
Boîte à Outils : extraire des données sans savoir coder
Lire cet article en

Guide d’enquête sur le crime organisé en Afrique

Recherches sur Google : les conseils de Henk van Ess, spécialiste du journalisme en sources ouvertes
Outils de télédétection et bases de données pour enquêter sur l’environnement
Comment utiliser l’outil “Wayback Machine” pour votre prochaine enquête
Dans la boîte à outils de GIJN nous passons en revue les outils utiles aux journalistes d’investigation. Découvrez dans cet article trois solutions gratuites et faciles à utiliser pour extraire les données contenues dans des documents. Ces techniques ont été présentées lors de la récente 2022 Investigative Reporters & Editors Conference (IRE22) où elles ont suscité l’enthousiasme et l’approbation des journalistes présents.
Quand les journalistes obtiennent enfin les documents dont ils ont besoin pour leurs enquêtes, ils sont souvent confrontés à une deuxième difficulté : comment sélectionner et extraire les données pour qu’elles puissent être utilisées et copiées dans des tableurs ? Pour beaucoup de petites rédactions, la saisie manuelle, le codage avancé ou les services onéreux de reconnaissance optique de caractères (ROC) ne sont pas des options réalistes.
Par ailleurs, plusieurs journalistes ‘sentinelles’ expérimentés qui assistaient à la![]() conférence IRE22 ont fait remarqué qu’ils constataient non seulement une augmentation du nombre de documents publics publiés dans des formats non structurés ou “à mise en page fixe” – comme les documents scannés ou les PDF “aplatis” – mais aussi que certaines agences gouvernementales utilisaient délibérément ces formats pour compliquer l’accès aux données, et donc les reportages.
conférence IRE22 ont fait remarqué qu’ils constataient non seulement une augmentation du nombre de documents publics publiés dans des formats non structurés ou “à mise en page fixe” – comme les documents scannés ou les PDF “aplatis” – mais aussi que certaines agences gouvernementales utilisaient délibérément ces formats pour compliquer l’accès aux données, et donc les reportages.
Les journalistes doivent enfin relever un dernier défi : un grand nombre d’agences gouvernementales demandent aux reporters de rechercher par eux-mêmes sur les pages web les données souhaitées, ce qui nécessite de copier et de coller des cases individuelles dans des tableaux, puis de cliquer manuellement sur de nombreux onglets ou fiches pour arriver à la fin du fichier.
“Je demande énormément de documents du service public et je constate qu’il est désormais très rare qu’on m’envoie le document ou les données au format que j’ai demandé”, a dit Kenny Jacoby, journaliste d’investigation à USA Today, qui a présenté plusieurs outils PDF lors de la conférence. “On a parfois l’impression que l’agence gouvernementale qui vous fournit le document fait tout pour vous rendre la vie impossible, par exemple en supprimant le texte d’un document en PDF, en le scannant avant de l’envoyer, ou en mettant les données dans un format non structuré, sans lignes ni colonnes. Ces entraves peuvent nous ralentir considérablement, alors il est important de disposer d’outils pour les contourner.”
Google Pinpoint — et ses nouvelles fonctionnalités pour venir à bout des PDF
En 2020, GIJN a été parmi les premiers à annoncer la mise en service d’un nouvel outil d’analyse de document utilisant l’intelligence artificielle, conçu par le Google Journalist Studio et désormais disponible sous la marque “Pinpoint”. À l’époque, nous avions décrit ce nouvel outil comme une fonction “Ctrl-F à turbocompresseur” présentant une ROC avancée qui pouvait effectuer des recherches dans des quantités impressionnantes de documents et d’images. Lors d’une présentation sur les données qui s’est tenue dans le cadre de la conférence IRE22, Jacoby a indiqué que Pinpoint est devenu depuis un outil numérique gratuit, d’accès facile, en partie grâce aux contributions de journalistes d’investigation auprès des concepteurs de l’outil.
Jacoby a montré que les fonctionnalités de données comprennent désormais les caractéristiques suivantes :
- Si vous recherchez un seul mot clé – par exemple, “faculté” – non seulement Pinpoint réussira à trouver ce mot partout où il se trouve dans votre fichier de recherche téléchargé, mais il affichera aussi en surbrillance les mots connexes, comme “enseignant”, “campus” ou “professeur”. Il trouvera aussi les variations de conjugaison pour le terme recherché ; il fonctionne dans sept langues, notamment le français, l’espagnol, le portugais et le polonais ; et il est possible d’exclure les termes non désirés en ajoutant le signe “moins”.
- Téléchargez le nombre de documents que vous voulez, scannés ou en format PDF – ou même des pages de texte écrit à la main – et l’outil peut rapidement les transformer en texte “dynamique” dans lequel vous pourrez faire des recherches et du copier-coller. Cet outil est même capable de lire des mots écrits autrement qu’horizontalement.
- Cet outil peut non seulement reconnaître et transformer en texte la signalisation et les graffitis qui se trouvent sur des photos, mais il peut aussi reproduire de longs passages rédigés en lettres minuscules qu’il identifie sur des plaques ou des panneaux d’affichage en arrière-plan. (Certains des journalistes qui assistaient à la démonstration ont littéralement poussé un cri de surprise quand ils ont vu Pinpoint réussir à lire et à traiter les lettres minuscules qui se trouvaient sur une plaque biographique que l’on voyait de biais sur une photo. Une journaliste de NBC Telemundo, Valezka Gil, s’est exclamée : “Incroyable ! Vous venez de me changer la vie. Cela va me permettre de gagner un temps fou.”)
- Jacoby indique que la fonctionnalité de transcription audio et video est maintenant tellement avancée qu’il utilise l’outil gratuit Pinpoint plutôt que des services de transcription spécialisés comme Trint ou Otter – qui comportent des frais d’abonnement peu élevés – pour créer des transcriptions de ses interviews audio dans lesquelles il peut effectuer des recherches. “Cette fonctionnalité est identique aux outils payants, mais elle est gratuite”, a-t-il indiqué. “Mais il y a une chose qu’elle ne fait pas, contrairement à Trint et Otter : identifier la personne qui s’exprime et assigner un nom à chaque personne, par exemple ‘Intervenant 2’. Elle identifie toutefois les pauses logiques dans une conversation, ainsi que les inflexions dans la voix. Il vous suffit de cliquer sur un point particulier dans la transcription du texte et vous entendrez l’enregistrement défiler à partir de ce point donné.”
Jacoby a indiqué que l’accès gratuit aux fonctionnalités de Pinpoint est maintenant très simple, et qu’il est possible de demander de l’espace supplémentaire à ses techniciens pour stocker des données volumineuses.
“Il est vrai qu’il vous faut une autorisation pour l’utiliser, mais quand nous nous sommes inscrits, moi et mon épouse – elle est aussi journaliste – on nous a délivré une autorisation presque instantanément”, a-t-il fait remarquer. “Il vous faudra peut-être une adresse mail professionnelle, mais il n’est pas compliqué de s’inscrire, et l’équipe est très réactive.”
Seul bémol : Pinpoint est un service exclusivement en ligne.
“Cela signifie qu’il vous faut une connexion Internet et que vous devez télécharger vos documents sur un serveur, quelque part. Ainsi, si Google était assigné à comparaître, il est possible que vos documents soient remis à la justice”, a-t-il averti. “Par ailleurs, cet outil ne vous permet pas d’enregistrer le document ROC obtenu, qui ne se trouve que sur Pinpoint. Vous devez donc copier-coller le texte. Mais Pinpoint possède probablement la meilleure ROC qui existe.”
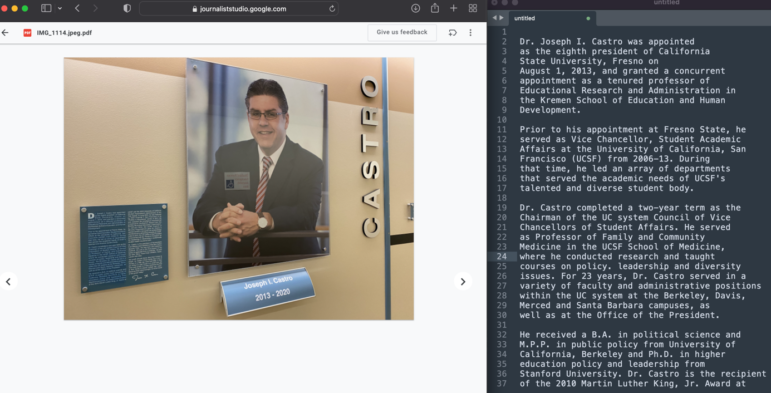
Les journalistes qui ont assisté à la conférence IRE22 ont été stupéfaits d’apprendre que la fonctionnalité de reconnaissance optique de caractère (ROC) de l’outil gratuit, Google Pinpoint, est assez puissante pour lire et transcrire des textes rédigés avec des lettres aussi petites que celles qui figurent sur la plaque biographique sur cette photo. Image : Kenny Jacoby
Formules ImportHTML et ImportXML pour les données des sites web
Comme Craig Silverman, de ProPublica, en a récemment fait la démonstration pour GIJN, le code source de tout site web propose une pléthore d’outils de recherche aux journalistes d’investigation et, en dépit de son aspect impressionnant pour les personnes qui ne s’y connaissent pas en codage, ce code ne demande aucune compétence particulière hormis le fait de savoir à quoi correspondent “Contrôle-F” ou “Commande-F”, pour naviguer.
Lors d’une présentation sur la récupération de données avec Google Sheets qui s’est tenu dans le cadre de la conférence IRE22, la journaliste indépendante Samantha Sunne a fait une démonstration sur la manière dont ce code peut aussi être utilisé pour capturer facilement de long tableaux ou des données spécifiques sur des sites web et – en quelques secondes – mettre toutes ces données dans un tableur au format qui vous convient. Il n’est pas nécessaire de copier et de coller individuellement le contenu de centaines de cases dans votre fichier. La technique implique une formule pour donner des instructions à Google Sheets — dans la première case, en haut à gauche — afin que cet outil puisse extraire un élément de code source dont vous avez besoin sur une page web (le code qui permet de construire, par exemple, un tableau de données qui vous a plu sur cette page web).
En fait, vous n’avez pas vraiment besoin de chercher un code particulier pour extraire un tableau de données bien formaté de n’importe quel site. Il vous suffit de suivre ces étapes :
Pour importer un tableau de données d’une page web, quelle que soit sa longueur, tapez tout simplement cette formule dans Google Sheets : =IMPORTHTML(“URL”, “table”). Si les données sont sous forme de liste, essayez “list” au lieu de “table” et, si vous voulez, par exemple, la liste suivante qui figure sur une page, essayez d’ajouter le chiffre 2 après une virgule et un espace : =IMPORTHTML(“URL”, “list”, 2)
Quand GIJN a essayé cet outil pour importer un tableau comportant les noms de 564 banques en difficulté à partir du site web de l’organisme américain de garantie des déposants, la Federal Deposit Insurance Corp., le processus — copier l’URL de la FDIC URL, ouvrir Google Sheets et visualiser la liste entière de banques parfaitement formatée en colonnes – a pris en tout et pour tout moins de 15 secondes. Toutefois, il est important d’utiliser la bonne ponctuation pour la formule, notamment en ajoutant une virgule après l’URL ainsi que des guillemets avant et après les deux éléments entre parenthèses. Par ailleurs – et c’est très appréciable – toute mise à jour des données de ce site web dynamique apparaîtra aussi automatiquement dans la Google Sheet. Ainsi, vous n’aurez pas à vérifier constamment la page pendant votre enquête, sauf si vous avez désactivé la fonctionnalité de mise à jour.
Samantha Sunne a toutefois ajouté qu’il était également important que les reporters se familiarisent, ne serait-ce qu’un minimum, avec le format html pour avoir une idée de la manière dont sont mises en forme les données que nous voyons sur les pages web. Cela leur permettra d’exploiter des informations formatées de manière imparfaite et de faire des recherches bien plus approfondies avec des formules avancées.
Pour trouver le code qui construit toute page web, il vous suffit de cliquer avec le bouton droit de la souris sur n’importe quel espace vide ou blanc sur un site, puis de cliquer sur “view page source” ou “show page source.” En général, a-t-elle ajouté, il est important de garder à l’esprit que les mots que l’on voit sur la page web doivent aussi apparaître sur la page de code source de l’ordinateur, afin que vous puissiez tout simplement faire “Ctrl-F” pour trouver n’importe quel terme de donnée dans ce code, voir quelles balises sont utilisées pour le saisir, et faire des essais avec ces balises dans la formule.
“Même si elle est utile, la formule ImportHTML ne peut rechercher que les tableaux et les listes. Mais il y a une autre formule, ImportXML, qui peut rechercher n’importe quel élément html”, a expliqué Sunne. “Elle lui ressemble beaucoup – le signe “égal” ; le nom de la formule, l’URL – mais vous pouvez être beaucoup plus précis.” Voici comment procéder :
Pour importer des éléments spécifiques de données spécifiques sur une page web – comme des lignes dans un tableau, ou uniquement les caractères en gras, ou les rubriques – essayez une formule comme celle-ci (pour un exemple de rubriques de données) : =IMPORTXML(“URL”, “//h2”) , ou ceci (pour les lignes d’un tableau) : =IMPORTXML(“URL”, “//table/tr”)
Il y a beaucoup d’éléments html fréquemment utilisés, comme “//h2” (en-tête) et “/tr” (ligne dans un tableau) – que l’on peut trouver dans les dictionnaires html – mais Sunne recommande aux journalistes de prendre simplement note des éléments qui entourent les données dont ils ont besoin et d’identifier les balises clés du jargon informatique qui peuvent les aider à affiner les importations de données. Pour vous entraîner, essayez d’utiliser ces deux techniques de récupération de données sur de longs sites sur Wikipedia, qui comportent généralement plusieurs listes et tableaux de données.
Tesseract, avec ImageMagick, pour extraire des données hors ligne en toute sécurité
Kenny Jacoby, de USA Today, a indiqué qu’un moteur de ROC en source ouverte appelé Tesseract propose une solution très performante d’extraction de données pour les documents sensibles ainsi que pour les archives de données qui sont immenses, si la qualité des données saisies est suffisamment bonne. Par ailleurs – et c’est très appréciable – sa dernière version en date reconnaît aussi plus de 100 langues, ainsi que les textes écrits de droite à gauche en hébreu ou en arabe.
Tesseract convertit des images sans calque de texte en documents PDF sélectionnables, dans lesquels vous pourrez effectuer des recherches. Jacoby a ajouté que cet outil est particulièrement performant quand il s’agit de convertir des lots importants de documents “plats” en texte dynamique qui peut être copié et collé. Il a précisé que cela implique de convertir au préalable les documents PDF en images à haute résolution – dans l’idéal, en utilisant l’outil ImageMagick tool en source ouverte – puis de les transférer dans Tesseract pour obtenir les données récupérées.
“Sa ROC n’est pas aussi performante que Pinpoint, mais elle n’est pas mal du tout”, a ajouté Jacoby. “Un avantage de taille, toutefois, c’est que cet outil est hors ligne : vous pouvez tout faire sur votre ordinateur, donc cet outil est tout indiqué pour les travaux sensibles. Il est vraiment performant pour les conversions par lot ; vous pouvez par exemple appliquer la ROC à chaque document d’un lot de 1000.”
Il a précisé : “Vous devrez peut-être améliorer la qualité de l’image ou le contraste, mais avec ImageMagick, vous pouvez accroître la qualité de l’image.”
Par ailleurs, Jacoby a recommandé le guide détaillé sur les outils Tesseract et ImageMagick rédigé par le journaliste d’investigation Chad Day, du Wall Street Journal, que vous trouverez ici sur Github.
La solution Tesseract requiert des compétences “intermédiaires” en codage, mais Jacoby a indiqué que cette question peut être réglée en une fois : une personne compétente peut installer le programme lors d’une visite et fournir au journaliste deux courtes lignes de code qu’il pourra utiliser par la suite pour chaque extraction de données. Pour extraire des tableaux imprimés en format PDF, Jacoby a recommandé l’appli Tabula – un outil en source ouverte bien connu qui a été créé par des journalistes de OpenNews et de ProPublica. “En substance, il libère les tableaux de données du format PDF et les transfère dans des tableurs”, a-t-il expliqué.
Avec Tabula, les reporters peuvent tout simplement dessiner un cadre autour d’un tableau sur leurs écrans d’ordinateur pour extraire les données qui les intéressent. Cet outil peut aussi détecter des tableaux de manière automatique, notamment ceux qui n’ont pas de bordure. Tabula nécessite des documents “dynamiques” ou passés par la ROC, mais Jacoby a souligné que cet outil fonctionne bien avec des fichiers texte créés par Tesseract. “L’outil peut aussi être utilisé hors ligne, ce qui signifie que vous pouvez travailler en toute discrétion”, a-t-il fait remarquer.
Ressources complémentaires
Comment créer votre propre base de données
Découvrir les liens entre différents sites webs avec SpyOnWeb, VirusTotal et SpiderFoot HX
Les meilleurs outils pour collecter des données exclusives
 Rowan Philp est journaliste à GIJN. Auparavant, Rowan a été reporter en chef pour le Sunday Times sud-africain. En tant que correspondant à l’étranger, il a réalisé des reportages sur l’actualité, la politique, la corruption et les conflits dans plus de vingt pays dans le monde entier.
Rowan Philp est journaliste à GIJN. Auparavant, Rowan a été reporter en chef pour le Sunday Times sud-africain. En tant que correspondant à l’étranger, il a réalisé des reportages sur l’actualité, la politique, la corruption et les conflits dans plus de vingt pays dans le monde entier.
Guide d’enquête sur le crime organisé en Afrique
Recherches sur Google : les conseils de Henk van Ess, spécialiste du journalisme en sources ouvertes
Outils de télédétection et bases de données pour enquêter sur l’environnement
Comment utiliser l’outil “Wayback Machine” pour votre prochaine enquête

« La recherche de preuves » : Ce qui a attiré les femmes datajournalistes de premier plan vers ce domaine

10 erreurs courantes dans le data-journalisme

8 méthodes pour consulter gratuitement les publications scientifiques et universitaires

Astuces pour vérifier, rapidement et en urgence, les antécédents d’un inconnu

Ce travail est sous licence (Creative Commons) Licence Creative Commons Attribution-NonCommercial 4.0 International
Republier gratuitement nos articles, en ligne ou en version imprimée, sous une licence Creative Commons.
Republier cet article
Ce travail est sous licence (Creative Commons) Licence Creative Commons Attribution-NonCommercial 4.0 International
Lire la suite
Actualités et analyses Data journalisme
« La recherche de preuves » : Ce qui a attiré les femmes datajournalistes de premier plan vers ce domaine
À l’occasion de la Journée internationale du droit des femmes, GIJN a interrogé des femmes datajournalistes d’Argentine, du Kenya, de Suède et de Turquie pour savoir pourquoi elles ont choisi cette voie et quels sont les défis qui restent à relever.
Actualités et analyses Climat Data journalisme
10 erreurs courantes dans le data-journalisme
Riches retours d’expériences. GIJN a demandé à des data-journalistes à travers le monde quelles étaient les lacunes en matière de data-journalisme qu’ils constataient et quels étaient les sujets peu couverts que les salles de presse pouvaient aborder.
Actualités et analyses Méthodologie Outils et conseils pour enquêter Recherche
8 méthodes pour consulter gratuitement les publications scientifiques et universitaires
Dans cet article, vous découvrirez huit méthodes destinées aux journalistes pour consulter gratuitement les publications scientifiques et universitaires.
Actualités et analyses Méthodologie Outils et conseils pour enquêter Recherche Techniques d'enquête
Astuces pour vérifier, rapidement et en urgence, les antécédents d’un inconnu
Les projets d’enquête sont souvent comparés à des marathons. Mais, de temps en temps, les reporters doivent faire un sprint. Retour d’expériences de journalistes d’investigation qui, lors d’une session de la conférence sur le journalisme d’investigation en Amérique du Nord IRE23, ont partagé des conseils sur comment vérifier les antécédents de personnes peu connues, dans un délai très court.