
Image: Shutterstock
ہر ملک ڈیٹا پیدا کرتا ہے لیکن ہر ملک اسے ایک منظم طریقے سے پیدا نہیں کرتا۔ اہم بات صرف ڈیٹا کی مقدار نہیں ہوتی بلکہ یہ بھی اہم ہوتا ہے کہ اس ڈیٹا کو کس طرح معیاری بنایا گیا ہے اور منظم کیا گیا ہے۔ سب سے زیادہ بکھرا ہوا یا زیادہ تر ڈیٹا مینول نظاموں سے آتا ہے جو بغیر کسی طے شدہ مواد کے انسانوں کی مدد سے چلائے جاتے ہیں۔ یہ نظام نہ صرف سست ہوتے ہیں بلکہ (ڈیٹا کی) تصدیق کو مشکل بناتے ہیں اور بڑی غلطیوں کا سبب بن سکتے ہیں۔
یہاں تک کہ وہ ممالک جو بہت زیادہ ڈیٹا پیدا کرتے ہیں اکثر ایسے ڈیٹا سیٹس رکھتے ہیں جو ناقابل رسائی، ٹکڑوں میں یا میٹا ڈیٹا کے بغیر ہوتے ہیں:
- امریکہ بہت زیادہ ڈیٹا پیدا کرتا ہے لیکن ان میں غیر مرکزی ڈھانچے اور پرانے نظام عام ہیں۔
- چین کے پاس بڑے پلیٹ فارم ہیں لیکن اس کا بند انفراسٹرکچر ڈیٹا شیئرنگ کو محدود کرتا ہے۔
- بھارت ڈیٹا پیدا کرنے والا ایک اہم ملک ہے لیکن غیر مستقل ڈیجیٹائزیشن ڈیٹا کے معیار کو کم کرتی ہے۔
- برازیل کے پاس شفافیت کے مضبوط قوانین ہیں لیکن ڈیٹا کو معیاری بنانے میں دشواریوں کا سامنا کرتا ہے۔
- یورپی ممالک (بشمول ترکی) میں متضاد قوانین کبھی کبھار ڈیٹا میں عدم مطابقت پیدا کرتے ہیں۔
- نائیجیریا جیسے ممالک کے پاس محدود انفراسٹرکچر موجود ہے جو ان کے ڈیٹا ایکوسسٹم کو محدود کرتا ہے۔
تحقیقاتی صحافیوں کے لیے اس کا مطلب ایک ڈیٹا سیٹ کو اس کے مواد سے آگے دیکھنا ہے۔ یہ دیکھنا بھی بہت اہم ہے کہ وہ کس طرح بنا اور ترتیب دیا گیا۔ صحافیوں کو الجھے ہوئے ڈیٹا مارکیٹس کی پرواہ کیوں کرنی چاہیے؟ کیونکہ بڑی کمپنیوں سرکاری اداروں اور این جی اوز کی طرح صحافی بھی اکثر کہانی کا صرف ایک حصہ دیکھ پاتے ہیں۔ مقصد چھپائی گئی چیز سے پردہ اٹھانا ہے۔
اس تناظر میں تحقیقاتی اور ڈیٹا جرنلزم ڈیٹا کی نوعیت کے مطابق مختلف طریقے اپنانے کا تقاضا کرتے ہیں۔ سٹرکچرڈ ڈیٹا منظم ہوتا ہے اور اکثر اعداد کی شکل میں اور ٹیبلوں کی صورت میں ملتا ہے۔ یہ ڈیٹا تجزیے، موازنے اور بصری پیشکش کے لیے مثالی ہوتا ہے۔ تاہم، آج زیادہ تر ڈیجیٹل دنیا ان سٹرکرچرڈ ڈیٹا پر مشتمل ہے: ای میلز، سوشل میڈیا پوسٹس، کسٹمر ریویوز، ویڈیوز، آڈیو فائلز اور دیگر غیر منظم مواد۔
یہ ڈیٹا سیٹس معلومات کا خزانہ ہو سکتے ہیں لیکن ان کی الجھی ہوئی شکل ان کا گہرائی سے تجزیہ کرنا مشکل بنا دیتی ہے جب تک انہیں صاف اور منظم نہ کیا جائے۔ آج تقریباً ۸۰٪ ڈیجیٹل ڈیٹا غیر منظم ہے جو صحافیوں کے لیے ایک بڑا چیلنج ہے: معنی خیز تجزیہ کرنے یا اس میں سے خبریں سامنے لانے سے پہلے ڈیٹا کو صاف اور منظم کرنا ضروری ہے۔
مارکیٹ ریسرچ فرم ڈیٹا ان ٹیلو کی ۲۰۲۴ کی رپورٹ کے مطابق عالمی غیر منظم ڈیٹا اینالیٹکس مارکیٹ کی قیمت ۲۰۲۴میں 7.92 ارب امریکی ڈالر تھی اور توقع ہے کہ 2033 تک یہ 65.45 ارب امریکی ڈالر تک پہنچ جائے گی۔ یہ ترقی ڈیجیٹل مواد کی وسیع توسیع اور اے آئی کے انضمام سے ممکن ہو سکی ہے۔ تاہم، تکنیکی ترقی خود بخود ڈیٹا کے ساتھ کام کرنا آسان نہیں بناتی۔ ڈیٹا کی مکمل صفائی کی ضرورت پہلے سے کہیں زیادہ بڑھ گئی ہے۔
ڈیٹا سے مالا مال ممالک جیسے امریکہ یا چین میں بھی الجھا ہوا ڈیٹا، غائب میٹا ڈیٹا اور غیر مستقل فارمیٹس تجزیے کو مشکل بناتی ہیں۔ پی ڈی ایف، اسکین شدہ دستاویزات، غیر معیاری ایکسل فائلیں اور محدود رسائی والے ڈیٹا بیس ڈیٹا کلیننگ والی کہانیوں کی وہ مثالیں ہیں جن سے صحافیوں کو لازمی نبٹنا پڑتا ہے۔
صحافیوں کا اکثر سامنا ایکسل فائلز، پی ڈی ایف، اوپن ڈیٹا پورٹلز سے پیچیدہ ٹیبلز یا مختلف اداروں کی جانب سے شائع شدہ خام سوشل میڈیا ڈیٹا سیٹس سے ہوتا ہے۔ یہ ڈیٹا سیٹس عموماً غیر مستقل، نامکمل یا غلطیوں سے بھرے ہوئے ہوتے ہیں۔ کوڈرز پائی تھن، آر، یا ایس کیو ایل کے ذریعے ان مسائل کو حل کر سکتے ہیں لیکن ہر صحافی کوڈنگ نہیں کرتا۔ کوڈنگ نہ کرتے ہوئے بھی ڈیٹا کے ساتھ گہرائی میں نہ جڑنے کی صورت میں سنگین غلطیاں ہو سکتی ہیں۔
جی آئی جے این کا بجلی گرنے سے متاثر ہونا: اپنے ڈیٹا کو صاف کرنے کا ایک جلدی سبق اس کی بہترین وضاحت کرتا ہے۔ بجلی گرنے کے واقعات کے ایک بڑے ڈیٹا سیٹ کا استعمال کرتے ہوئے یہ دکھاتا ہے کہ کیسے "ایکٹویٹی” کالم میں معمولی فرق — جیسے "روفنگ” اور "ورکنگ آن دا روف” — غلط درجہ بندی کا سبب بن سکتا ہے۔ یہ مضمون دکھاتا ہے کہ ڈیٹا کو صاف کیے بغیر بصری شکل میں پیش کرنے سے گمراہ کن نتائج اور کہانیاں پیدا ہو سکتی ہیں۔ یہ چیز ڈیٹا کلیننگ کو نہ صرف ایک تکنیکی کام بناتی ہے بلکہ صحافیوں کی ایک اخلاقی ذمہ داری بھی بناتی ہے۔
خوش قسمتی سے ان عوامل کو آسان تر بنانے کے لیے ٹولز اور وسائل موجود ہیں۔ جی آئی جے این کا غیر منظم ڈیٹا کو منظم کرنے کے لیے پن پوائنٹ کا استعمال تفصیل سے بتاتا ہے کہ یہ ٹول کس طرح غیر منظم ڈیٹا سیٹس کو منظم کرنے میں مدد دیتا ہے۔ بکھرے ہوئے ڈیٹا کے ساتھ کام کرنا کبھی کبھار ایک لامتناہی پہاڑ پر چڑھنے جیسا محسوس ہوتا ہے لیکن ایسے ٹولز متن، دستاویزات اور فائلوں سے معنی خیز معلومات نکالنا آسان بناتے ہیں۔
کوارٹز کی ڈیٹا کلیننگ گائیڈ صحافیوں کو ایک فریم ورک دیتی ہے جس میں ناقص ڈیٹا معیار، غائب میٹا ڈیٹا اور متضاد ذرائع کی وجوہات بیان کی گئی ہیں اور قابل اعتماد، معنی خیز ڈیٹا سیٹس حاصل کرنے کے طریقے بتائے گئے ہیں۔
یہ مثالیں ظاہر کرتی ہیں کہ ڈیٹا کلیننگ صرف تکنیکی مہارت نہیں ہے۔ یہ قابل بھروسہ صحافت کی طرف ایک بنیادی قدم ہے۔ ذیل میں ہم ڈیٹا کلیننگ کے عمل پر بات کر رہے ہیں۔
ڈیٹا کلیننگ کیا ہے اور یہ کیوں اہم ہے؟
ڈیٹا کلیننگ (یا ڈیٹا رینگلنگ) کا مطلب ایک ڈیٹا سیٹ میں غلطیوں کی نشاندہی اور درستگی کرنا، خالی خانے پر کرنا، ڈپلیکیٹ ہٹانا اور تضادات کو حل کرنا ہے۔ یہ عمل یقینی بناتا ہے کہ ڈیٹا تجزیے اور رپورٹنگ کے لیے قابل اعتماد ہے۔
مثال کے طور پر اگر ایک شہر کے اخراجات کے جدول میں ایک ہی محکمہ کو “Ankara Belediyesi” اور “Ank. Bld.” دونوں ناموں سے دکھایا گیا ہو تو کل اخراجات کا حساب لگانا ناممکن ہو جائے گا۔ اسی طرح تاریخ کے ملے جلے فارمیٹس یا غائب قطاریں گمراہ کن نتائج کی طرف لے جا سکتی ہیں۔ گندا ڈیٹا گندی کہانیاں پیدا کرتا ہے۔ اسی لیے کلیننگ صحافی کی تحقیق میں سب سے اہم لیکن غیر مرئی مراحل میں سے ایک ہے۔
کلیننگ کا بنیادی مقصد ڈیٹا کو تیار کرنا ہے۔ یہ فیصلہ کرنا کہ آپ کو کس ڈیٹا سیٹ کی ضرورت ہے، کون سا فارمیٹ استعمال کرنا ہے، کون سی قطاریں اور کالم درست کرنے ہیں اور (کلیننگ کا) ہر قدم لکھنا ہے۔ عوامل کی نگرانی کرنا، غلطیوں کی جانچ کرنا اور دستاویزات کا ریکارڈ رکھنا ایک پائیدار کام کے عمل کا حصہ ہیں۔
بغیر کوڈنگ کے ڈیٹا کلیننگ
حالیہ برسوں میں صحافیوں کو بصری انٹرفیس کی مدد سے ڈیٹا کو صاف، منظم اور تجزیہ کرنے کے قابل بنانے کے لیے نو-کوڈ ٹولز تیار کیے گئے ہیں۔ پیچیدہ کوڈ لکھنے کے بجائ، یہ ٹولز ڈریگ اینڈ ڈراپ فیچرز، فلٹرز، اور خودکار کلیننگ کی تجاویز فراہم کرتے ہیں جس سے صحافی تکنیکی تفصیلات کے بجائے کہانی سنانے پر توجہ مرکوز کر سکتے ہیں۔
ڈیٹا کلیننگ کے مراحل
کوڈنگ کے بغیر بھی ڈیٹا کلیننگ ایک منطقی ترتیب کے ساتھ کی جانی چاہیے:
- ڈیٹا کو سمجھیں
کلیننگ سے پہلے مشاہدہ کریں۔
کتنے کالم ہیں؟
کیا غائب اقدار موجود ہیں؟
کیا ہجے اور فارمیٹنگ یکساں ہیں؟
کیا تاریخیں ایک ہی فارمیٹ میں ہیں؟
- اصل ڈیٹا کا بیک اپ بنائیں
کلیننگ سے پہلے اصل فائل کی ہمیشہ کاپی بنائیں۔
- ڈپلیکیٹس ہٹائیں
بہت سے ڈیٹا سیٹس میں دہری قطاریں موجود ہوتی ہیں۔
Google Sheets: Data → Remove Duplicates
OpenRefine: Facet → Duplicates
- غائب اقدار کی شناخت کرنا اور ان سے نبٹنا
خالی خانے تلاش کریں۔
قطاریں ختم کریں یا منطقی طور پر غائب اقدار پُر کریں (مثلاً اوپر والے خانوں سے شہر کا نام کاپی کریں)۔
- فارمیٹس کو معیاری بنائیں
کیپٹلائزیشن درست کریں۔
تاریخوں کو ایک فارمیٹ میں تبدیل کریں۔
کرنسی، فیصد وغیرہ کو معیاری بنائیں۔
- زمرہ جات کو ضم کریں
مختلف انداز میں لکھے ہوئے ملتے جلتے زمروں کو اکٹھا کریں۔
“F”, “FEMALE,” “female” → “Female”
- منطقی ہم آہنگی چیک کریں
صاف شدہ ڈیٹا میں بھی غلطیاں ہو سکتی ہیں (مثلاً سال پیدائش ۱۸۹۰ یا ۲۰۶۰ لکھا ہو)۔
- محفوظ کریں اور دستاویز کریں
صاف شدہ ڈیٹا سیٹ کو علیحدہ محفوظ کریں (مثلاً city_expenses_cleaned.csv)۔
شفافیت کے لیے تمام کلیننگ اقدامات کو لکھ لیں۔
تصور کریں کہ ۲۰۲۵ میں ایک شہر کے اخراجات کی ایکسل فائل درج ذیل مسائل کے ساتھ ڈاؤن لوڈ کی گئی ہے۔
Date |
Department |
Expense Item |
Amount |
12/01/24 |
Financial Affairs |
Cleaning Service |
25000 |
13.01.2024 |
FINANCIAL AFFAIRS |
CLEANING |
25.000,00 TL |
15/01/24 |
F.Affair |
Garbage Collection |
12.5 |
16/01/2024 |
Financialaffairs |
CLEANING SERVICE |
25,000 |
مثال: کسی شہر کے اخراجات کے ڈیٹا کی کلیننگ
مسائل:
تاریخیں مختلف فارمیٹس میں ہیں۔
شعبہ جات کے نام غیر مستقل ہیں۔
رقمیں مختلف فارمیٹس میں ہیں۔
کلیننگ کے اقدامات:
تمام تاریخیں ایک فارمیٹ میں تبدیل کریں۔
شعبہ جات کے نام اوپن ریفائن کے “Cluster & Edit” کی مدد سے ایک معیار کے مطابق بنائیں۔ → “Financial Affairs”
تمام رقوم کو ایک عددی فارمیٹ میں تبدیل کریں۔
کلیننگ کے بعد ڈیٹا تجزیہ کے لیے تیار ہے: اخراجات کی درجہ بندی کریں، انہیں جمع کریں اور رجحانات کو بصری شکل میں لائیں۔
ڈیٹا کلیننگ کے جانے مانے ٹولز
ذیل میں صحافیوں کے لیے قابل رسائی اور عملی ٹولز ان کے فوائد کے ساتھ بتائے گئے ہیں۔
یہ ڈیٹا کلیننگ کے لیے آسان ترین ٹولز میں سے ایک ہے۔ اس کے اسپریڈ شیٹ کے ماحول میں جس سے سب واقف ہیں، سادے فارمولوں اور فلٹرز کی مدد سے طاقتور کلیننگ کے کام کیے جا سکتے ہیں۔
استعمال: ڈپلیکیٹ قطاریں حذف کرنا، متن کے فارمیٹ درست کرنا اور تاریخوں کو ایک معیار کے مطابق درج کرنا۔
آسان ترین ٹولز میں سے ایک، سب سے زیادہ لوگ اسے جانتے ہیں۔
استعمال: ڈپلیکیٹ قطاریں حذف کرنا، ٹیکسٹ فارمیٹس درست کرنا، تاریخوں کو معیاری بنانا۔
مثال:
=TRIM(A2) → سیل میں موجود غیر ضروری اسپیس ہٹاتا ہے
=PROPER(A2) → انگریزی میں لکھے بڑے اور چھوٹے حروف کو درست کرتا ہے
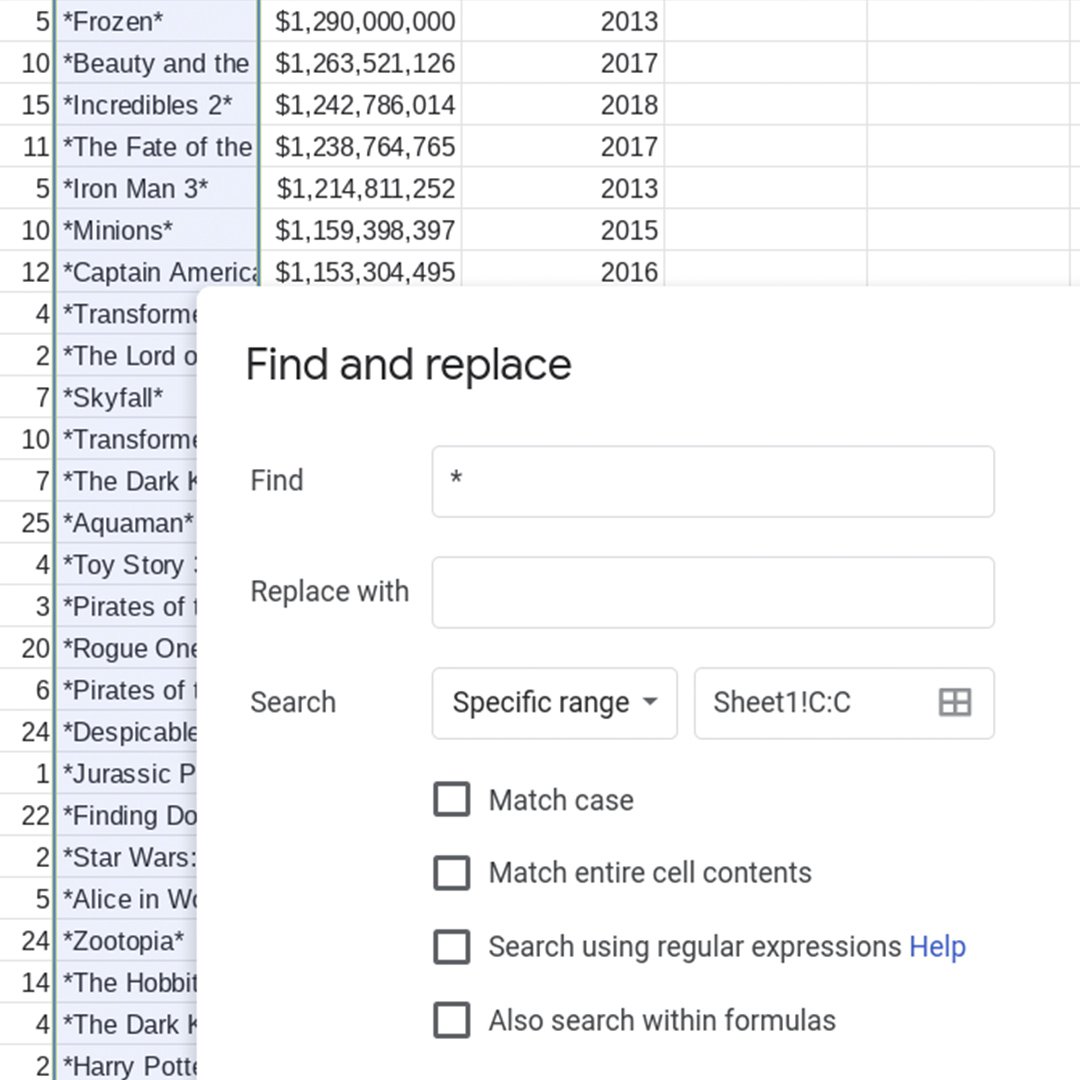
ڈیٹا ٹیب میں ریموو ڈپلیکیٹ ٹول دہری قطاروں کی نشاندہی کرتا ہے۔
فائدہ: مفت، کلاؤڈ بیسڈ، آسانی سے شیئر کیا جا سکتا ہے
نقصان: بڑے ڈیٹا سیٹس میں سست ہو سکتا ہے
اسی موضوع پر میرا جی آئی جے این کے لیے ایک دوسرا مضمون اور میری ریکارڈنگز جو ترکش زبان میں ہیں لیکن سب ٹائٹلز کی مدد سے سمجھی جا سکتی ہیں۔
میرا ڈیٹا گندا ہے! اسپریڈ شیٹ کی صفائی کے بنیادی کام
#2.1 گوگل ای تا ب لولار اِلے ویری تَیمیز لَمہ
#3.1 گوگل تا ب لولار اِلے ویری دُوزین لَمہ وَ پیووٹ تا ب لو کُلانِمِ
اوپن ریفائن
اوپن ریفائن ڈیٹا صحافیوں میں سب سے زیادہ استعمال ہونے والا مفت ڈیٹا کلیننگ ٹول ہے۔ پہلے "گوگل ریفائن” کے نام سے جانا جانے والا یہ اوپن سورس پروگرام سیکنڈوں میں ڈیٹا کی ہزاروں قطاروں کو منظم کر سکتا ہے۔ میں اپنی کلاسوں میں باقاعدگی سے اس کا استعمال کرتی ہوں۔
- استعمال: یہ آپ کو ڈپلیکیٹ ریکارڈز کو یکجا کرنے، متن کے فارمیٹس کو ایک جیسا کرنے، کالمز تبدیل کرنے کے علاوہ بھی بہت کچھ کرنے کی سہولت دیتا ہے۔
- نمایاں خصوصیت: اس کی "کلسٹر اینڈ ایڈٹ” ملتے جلتے سپیلنگ کو خود کار طریقے سے اکٹھا کرتی ہے۔
Image: Screenshot
مثال کے طور پر آپ “Istanbul”، “İstanbul” اور “Ist” جیسے ریکارڈز کو ایک ہی معیاری شکل میں تبدیل کر سکتے ہیں۔
ڈیٹا کی اقسام: CSV، TSV، Excel، JSON، XML
فائدہ: کلیننگ کے پیچیدہ کاموں کو سادہ بناتا ہے اور طاقتور فلٹرنگ مہیا کرتا ہے۔
نقصان: پہلی بار سیٹ اپ کرتے ہوئے ذرا تکنیکی لگتا ہے لیکن چند مثالوں کی مدد سے اسے سیکھنا آسان ہے۔
میرا تربیتی ریکارڈ جو ترکی زبان میں ہے لیکن سب ٹائٹلز کی مدد سے سمجھا جا سکتا ہے:
#2.2 اوپن ریفائن اِلے ویری تَیمیز لَمہ
ایکسل پاور کویری
مائیکروسافٹ ایکسل کا پاور کوئری ایڈ ان ایکسل کے روائیتی صارفین کو بہت سہولت فراہم کرتا ہے۔
استعمال: یہ آپ کو عوامل جیسے متعدد فائلوں کو ملانے، کالمز کو دوبارہ فارمیٹ کرنے اور ٹیکسٹ کو تبدیل کرنے کی سہولت فراہم کرتا ہے۔
خصوصیت: یہ تمام عوامل کا ریکارڈ رکھتا ہے۔ آپ کو نئے ڈیٹا پر ان کلیننگ کے مراحل کو خود کار طریقے سے لاگو کرنے میں مدد دیتا ہے۔ِ
فائدہ: ایکسل صارفین کے لیے ایک قدرتی تبدیلی ہے۔
نقصان: پرانے ورژنز میں اس کی سپورٹ محدود ہے اور بعض صورتوں میں ادا شدہ لائسنس کی ضرورت پڑ سکتی ہے۔
ایکسل میں پاور کیوری کی مدد سے ہر چیز کو خود کار کرنا سیکھیں
ائیر ٹیبل
ایر ٹیبل اسپریڈ شیٹ اور ڈیٹا بیس کے درمیان ایک ہائبرڈ نظام ہے۔ صارفین ڈیٹا کو بصری انداز میں منظم کر سکتے ہیں، اس کی درجہ بندی کر سکتے ہیں اور ایک دوسرے سے منسلک ٹیبلز بنا سکتے ہیں۔
استعمال: ماخذ ڈیٹا کو منظم کرتا ہے، ڈیٹا کی درستگی برقرار رکھتا ہے اور خبریں ٹریک کرنے کے لیے ٹیبلز بناتا ہے۔
خصوصیات: فلٹرنگ، کلر کوڈنگ، لنکنگ (مثلاً شخص اور ادارے کے مابین روابط)۔
فائدے: ٹیم ورک کے لیے موزوں، بصری لحاظ سے دلکش اور استعمال میں آسان۔
نقصانات: مفت ورژن میں محدود اسٹوریج دستیاب ہے۔
ائیر ٹیبل میں خودکار ڈیٹا صفائی کے طریقے کیسے قائم کیے جائیں
ٹرائی فیکٹا رینگلر (آلٹی ریکس کلائوڈ)
یہ ادارہ جاتی سطح پر ڈیٹا کلیننگ کا ایک طاقتور ٹول ہے۔ یہ اے آئی کی مدد سے (کلیننگ کی) سفارشات دیتا ہے؛ یہ خود ڈیٹا میں غلطیاں تلاش کرتا ہے اور ان کی درستگی کی آپشن دیتا ہے۔
استعمال: بڑے ڈیٹا سیٹس کی صفائی، خودکار تبدیلی۔
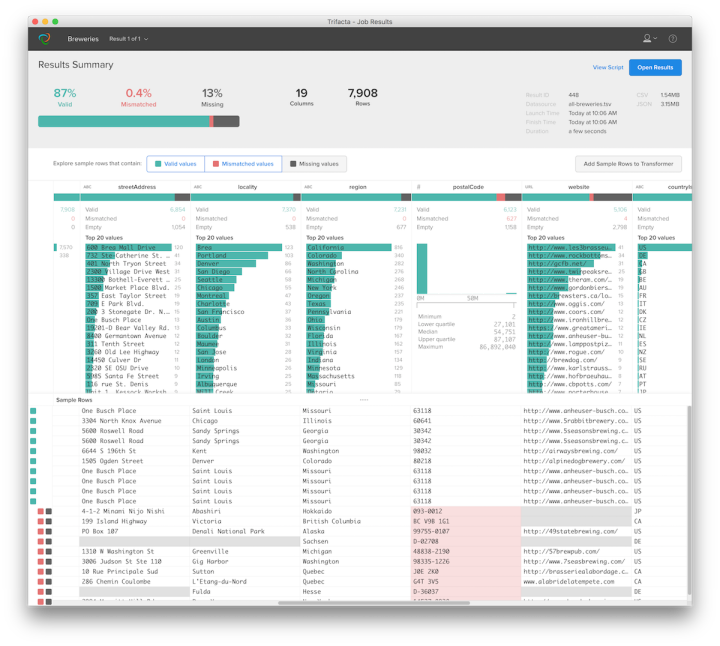
Image: Screenshot
فائدہ: وقت بچاتا ہے، پیچیدہ ڈیٹا سورس میں مدد فراہم کرتا ہے۔
نقصان: ادائیگی شدہ ورژن پر زیادہ زور دیا جاتا ہے، انٹرفیس انگریزی میں ہے۔
ٹیبولا (پی ڈی ایف کے لیے)
ٹیبولا پی ڈی ایف فائلوں میں بند ڈیٹا ٹیبلز کو آزاد کرنے والا ایک ٹول ہے۔ یہ صحافیوں کو پیش آنے والا ایک عام مسئلہ ہے: سرکاری ادارے پی ڈی ایف فارمیٹ میں ڈیٹا فراہم کرتے ہیں۔
ٹیبولا پی ڈی ایف فائلوں میں موجود ٹیبلز کو ایکسل یا سی ایس وی فارمیٹ میں تبدیل کرتا ہے۔
استعمال کا مقصد: پی ڈی ایف سے ٹیبلز علیحدہ کرنا۔
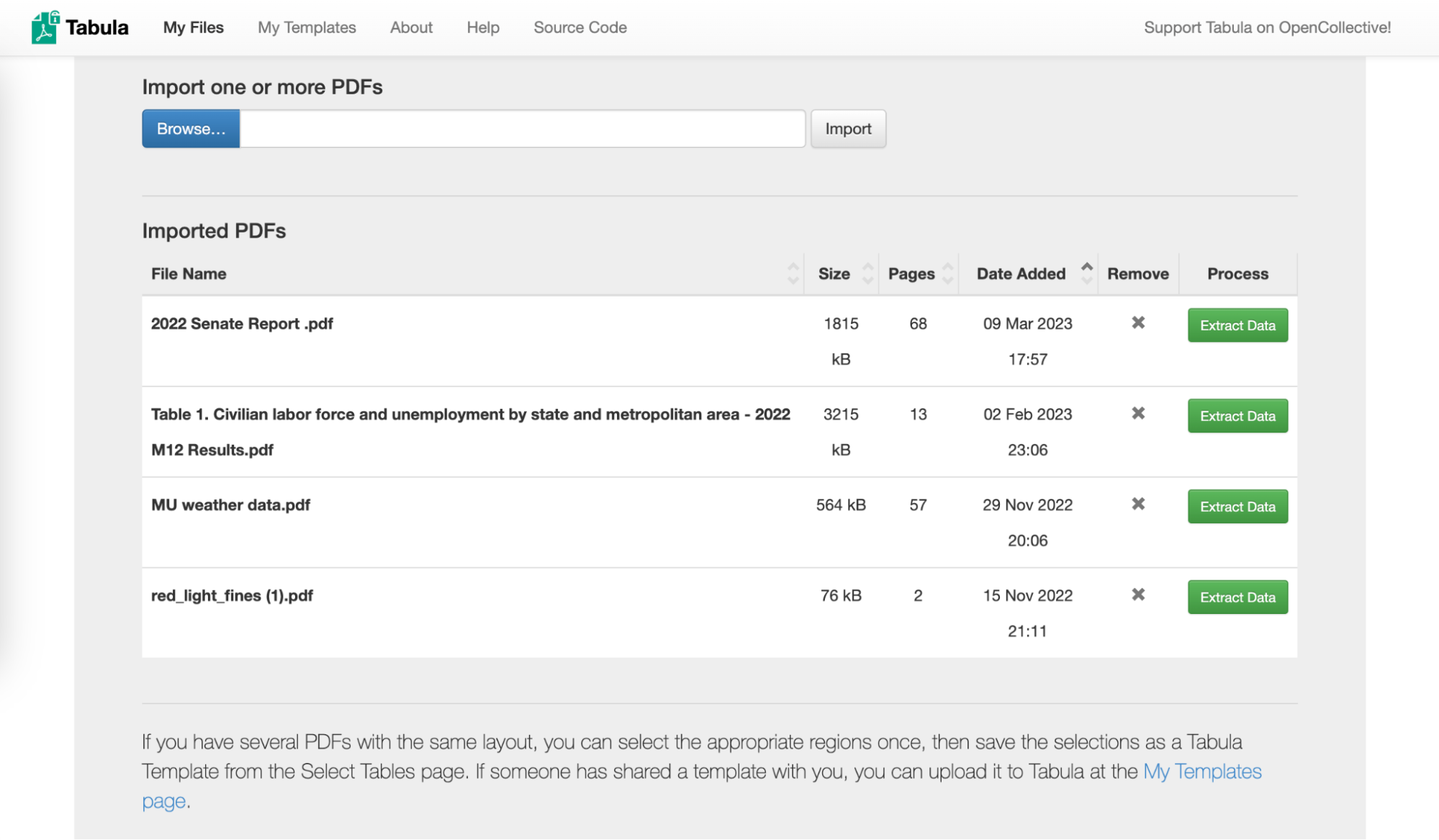
Image: Screenshot
فائدہ: مفت، اوپن سورسِ
نقصان: پیچیدہ یا بصری پی ڈی ایف فائلوں میں غلطیاں پیدا ہو سکتی ہیں۔
میرا تربیتی ریکارڈ یہاں موجود ہے: #1.2 تابولا اِلے پی ڈی ایف دُوسیہ لارِندن ویری کَزِما
کوڈ کے بغیر ڈیٹا کلیننگ کی جدید تراکیب
فلٹرنگ اور شرط کی بنیاد پر صفائی
گوگل شیٹس یا ایکسل میں آپ کنڈیشنل فارمیٹنگ استعمال کر کے غیر معمولی اقدار کو رنگوں کی مدد سے نمایاں کر سکتے ہیں اور غلطیوں کو جلدی دیکھ سکتے ہیں۔ِ
فارمولوں کے ذریعے خودکار صفائی
صفائی کا عمل کوڈ کے بجائے سادہ فارمولوں کے ذریعے خودکار بنایا جا سکتا ہے۔
=UNIQUE(A:A) شرف ایک بار درج اقدار دکھاتا ہے۔
=CLEAN(A2) پوشیدہ حروف ہٹا دیتا ہے۔
=SUBSTITUTE(A2, “,”, “.”) کوما اور ڈاٹ کے فرق کو درست کرتا ہے۔
ڈیٹا کی تصدیق کرنا
ایئر ٹیبل یا شیٹس میں آپ یہ یقینی بنا سکتے ہیں کہ صارفین صرف مخصوص زمرے میں ہی ڈیٹا داخل کریں۔ یہ طویل مدت میں ڈیٹا کی مطابقت کو برقرار رکھتا ہے۔
بہترین طریقے اور اخلاقیات
ڈیٹا کلیننگ صرف تکنیکی کام نہیں ہے بلکہ اخلاقی عمل بھی ہے۔ صحافیوں کو درستگی اور تسلسل کا دھیان رکھتے ہوئے اصل معنی برقرار رکھنا چاہیے۔
شفافیت: صفائی کے اقدام کو نوٹ کریں۔
اصل کو محفوظ رکھیں: خام ڈیٹا سنبھال کر رکھیں۔
دہرائے جانے کی صلاحیت: اپنے تمام مراحل کو دستاویز کریں تاکہ دوسرے لوگ بھی آپ کے کام کو دہرا سکیں۔
اندازہ نہ لگائیں: اگر کوئی قدر غائب ہو تو اسے “نامعلوم” لکھیں۔
ڈیٹا جرنلزم اور تحقیقاتی رپورٹنگ صرف تکنیکی مہارتوں کے بارے میں نہیں ہیں۔ ڈیٹا کو سمجھنا، اسے منظم کرنا اور اس کی تصدیق کرنا براہِ راست آپ کی خبروں کی درستگی کو متاثر کرتا ہے۔ نئے ٹولز ایسے صحافیوں کے لیے بھی ڈیٹاصاف کرنا ممکن بناتے ہیں جو کوڈنگ نہیں جانتے۔ اپنے آپ کوکہانی گو سمجھیں، انجینئیر نہیں لیکن یاد رکھیں: ہر مضبوط کہانی مضبوط ڈیٹا پر انحصار کرتی ہے۔ درست ٹولز اور طریقوں کےساتھ کوڈنگ نہ جاننے والے صحافی بھی ڈیٹا صاف کر سکتےہیں اور اسے قابل اعتماد خبر میں بدل سکتے ہیں۔
 پینار داگ جی آئی جے این ترکی کی مدیر ہیں اور کادیر خاص یونیورسٹی میں لیکچرار ہیں۔ وہ ڈیٹا لٹریسی ایسوسی ایشن، ڈیٹا جرنلزم پلیٹ فارم ترکی اور داگ میڈیا کی شریک بانی ہیں۔ وہ ڈیٹا لٹریسی، اوپن ڈیٹا، ڈیٹا ویژولائزیشن اور ڈیٹا جرنلزم پر کام کرتی ہیں اور ۲۰۱۲ سے ان موضوعات پر ورکشاپس منظم کر رہی ہیں۔ وہ سگما ڈیٹا جرنلزم ایوارڈز کی جیوری کا بھی حصہ ہیں۔
پینار داگ جی آئی جے این ترکی کی مدیر ہیں اور کادیر خاص یونیورسٹی میں لیکچرار ہیں۔ وہ ڈیٹا لٹریسی ایسوسی ایشن، ڈیٹا جرنلزم پلیٹ فارم ترکی اور داگ میڈیا کی شریک بانی ہیں۔ وہ ڈیٹا لٹریسی، اوپن ڈیٹا، ڈیٹا ویژولائزیشن اور ڈیٹا جرنلزم پر کام کرتی ہیں اور ۲۰۱۲ سے ان موضوعات پر ورکشاپس منظم کر رہی ہیں۔ وہ سگما ڈیٹا جرنلزم ایوارڈز کی جیوری کا بھی حصہ ہیں۔

صحافیوں کے لیے ٹِپ شیٹ: او سی سی آر پی کے ایلیف سے فائدہ کیسے اٹھائیں

گوگل شیٹس کی بنیادی باتوں پر صحافیوں کے لیے مرحلہ وار گائیڈ

قدرتی آفت کے بعد پوچھے جانے والے 10 تفتیشی سوالات

واشنگٹن آپ کے ملک میں کیا کر رہا ہے: دنیا بھر میں امریکی اثر و رسوخ کی تحقیق کے لیے ایک ٹپ شیٹ
انتخابات کے ڈیٹا کو دیکھنے کے لیے فلرش استعمال کرنے کے لیے ٹپس

فارماسیوٹیکل اجارہ داریوں کی تحقیق کیسے کی جائے

نیوز رومز اے آئی چیٹ بوٹس کو کس طرح اپنی رپورٹنگ بڑھانےاور اعتماد قائم کرنے کے لیے استعمال کر رہے ہیں

میکسکو، پیرو، نائیجریا اور مصر ست گلوبل شائینگ لائٹ آورڈ جیتنے والی دلیر تحقیقات

اس کام کا کریٹیو کامنز لائسنس ہے کریٹیو کامنز آٹریبیوشن - نو ڈیریوٹو 4.0 عالمی لائسنس
ہمارے مضامین کو تخلیقی العام لائسنس کے تحت مفت، آن لائن یا پرنٹ میں دوبارہ شائع کریں۔
اس آرٹیکل کو دوبارہ شائع کریں
اس کام کا کریٹیو کامنز لائسنس ہے کریٹیو کامنز آٹریبیوشن - نو ڈیریوٹو 4.0 عالمی لائسنس
اگلی کہانی پڑھیں
ڈیٹا پر مبنی صحافت رپورٹنگ تجاویز اور ٹولز طریقہ کار
انتخابات کے ڈیٹا کو دیکھنے کے لیے فلرش استعمال کرنے کے لیے ٹپس
فلرش کے حالیہ ویبنار میں، ڈیٹا صحافی میفے کالیہون نے پولنگ یا انتخابی نتائج سے ایک انٹرایکٹو نقشہ بنانے کے لیے ضروری تجاویز کا اشتراک کیا۔
فارماسیوٹیکل اجارہ داریوں کی تحقیق کیسے کی جائے
پیرو کی تفتیشی صحافی فابیولا ٹوریس نامہ نگاروں کو دکھاتی ہیں کہ فارما کی اجارہ داریوں کے پیچھے موجود نظاموں کو کیسے بے نقاب کیا جائے، اور مارکیٹ کے ڈھانچے کو انسانی اثرات سے کیسے جوڑا جائے۔
نیوز رومز اے آئی چیٹ بوٹس کو کس طرح اپنی رپورٹنگ بڑھانےاور اعتماد قائم کرنے کے لیے استعمال کر رہے ہیں
فلپائن سے لے کر برطانیہ تک، بہت سے بڑے نیوز رومز نے اپنے آے آئی چیٹ بوٹس بنائے ہیں جو صرف اس سائٹ کے قابل اعتماد رپورٹنگ آرکائیو اور جانچ شدہ ڈیٹا بیس کو بطور ماخذ مواد استعمال کرتے ہوئے جواب دینے کے لیے ڈیزائن کیے گئے ہیں۔
آوارڈز
میکسکو، پیرو، نائیجریا اور مصر ست گلوبل شائینگ لائٹ آورڈ جیتنے والی دلیر تحقیقات
یہ تینوں فاتحین اور خصوصی اقتباس حاصل کرنے والے ترقی پذیر یا منتقلی والے ممالک کی شاندار صحافت کی نمائندگی کرتے ہیں، جو خطرے میں یا خطرناک حالات میں انجام دی گئی ہیں۔