجزیے کو زمینی رپورٹنگ کے ساتھ جوڑ کر یہ جانچتی ہیں کہ نظام اور پالیسیاں افراد پر کس طرح اثر انداز ہوتی ہیں۔ وہ اس وقت ڈاکیومنٹڈ کے ساتھ ایک تحقیقاتی رپورٹر کے طور پر کام کر رہی ہیں۔ ڈاکیومنٹڈ ایک آزاد، غیر منافع بخش نیوز روم ہے اور مہاجر برادریوں کے لیے اور ان کے ساتھ مل کر رپورٹنگ کرتا ہے۔ اس کے علاوہ، وہ کریگ نیومارک گریجویٹ اسکول آف جرنلزم میں ڈیٹا جرنلزم کی ایسوسی ایٹ پروفیسر بھی ہیں۔ اس سے پہلے، وہ دی مارک اپ، بزفیڈ نیوز، دی وال اسٹریٹ جرنل، الجزیرہ امریکہ اور این پی آر کے پلینٹ منی پروگرام میں صحافی کے طور پر کام کر چکی ہیں۔

صحافیوں کے لیے ٹِپ شیٹ: او سی سی آر پی کے ایلیف سے فائدہ کیسے اٹھائیں

گوگل شیٹس کی بنیادی باتوں پر صحافیوں کے لیے مرحلہ وار گائیڈ

قدرتی آفت کے بعد پوچھے جانے والے 10 تفتیشی سوالات

واشنگٹن آپ کے ملک میں کیا کر رہا ہے: دنیا بھر میں امریکی اثر و رسوخ کی تحقیق کے لیے ایک ٹپ شیٹ

نان کوڈرز کے لیے ڈیٹا کلیننگ کے ٹولز اور تکنیکیں

نیوز رومز اے آئی چیٹ بوٹس کو کس طرح اپنی رپورٹنگ بڑھانےاور اعتماد قائم کرنے کے لیے استعمال کر رہے ہیں

میکسکو، پیرو، نائیجریا اور مصر ست گلوبل شائینگ لائٹ آورڈ جیتنے والی دلیر تحقیقات
ایشیا میں ڈیٹا جرنلزم: نیوزرومز، کمیونیٹیز اور شواہد کے درمیان تعلقات کو ازسرِنو سوچنا

اس کام کا کریٹیو کامنز لائسنس ہے کریٹیو کامنز آٹریبیوشن - نو ڈیریوٹو 4.0 عالمی لائسنس
ہمارے مضامین کو تخلیقی العام لائسنس کے تحت مفت، آن لائن یا پرنٹ میں دوبارہ شائع کریں۔
اس آرٹیکل کو دوبارہ شائع کریں
اس کام کا کریٹیو کامنز لائسنس ہے کریٹیو کامنز آٹریبیوشن - نو ڈیریوٹو 4.0 عالمی لائسنس
اگلی کہانی پڑھیں
نان کوڈرز کے لیے ڈیٹا کلیننگ کے ٹولز اور تکنیکیں
کچھ آشان ٹولز ان لوگوں کو جو کوڈنگ کے بْیر ڈیٹا کو صاف کرنا سیکھنا چاہتے ہیں
نیوز رومز اے آئی چیٹ بوٹس کو کس طرح اپنی رپورٹنگ بڑھانےاور اعتماد قائم کرنے کے لیے استعمال کر رہے ہیں
فلپائن سے لے کر برطانیہ تک، بہت سے بڑے نیوز رومز نے اپنے آے آئی چیٹ بوٹس بنائے ہیں جو صرف اس سائٹ کے قابل اعتماد رپورٹنگ آرکائیو اور جانچ شدہ ڈیٹا بیس کو بطور ماخذ مواد استعمال کرتے ہوئے جواب دینے کے لیے ڈیزائن کیے گئے ہیں۔
آوارڈز
میکسکو، پیرو، نائیجریا اور مصر ست گلوبل شائینگ لائٹ آورڈ جیتنے والی دلیر تحقیقات
یہ تینوں فاتحین اور خصوصی اقتباس حاصل کرنے والے ترقی پذیر یا منتقلی والے ممالک کی شاندار صحافت کی نمائندگی کرتے ہیں، جو خطرے میں یا خطرناک حالات میں انجام دی گئی ہیں۔
ایشیا میں ڈیٹا جرنلزم: نیوزرومز، کمیونیٹیز اور شواہد کے درمیان تعلقات کو ازسرِنو سوچنا
ایشیا میں ڈیٹا کے ساتھ کام کرنے والے نیوز رومز نے بند ڈیٹا رجیم، سیاسی دباؤ، اور وسائل کے فرق کو نیویگیٹ کرنے کے لیے جدید طریقے تلاش کیے ہیں۔