
Зображення: Shutterstock
Покроковий посібник для журналістів з основ роботи в Google Таблицях
Read this article in

Посібник із розслідувань з використанням бібліотек цифрової реклами

Ресурси для пошуку та використання супутникових зображень

Як отримати безкоштовні супутникові знімки: порадник журналіста

Information laundromat: Як працює інструмент для аналізу вмісту та метаданих сайтів
Журналістам-розслідувачам часто доводиться занурюватися у величезні масиви даних, отриманих від джерел як витік інформації або у відповідь на запит про доступ до публічних даних. Вміння користуватися електронними таблицями — важлива навичка, що допомагає знаходити потенційні історії у великих обсягах даних. Також вона дає подвійну перевагу: полегшує очищення та візуалізацію даних і водночас забезпечує зручне для читача подання інформації. Головне — критично осмислити, як використовувати наявні дані для пошуку історій в електронних таблицях.
У цьому посібнику ми будемо посилатися на Google Таблиці, але зверніть увагу, що наведені кроки й формули також можна застосувати в Microsoft Excel. Там є незначні відмінності, наприклад, у розташуванні кнопок у меню або у тому, як вони виглядають. Для спрощення ми не будемо вказувати щоразу на ці відмінності.
Для початку відкрийте Google Диск і створіть нову електронну таблицю за допомогою Google Sheets. Для цього натисніть кнопку «+Створити» у верхньому лівому кутку Диска, а потім виберіть Google Таблиці:
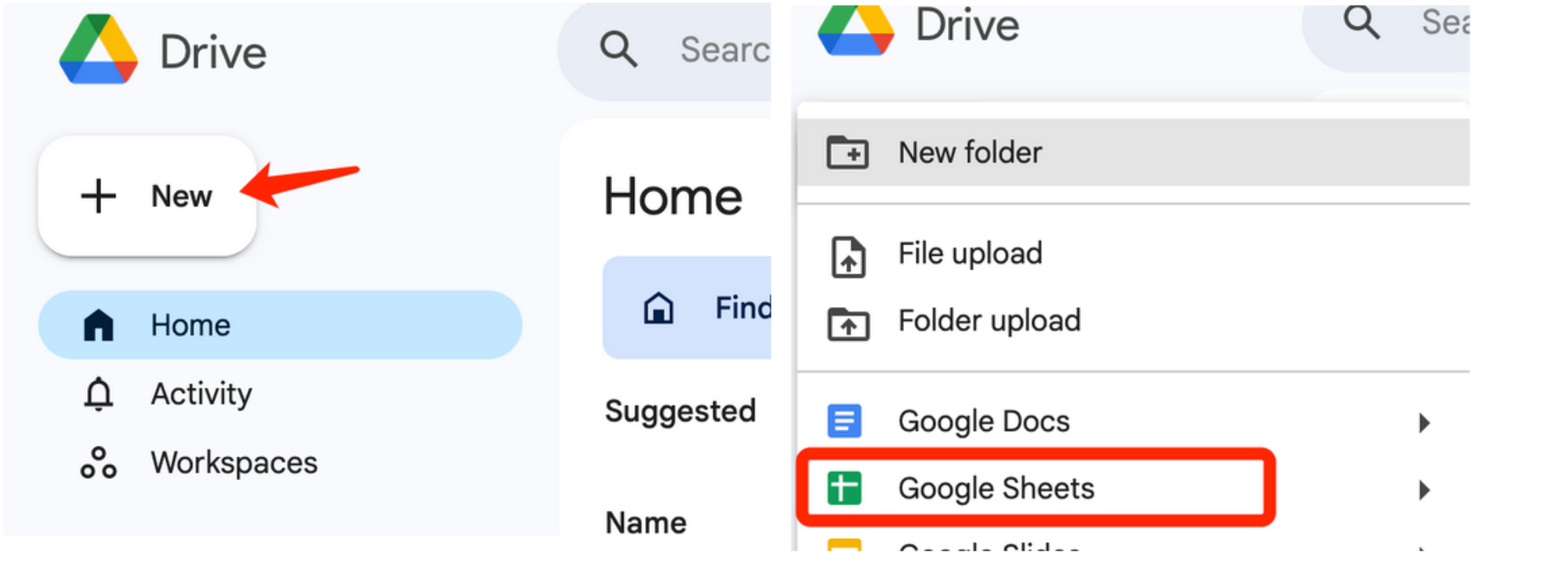
Коли документ відкриється, ви побачите порожню електронну таблицю, що складається з рядків і стовпчиків. Тут будуть «жити» ваші дані.
Оце рядок.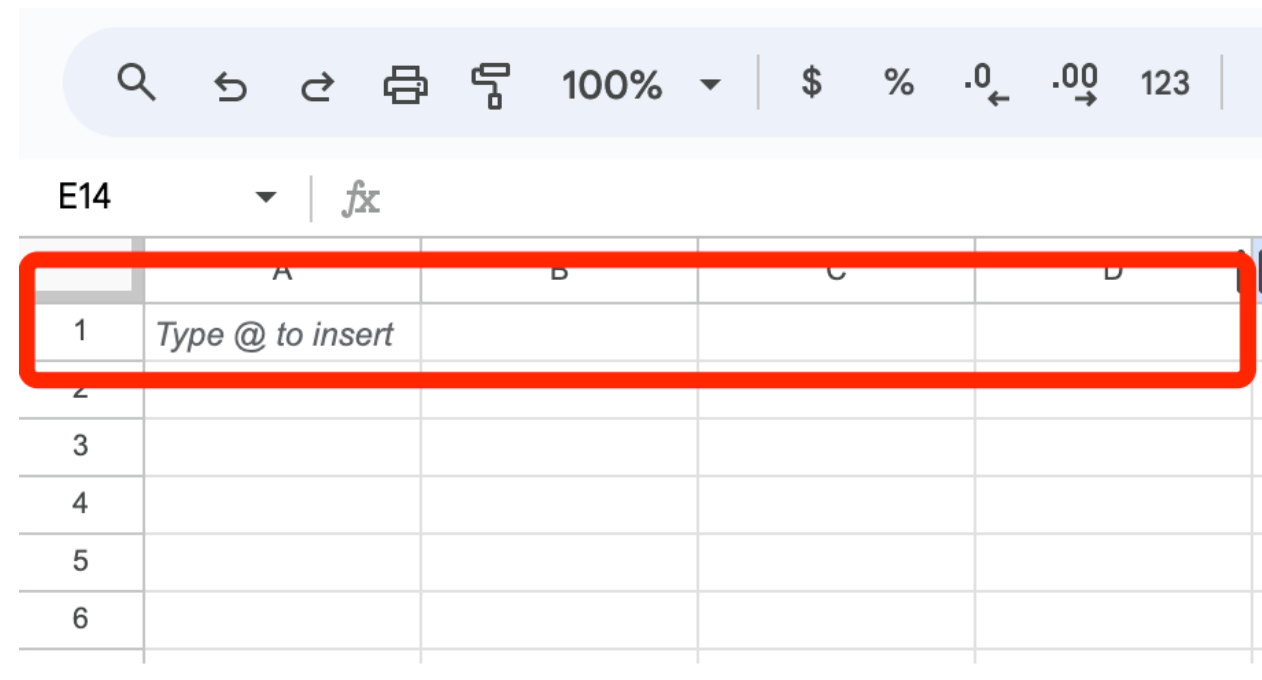
А ось стовпчик.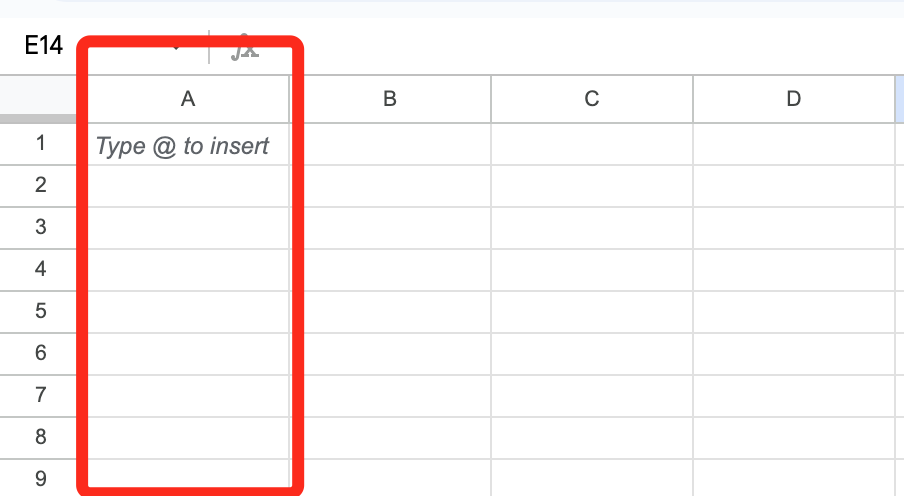
Коли ви починаєте використовувати порожню електронну таблицю, рекомендуємо у верхньому рядку завжди писати заголовки. Це назви ваших категорій даних, наприклад, ІМ’Я. Незабаром ви побачите приклад.
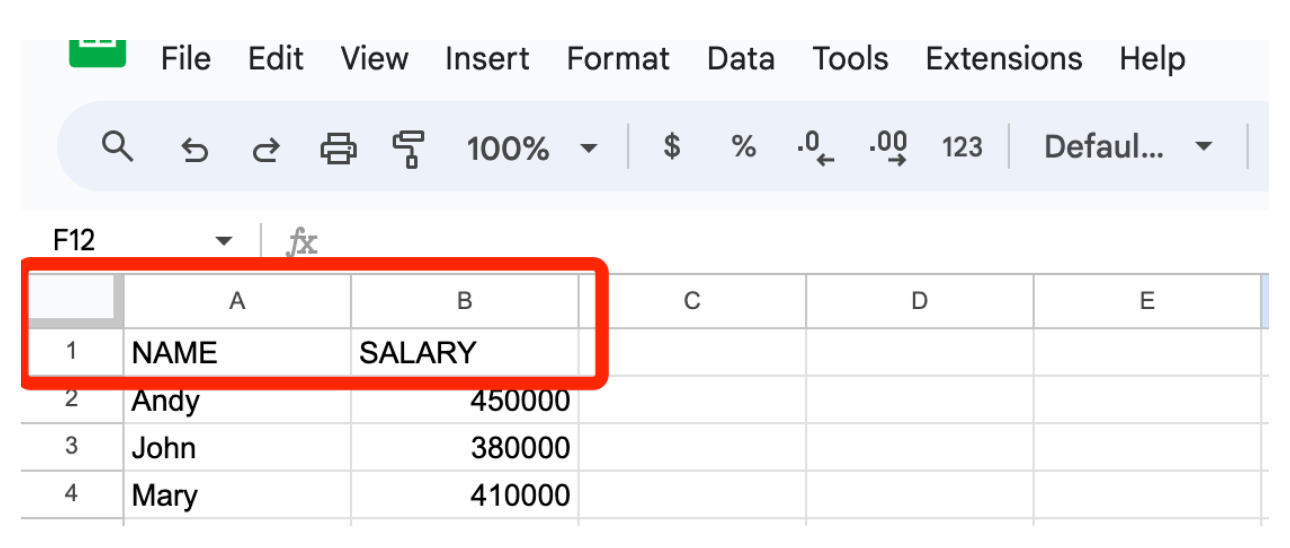
Наразі введіть наступні дані у спадаючі поля в колонці A:
ІМ’Я
Andy
John
Mary
Sally
Mark
У стовпчику B введіть зарплати в низхідному порядку, як показано нижче:
ЗАРПЛАТА
450000
380000
410000
290000
950000
Вводячи числа, не використовуйте розділових знаків — це допоможе уникнути проблем із форматуванням.
Завжди створюйте заголовки стовпців для позначення даних — так їх легше організовувати та сортувати. Далі ми покажемо, як сортувати й фільтрувати за допомогою заголовків.
Використання базових формул
Кожна формула починається зі знаку «=». Будьте уважні, коли вводите формулу, оскільки Google намагатиметься автоматично підставити те, що, на його думку, ви хочете написати, і може припуститися помилки. Завжди перевіряйте свої формули.
Щоб побачити загальну суму виплачених зарплат, ми підсумуємо річні зарплати зі стовпчика B для всіх працівників у стовпчику A. На рисунку нижче вони виділені в полях від B2 до B6. У формулі це подано як «=SUM(B2:B6)», таким чином Google бачить початкову й кінцеву клітинку набору даних.
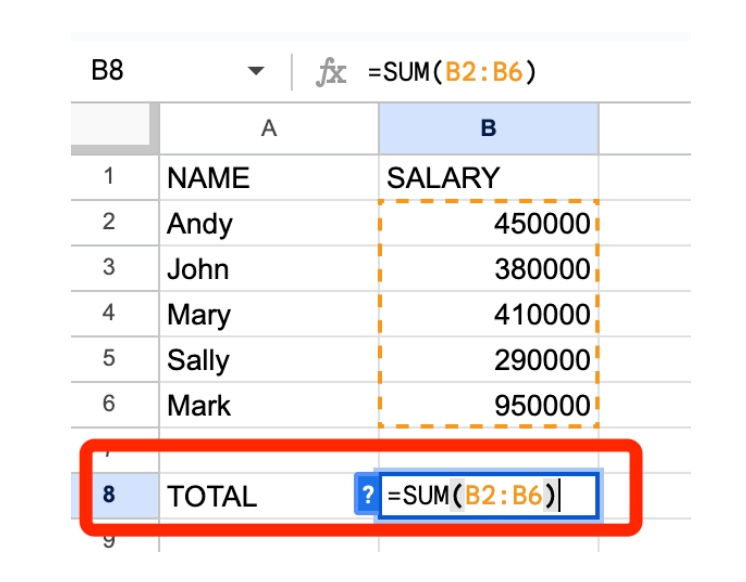
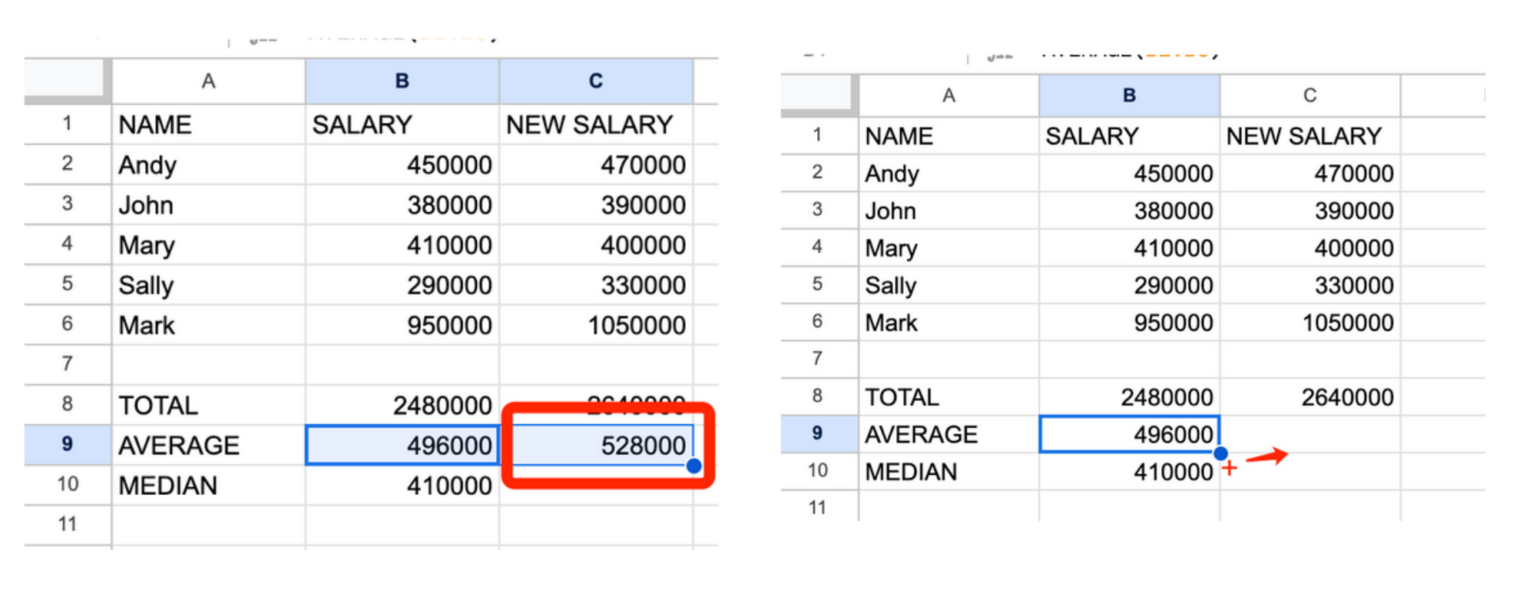
Ми також можемо розрахувати середню заробітну плату працівників, використовуючи формулу «=AVERAGE(B2:B6)», як показано нижче.
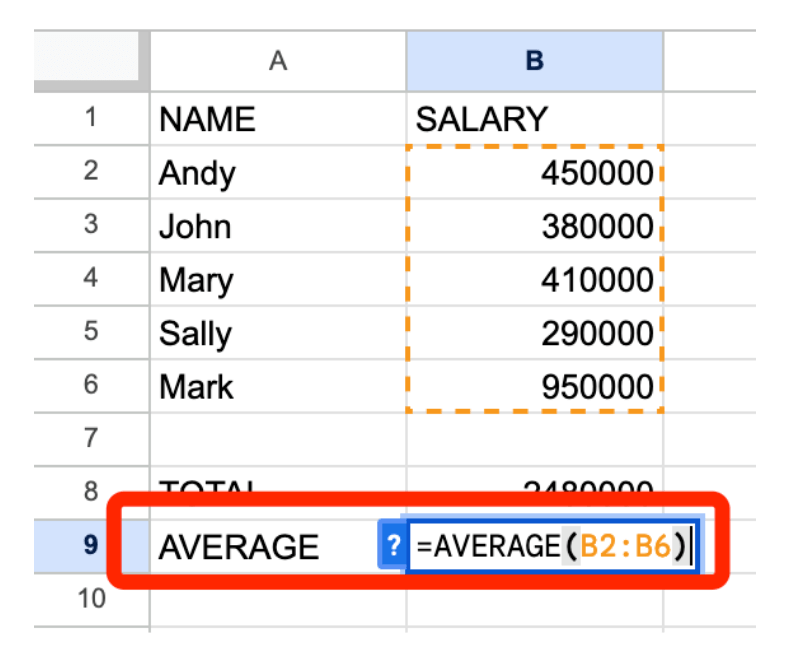
У нашому випадку середня зарплата складає 496000. Але стережіться аномальних значень! Зверніть увагу, що Марк у клітинці A6 є аномальним значенням — його зарплата значно перевищує зарплати інших — і через це середня зарплата всіх працівників зміщена в більшу сторону. (Зауважте, що всі інші працівники заробляють менше середнього значення 496000).
Журналісти часто використовують середні показники у своїх матеріалах, але такий розрахунок може значно викривляти дані, оскільки середнє арифметичне обчислюється шляхом простого підсумовування всіх чисел і ділення на їхню кількість.
Щоб точніше показати справжню статистичну картину, часто краще натомість обчислити медіану, яка передбачає розрахунок значення, що буде рівно посередині ряду всіх перерахованих чисел.
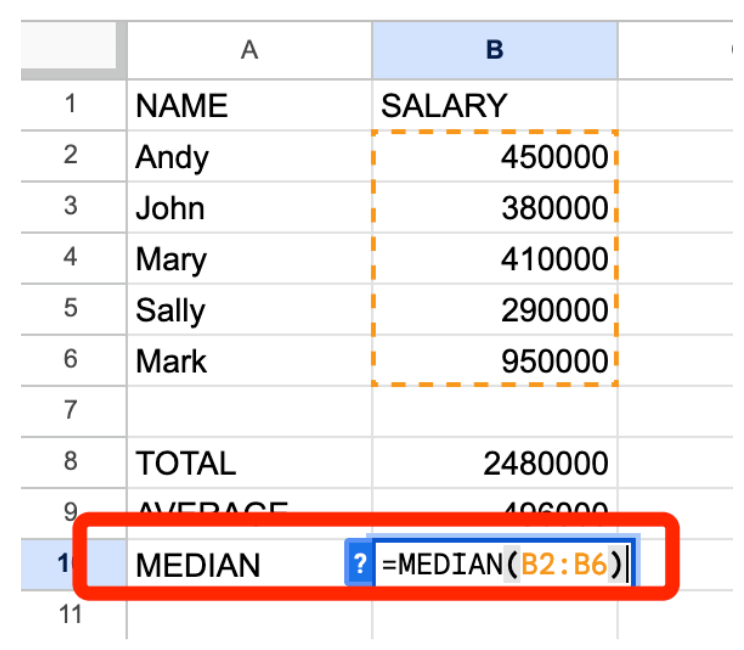
У цьому випадку медіана становить 410000, що набагато реалістичніше відображає типовий рівень заробітної плати працівників цієї компанії. (Зауважте, що двоє працівників отримують більше, ніж медіана, двоє — менше, а один — рівно стільки ж). Тож розпізнавання аномальних значень і розуміння їхнього впливу вкрай важливе для точності журналістської роботи.
Тепер ми створюємо новий стовпчик С з новими зарплатами й хочемо побачити нову загальну суму. Замість того, щоб писати формулу знову, ми можемо просто клацнути на B8 і побачити формулу, яка заповнює цю клітинку.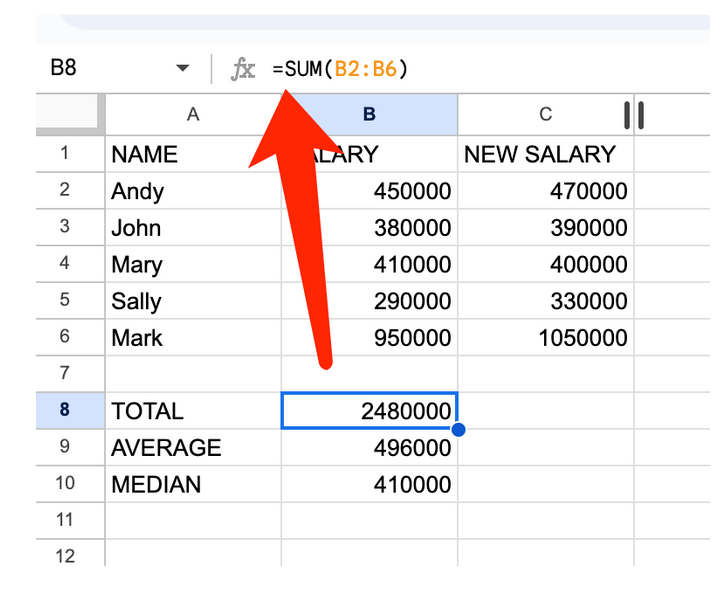
Ми можемо скопіювати клітинку B8 і вставити її в клітинку C8, щоб розрахувати нову загальну суму зарплат, а Google Таблиці автоматично скоригують формулу, щоб використовувати поля даних з нашого нового стовпчика C.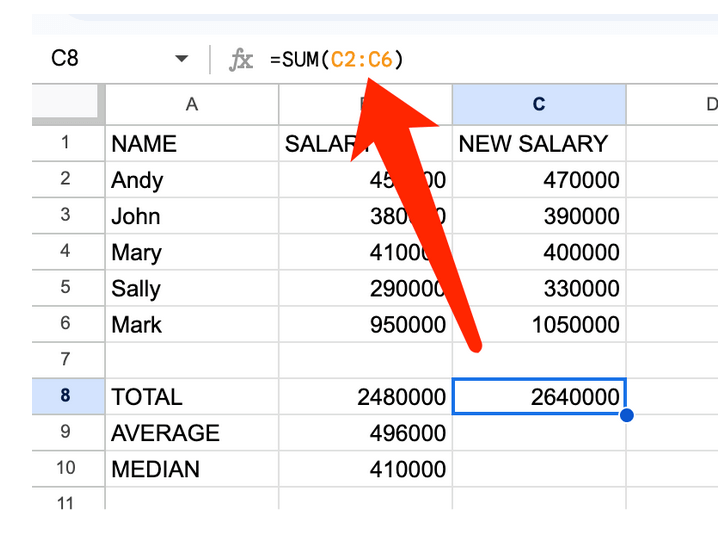
Проте будьте обережні. Якщо ви допустили помилку в першій формулі, копіювання її в інші клітинки повторить ту саму помилку. Завжди перевіряйте свої формули, щоб бути впевненими в правильності інформації — так само, як ви перевіряєте будь-яку інформацію, надану вам джерелом під час інтерв’ю.
Швидший спосіб копіювання формул — клацнути клітинку з формулою, навести курсор на правий нижній кут, де ви побачите синю крапку, і з’явиться знак «+». Натисніть його і перетягніть курсор праворуч, щоб скопіювати формулу.
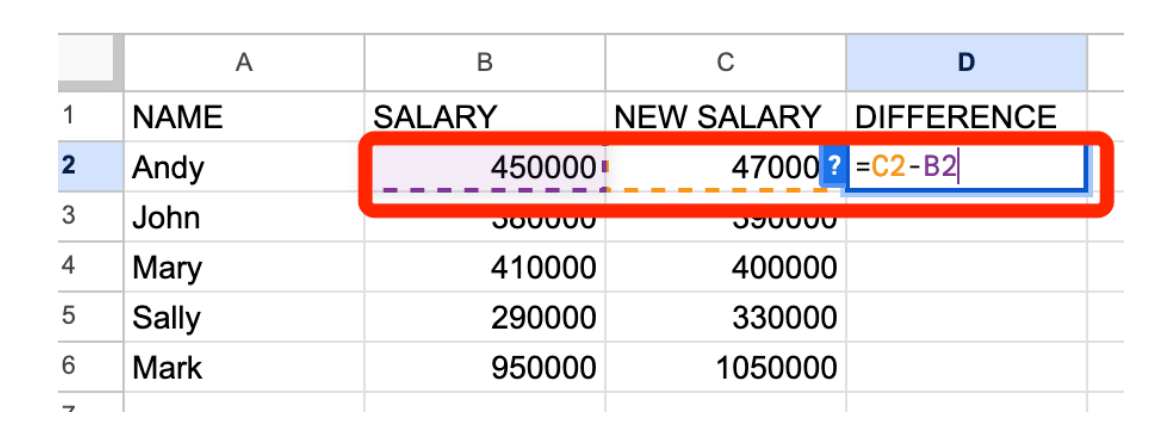
Якщо ми тепер створимо новий стовпчик із заголовком РІЗНИЦЯ в колонці D, то зможемо швидко підрахувати, наскільки змінилися зарплати, віднявши стару зарплату від нової.
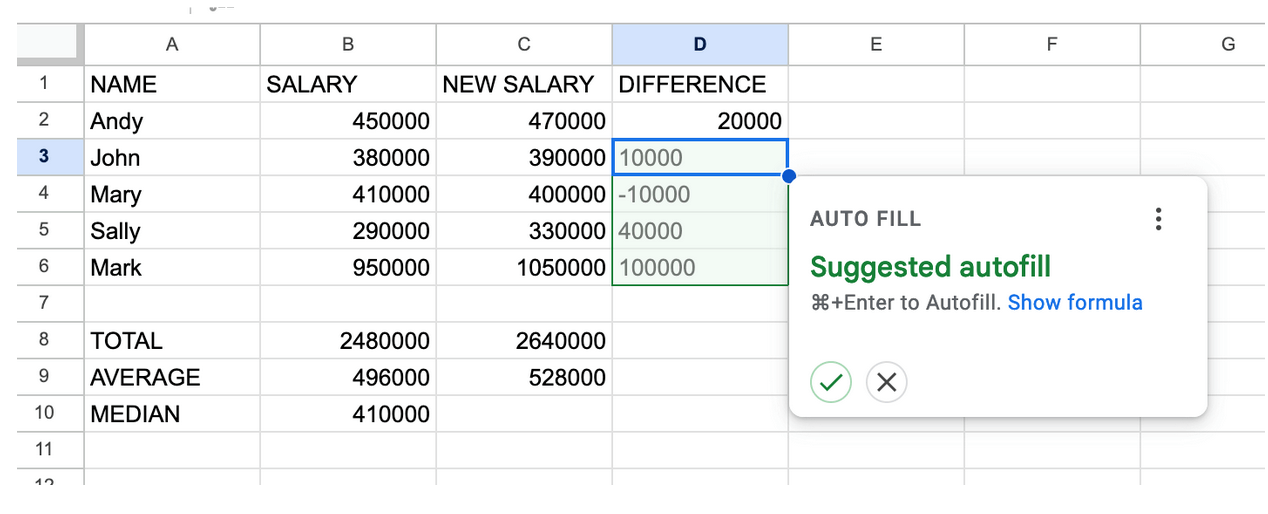
Після введення в один ряд, Google Таблиці запропонують виконати такий самий розрахунок для інших рядків, тож можна натиснути прапорець, щоб прийняти пропозицію, або знову перемістити курсор у правий нижній кут D2 і перетягнути його вниз через інші рядки до D6. Крім того, можна двічі клацнути синю крапку в правому нижньому куті D2, і вона автоматично заповнить формулу для всіх рядків під нею.
Щоб порахувати різниці зарплат у відсотках між двома зарплатами, потрібно взяти нову зарплату і відняти від неї стару, а потім розділити результат на стару зарплату = (Нове – Старе) / Старе.
Запишемо формулу так, як це робиться в математиці, використовуючи круглі дужки (), щоб вказати Google Таблицям, яка операція відбувається першою, у нашому випадку C2 – B2.

Але такі значення відсотків різниці складнувато використовувати в журналістських роботах.
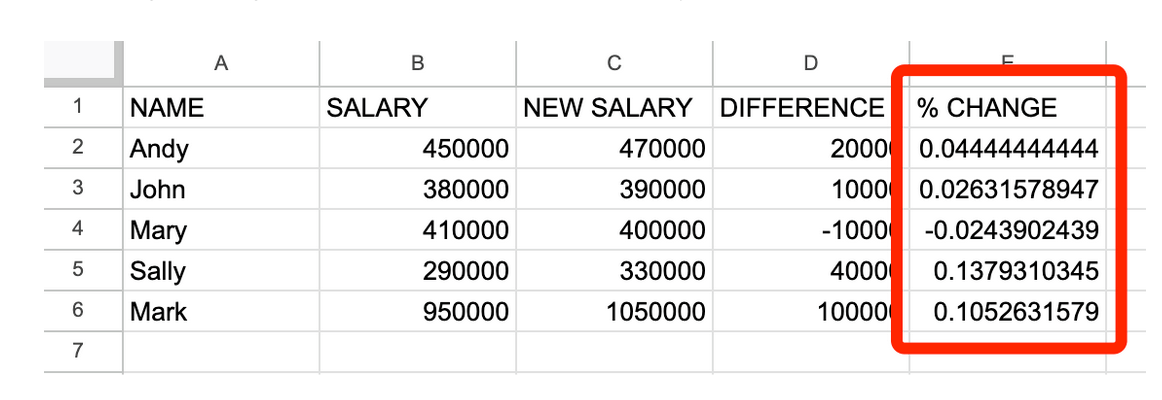
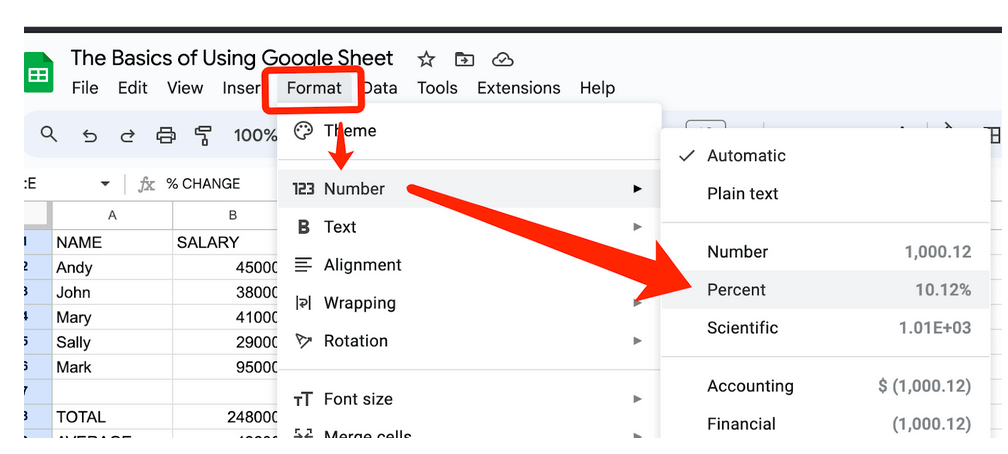
Щоб це покращити, можна натиснути на верхню частину стовпчика E, щоб виділити всі клітинки в стовпчику, потім виберіть поле «Формат» у верхньому меню сторінки, перейдіть до пункту «Число > Відсоткове значення» і натисніть на нього, щоб відформатувати весь стовпчик.
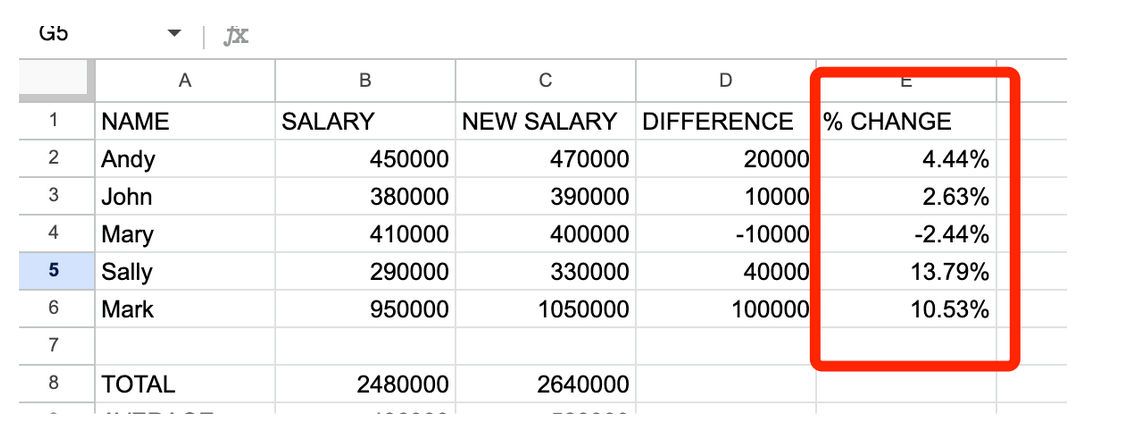
Тепер ми створимо новий стовпчик F, щоб обчислити відсоток від загальної суми. Для цього нам потрібно розділити частину на ціле, тобто C2 (нову зарплату Енді) на C8 (загальну суму нових зарплат).
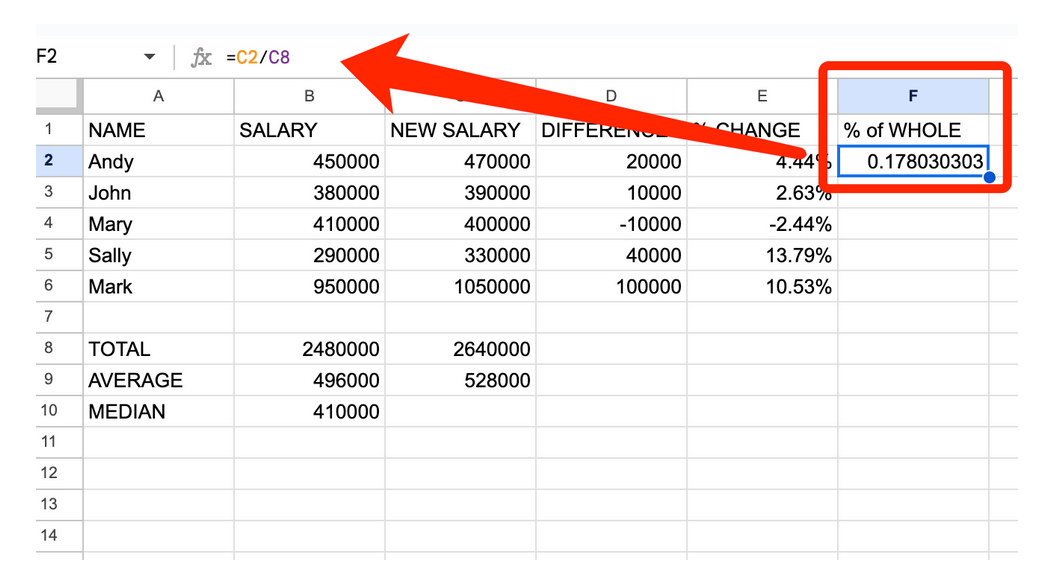
Як згадувалося раніше, якщо ми хочемо виконати ті самі обчислення для решти рядків з 3 по 6, ми перетягуємо клітинку F2, щоб застосувати формулу до решти стовпчика F. Однак, коли ми це робимо, то отримуємо неправильні або дивні результати.
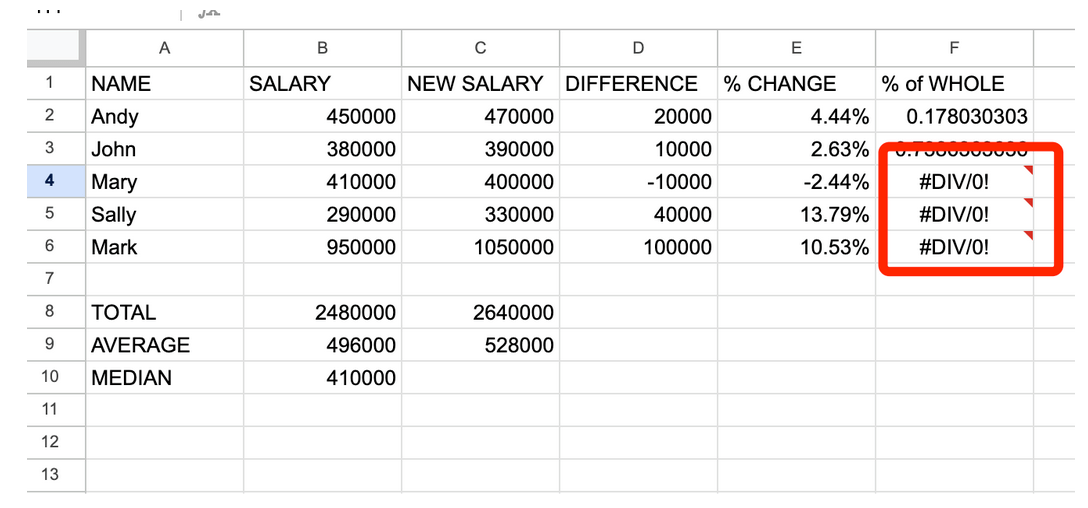
Це відбувається тому, що коли ви копіюєте формулу і застосовуєте її до інших рядків, Google Таблиці завжди будуть надалі підставляти формулу нижче, використовуючи відповідні поля для виконання нових обчислень. Це означає, що в клітинці F2 формула має вигляд C2 / C8, у клітинці F3 – C3/C9, F4 – C4 / C10, F5 – C5 / C11 і F6 – C6 / C12.
Можна уникнути цієї проблеми, використовуючи інструмент прив’язки «$». Прив’язка — це команда, яка вказує Google Таблиці не переміщувати формулу з певної клітинки, оскільки нам потрібно завжди використовувати тільки певну клітинку для нашої формули.
У цьому випадку клітинка C8 (TOTAL NEW SALARY — НОВА З/П, УСЬОГО:) — це клітинка, на яку ми завжди будемо ділити нові зарплати. Щоб прив’язати C8 до нашої формули, ми запишемо її як «C2/$C$8». У цій формулі ви бачите два символи прив’язки, тому що ми кажемо Google Таблиці «не виходити зі стовпчика C і не виходити з рядку 8». Завжди ставте символ прив’язки перед відповідним рядком і стовпчиком, а не після.
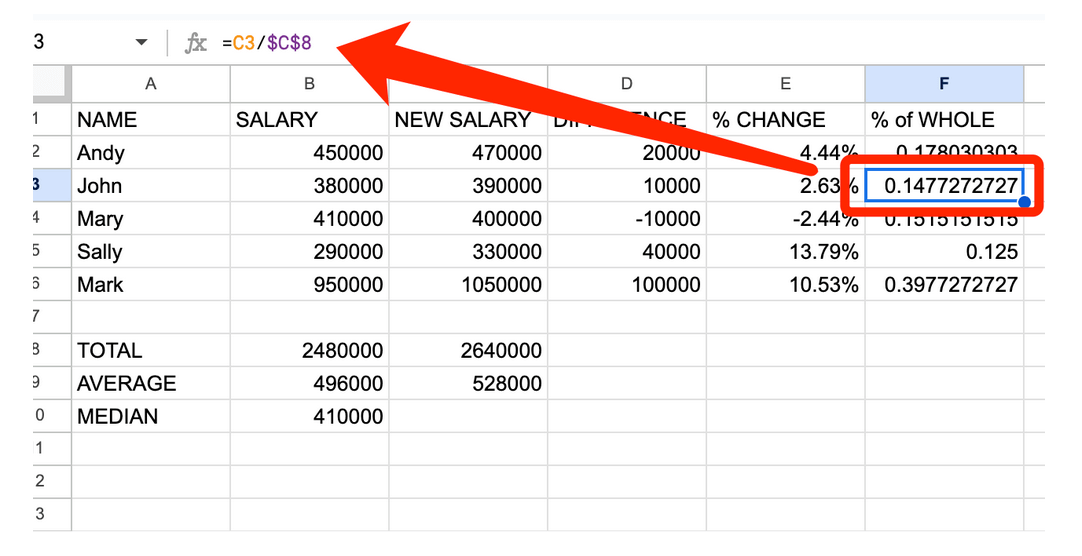
Після цього можна знову вибрати стовпчик F, перейти до верхнього меню і натиснути «Число» > «Відсоткове значення», щоб побачити правильні відсотки замість повідомлення про помилку «#DIV/0!».
Створення діаграм
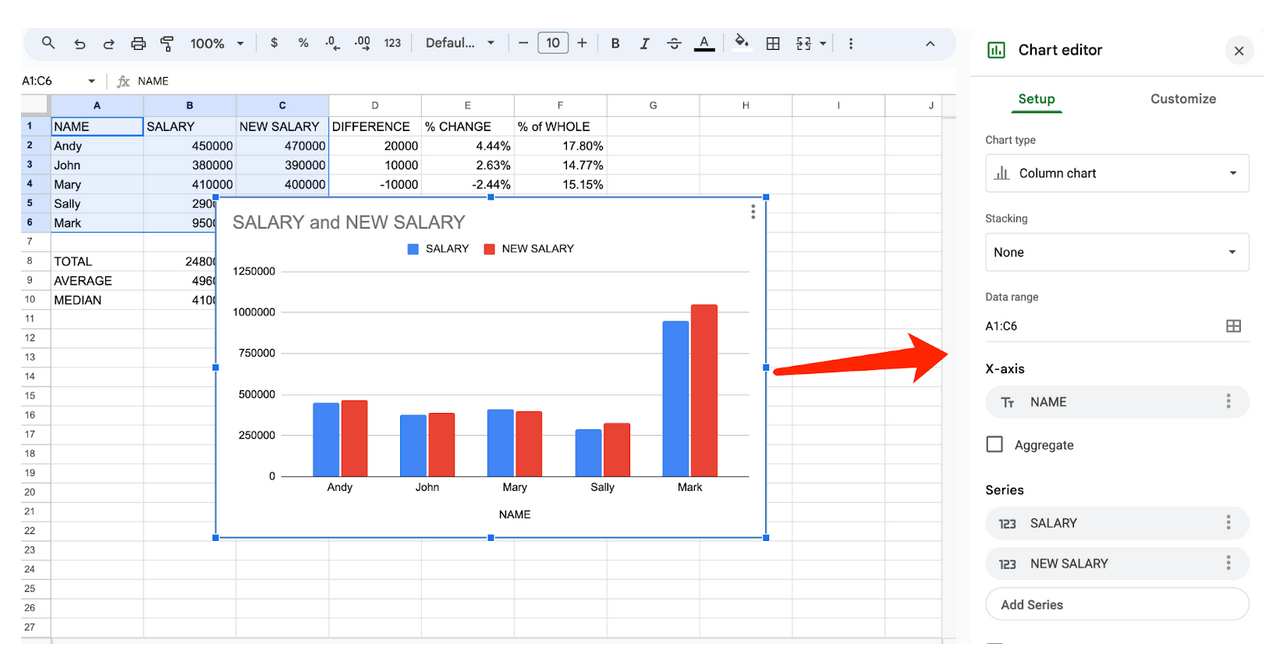
Ми журналісти, тому нам хочеться допомогти людям зрозуміти дані візуальними засобами. У нашому випадку ми хочемо показати стару і нову зарплату, тому нам потрібно вибрати від A1 до C6.
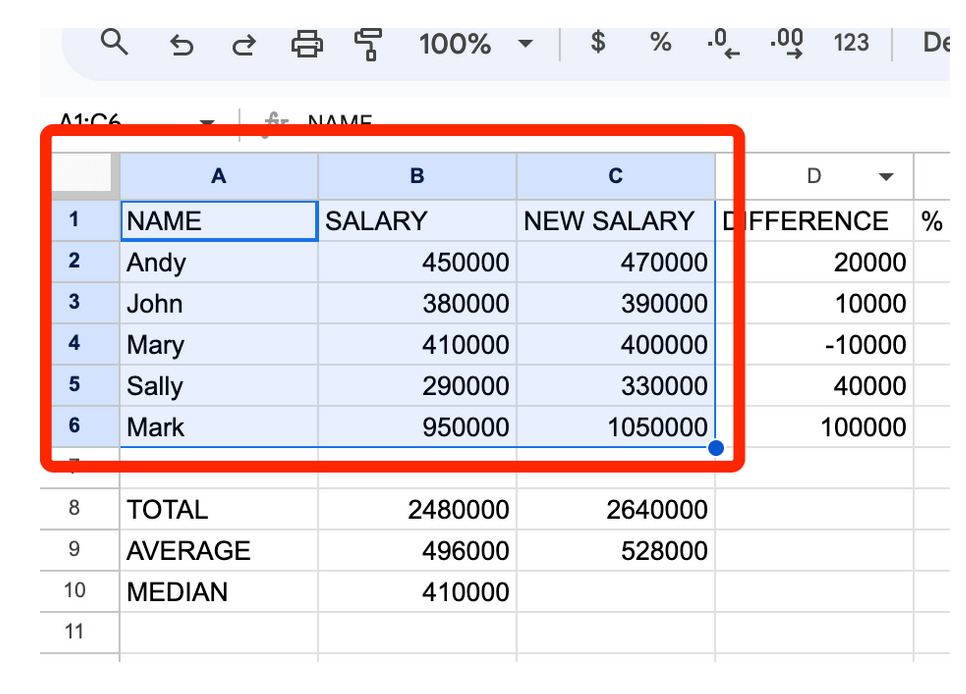
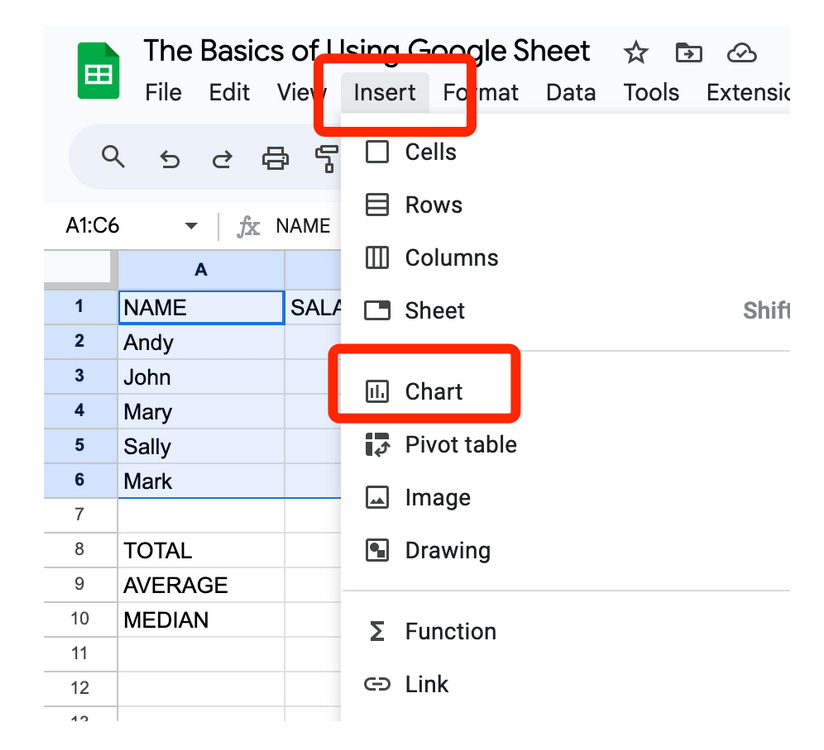
Вибравши дані, натисніть «Вставити» у верхньому меню, а потім виберіть пункт «Діаграма».
Google Таблиці створять діаграму для вас, а якщо відвести курсор миші в правий бік екрану, то можна змінити її й налаштування за допомогою інструменту «Редактор діаграм».
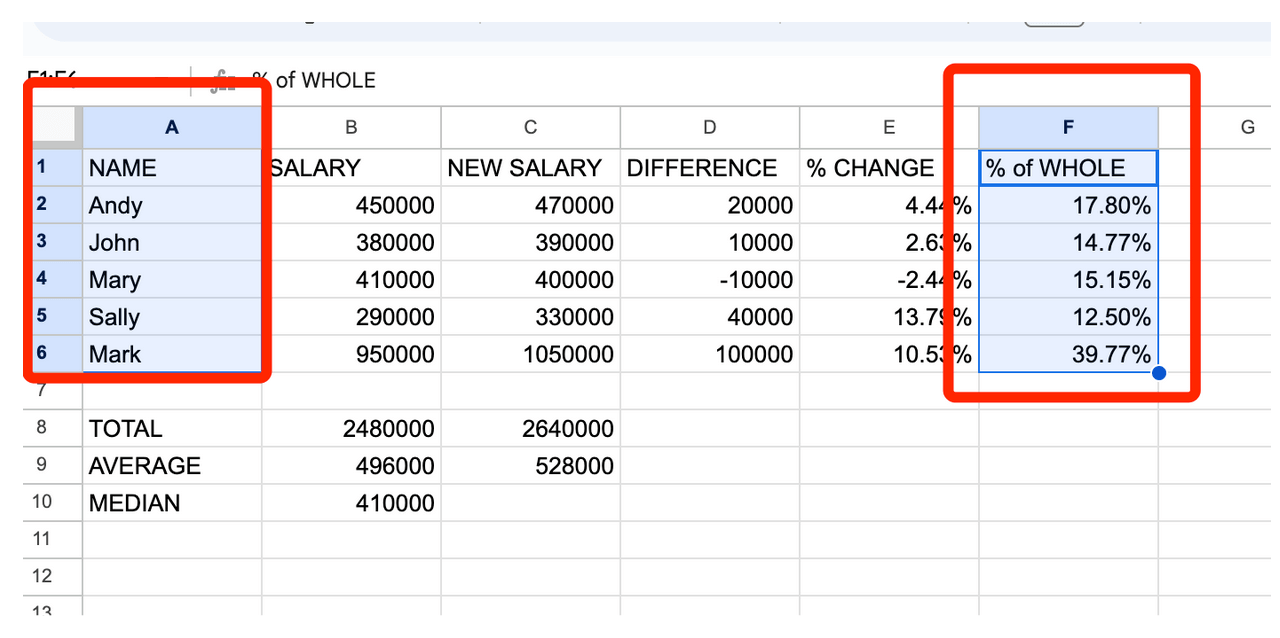
Також можна створити кругову діаграму з відсотками від усієї суми, які ми розрахували раніше в колонці F. Для цього нам знадобиться колонка A з іменами і колонка F із відсотками. Оскільки ці два стовпчики не знаходяться поруч, ми не можемо просто натиснути на A1 і перетягнути курсор. У цьому випадку ми натискаємо на A1, утримуємо кнопку миші натиснутою, перетягуємо вниз до A6, а потім відпускаємо, щоб завершити виділення.
Потім переміщуємо курсор на F1, натискаємо й утримуємо клавішу Command для Mac або Control для Windows, а потім перетягуємо курсор вниз до F6. Це дозволить вибрати саме ті дані, які нам потрібні для нашої кругової діаграми.
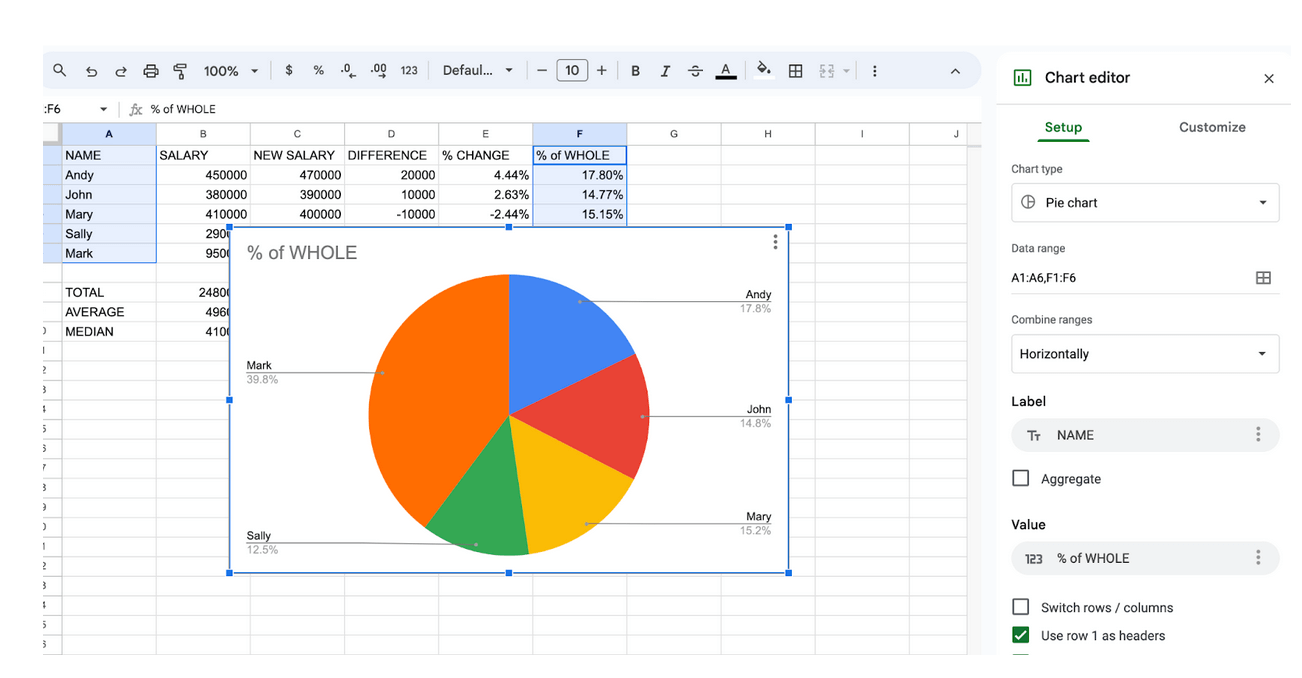
Знову вибираємо верхнє меню «Вставити» > «Діаграма», і Google Таблиці створять кругову діаграму.
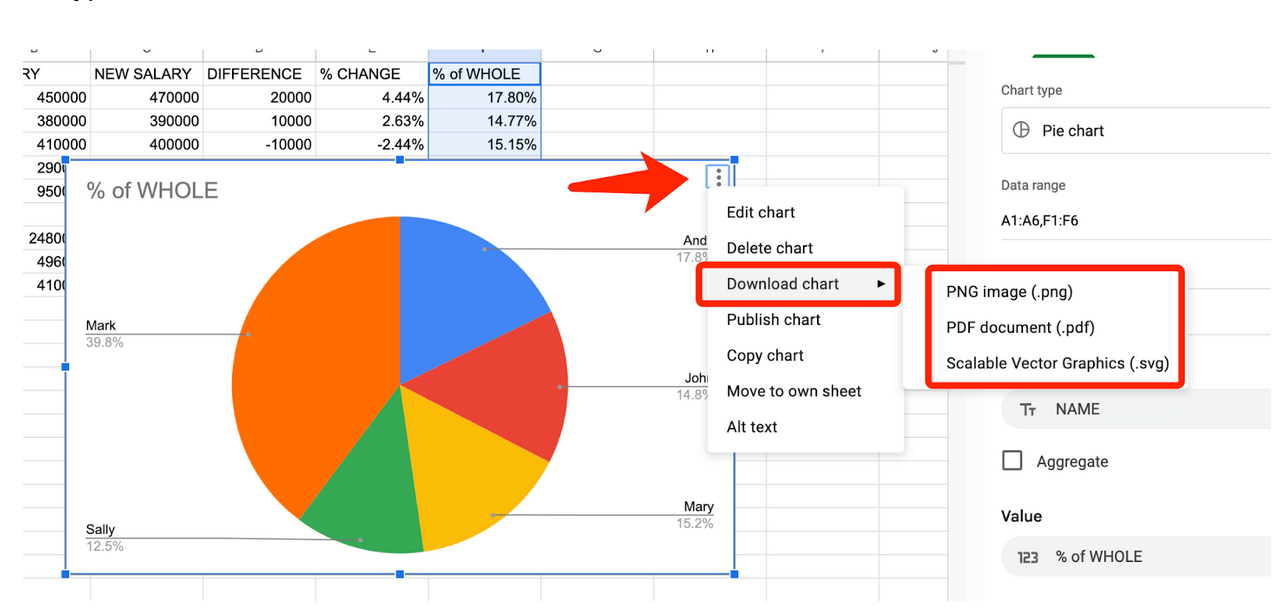
Після того, як ви налаштували графіку, її можна зберегти окремо для своїх публікацій. Натисніть на три вертикальні крапки у верхньому правому куті діаграми, виберіть пункт «Завантажити діаграму» і потрібний тип файлу.
Сортування довгих списків даних
Що робити, якщо нам надали довгий список даних, і потрібно з них зробити якусь історію? Сортування — це один із найкращих способів представити дані по-різному і зрозуміти, чи є щось цікаве в цих цифрах.
Наприклад, у цій таблиці ми подивимось на очікувану тривалість життя в різних країнах. Зробіть копію документа, щоб поекспериментувати самостійно.
Відкривши електронну таблицю, клацніть на стовпчик A і утримуйте кнопку миші натиснутою, а далі перетягніть курсор праворуч на стовпчик C, щоб виділити три стовпчики і всі рядки даних нижче. Потім у верхньому меню виберіть «Дані» > «Відсортувати діапазон» > «Додаткові параметри сортування діапазону».
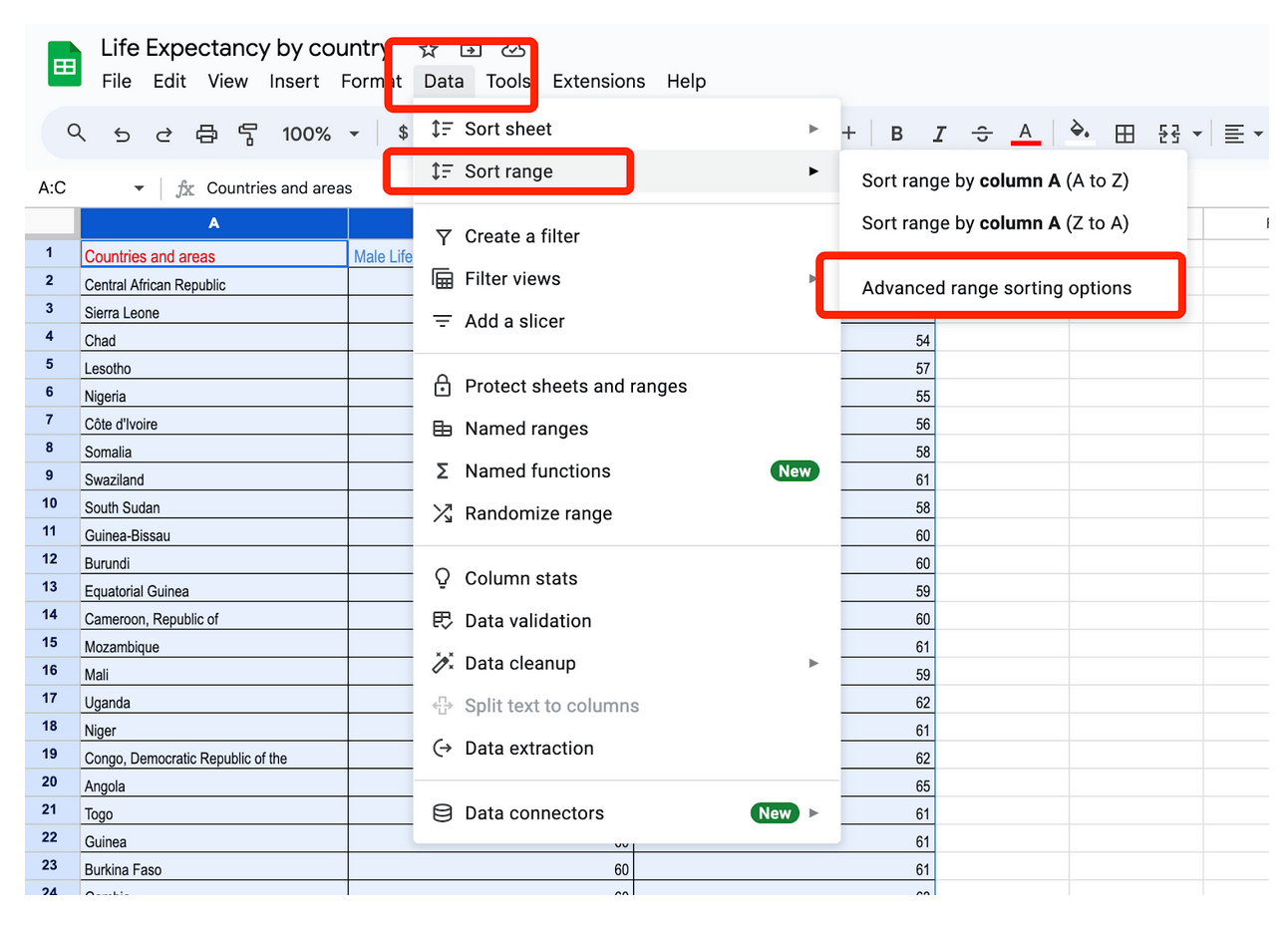
Спершу обов’язково поставте галочку «Дані мають рядок для заголовка», щоб Google Таблиці знали, що перший рядок — це не сам рядок даних, а заголовки / назви ваших стовпців.

Якщо ви виберете «Сортувати за: Male Life expectancy… (Очікувана тривалість життя чоловіків)» від А до Я, то побачите країни з очікуваною тривалістю життя чоловіків від найнижчого значення (А) до найвищого (Я).
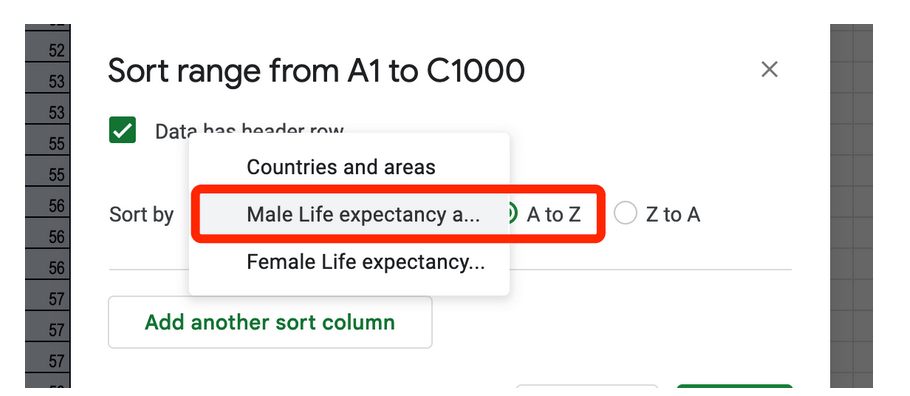
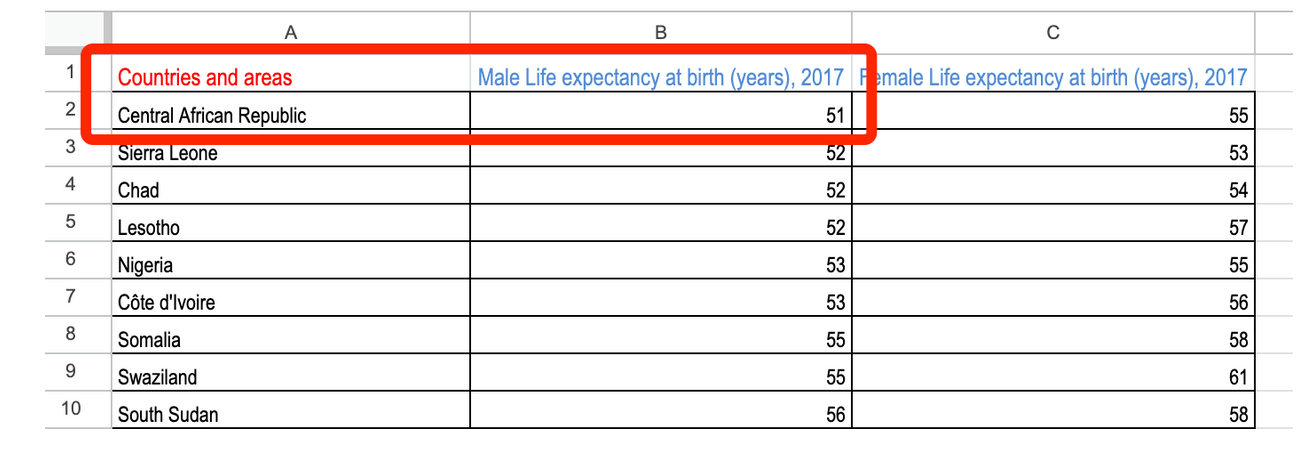
З іншого боку, якщо ви виберете варіант від Я до А, то вам спершу покажуть країни з найвищим значенням, у даному випадку — Швейцарію.
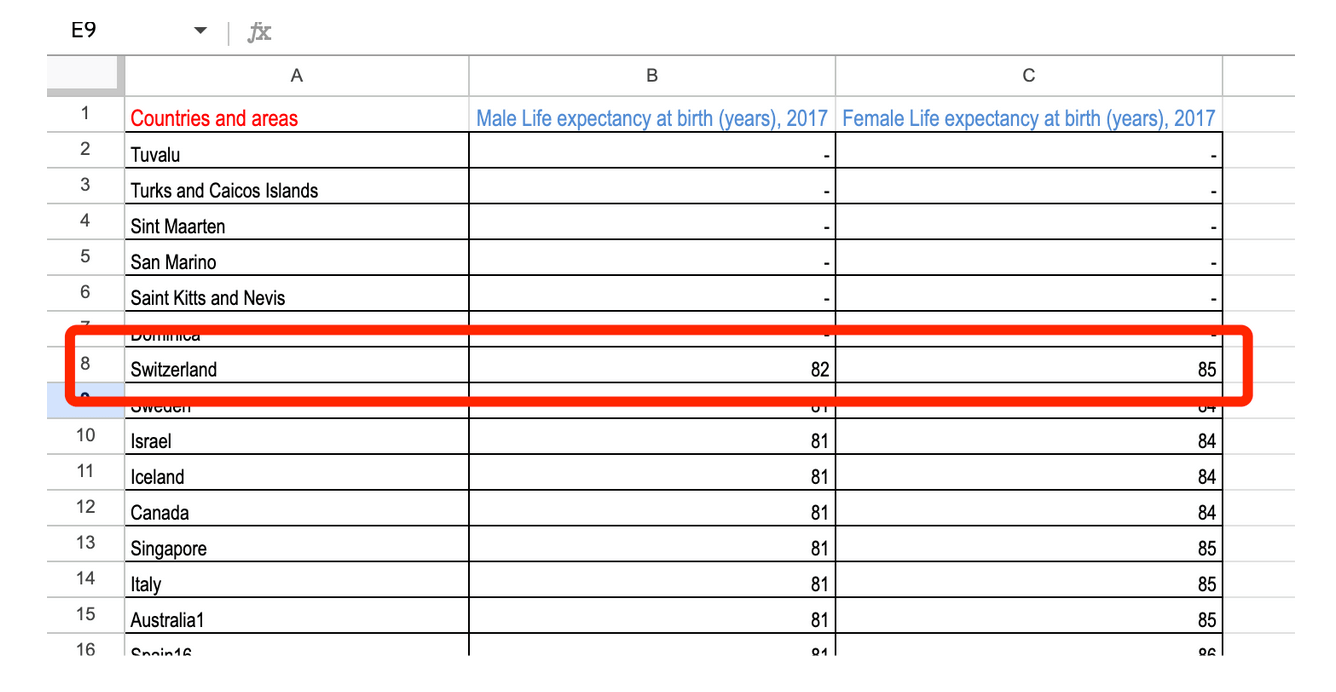
Але ви також можете побачити, що для деяких країн немає даних. Відсортувавши сотні рядків, можна швидко побачити, у яких країнах відсутні дані, і вказати на це у своєму матеріалі, щоб не створити хибне враження, наприклад.
Закріплення рядків і стовпців
А тепер використаємо інший набір даних для наших останніх порад. Зробіть копію цього документа про зарплату європейських футболістів.
Якщо його відкрити і прокрутити, ви побачите, що заголовки верхніх рядків зникають, коли ви прокручуєте вниз — а це заважає, якщо потрібно завжди бачити цю інформацію. Щоб це виправити, клацніть правою кнопкою миші на рядку 1 і внизу виберіть «Переглянути інші дії з рядками» > «Закріпити до рядка 1».
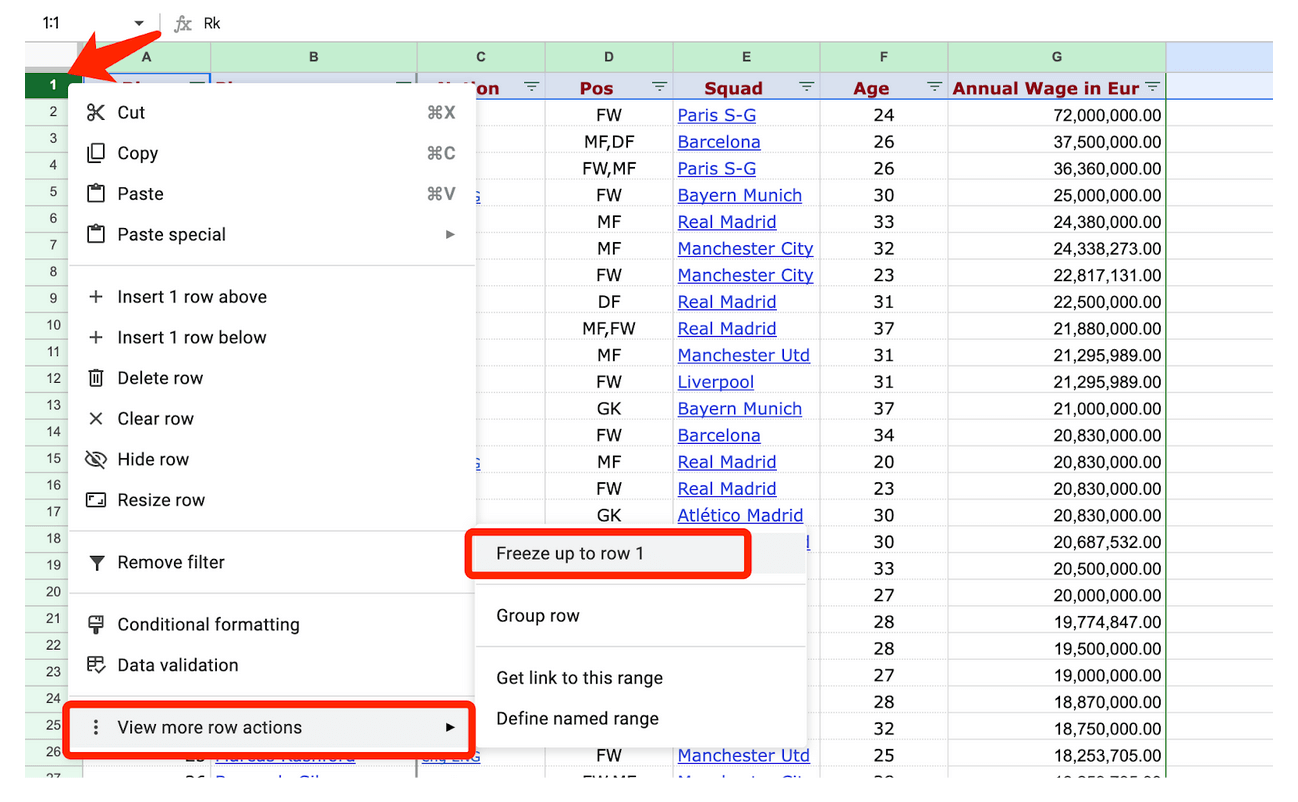
Якщо ви тепер прокрутите вниз, то верхній рядок буде видно постійно. Так само можна зробити й зі стовпчиками, спробуйте клацнути правою кнопкою миші на стовпчику A й закріпити його.
Якщо ж передумаєте, виконайте ті самі кроки, і ви зможете натиснути «Відкріпити», щоб зняти блокування.
Використання фільтрів
Якщо нам потрібно побачити тільки певний набір даних, використаймо опцію фільтру.
Щоб активувати фільтри для ваших даних, просто клацніть будь-де на даних, а потім у верхньому меню виберіть «Дані» > «Створити фільтр».
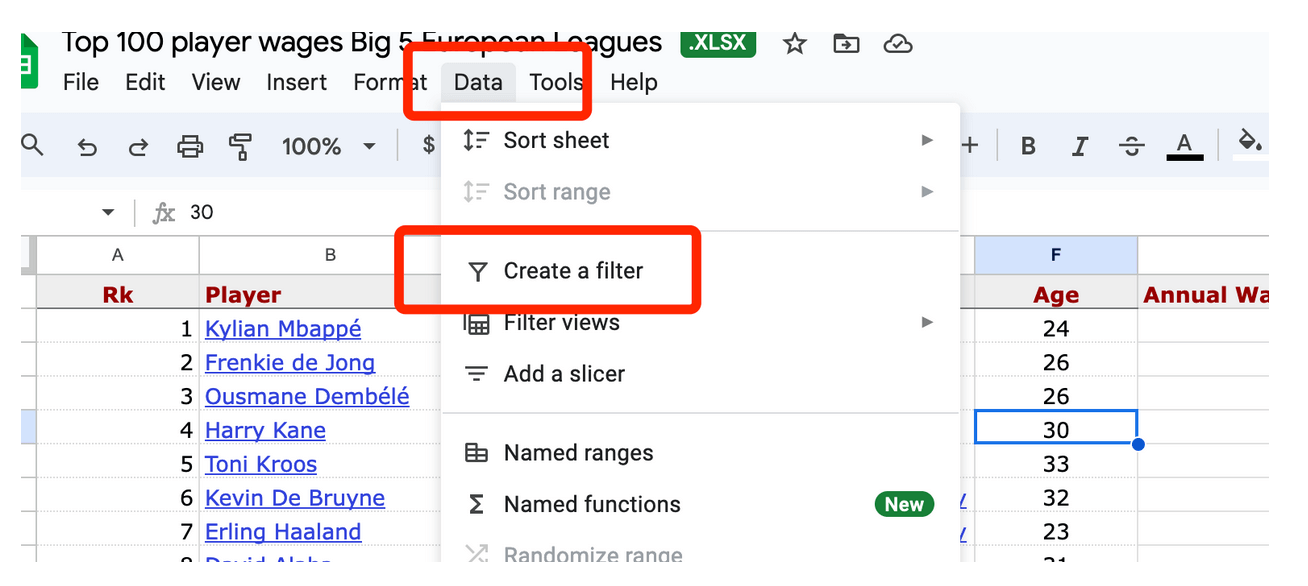
Тепер ви побачите, що у верхніх полях заголовків рядків поруч із назвами стовпців з’явилися кнопки у вигляді перевернутих трикутників.
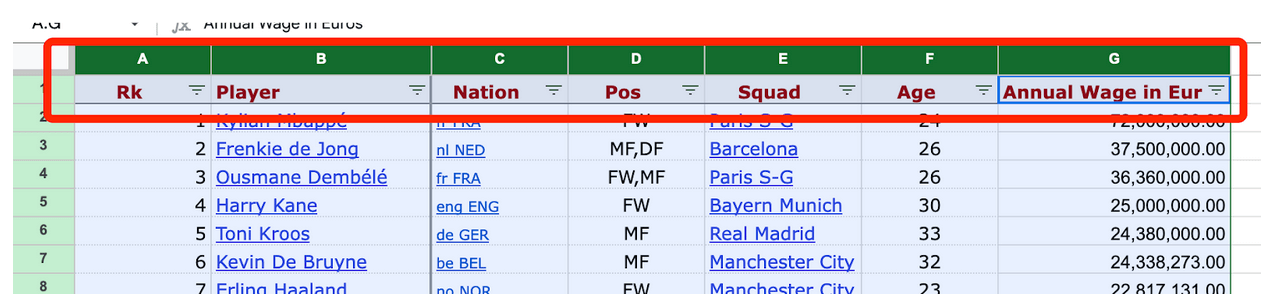
Натисніть на перевернутий трикутник поруч з пунктом «Nation» в полі C1 і виберіть «Очистити», щоб видалити всі вибрані дані, потім виберіть «de GER» і натисніть «ОК».
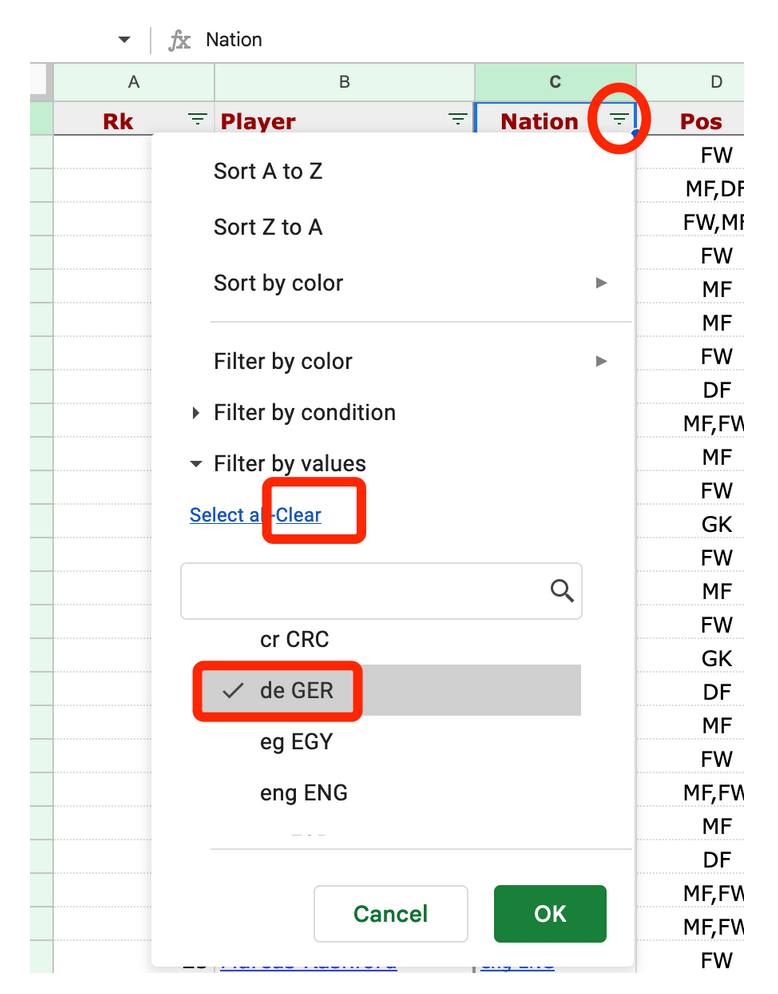
Тепер ви можете побачити всіх найбільш високооплачуваних німецьких футболістів. Можна повторити цей процес для декількох країн.
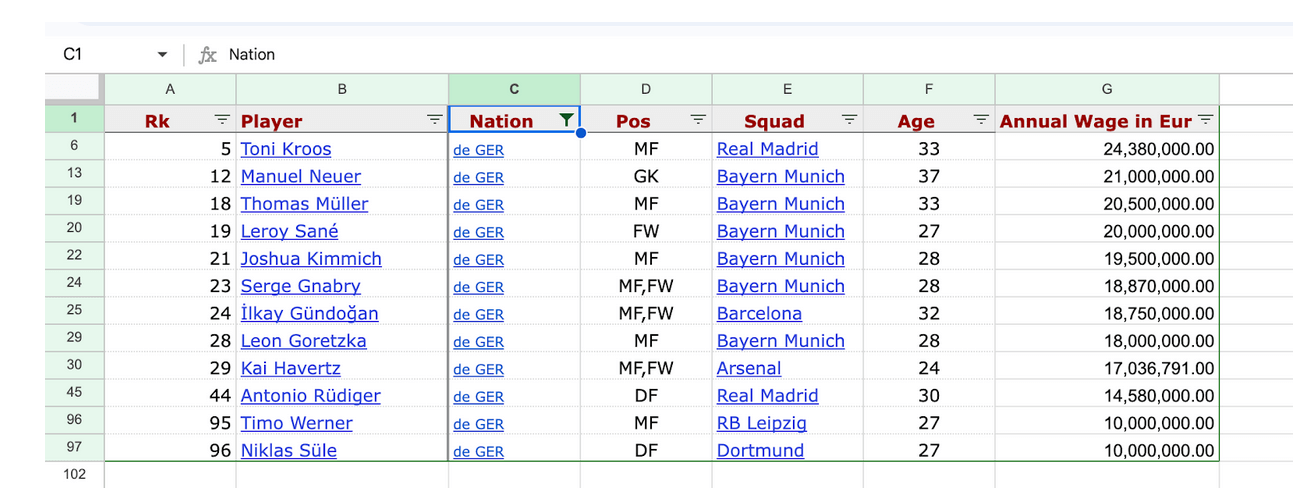
Зверніть увагу, що рядки більше не показані за порядковим номером, тепер вони від 1 до 6, потім 13, 19, і аж до 97. Це тому, що Google Таблиці приховують дані, які ви вирішили не бачити, але не видаляють їх. У цьому випадку не можна використовувати функцію =SUM внизу списку, як ми робили раніше [=SUM(G6:G97)], тому що вона додасть всі дані з рядка 1 до рядка 97, включаючи приховані рядки не-німецьких футболістів.
Якщо все ж потрібно використати для розрахунків саме ці конкретні дані, виберіть їх, скопіюйте, а потім внизу зліва в документі натисніть на знак «плюс», щоб створити новий аркуш.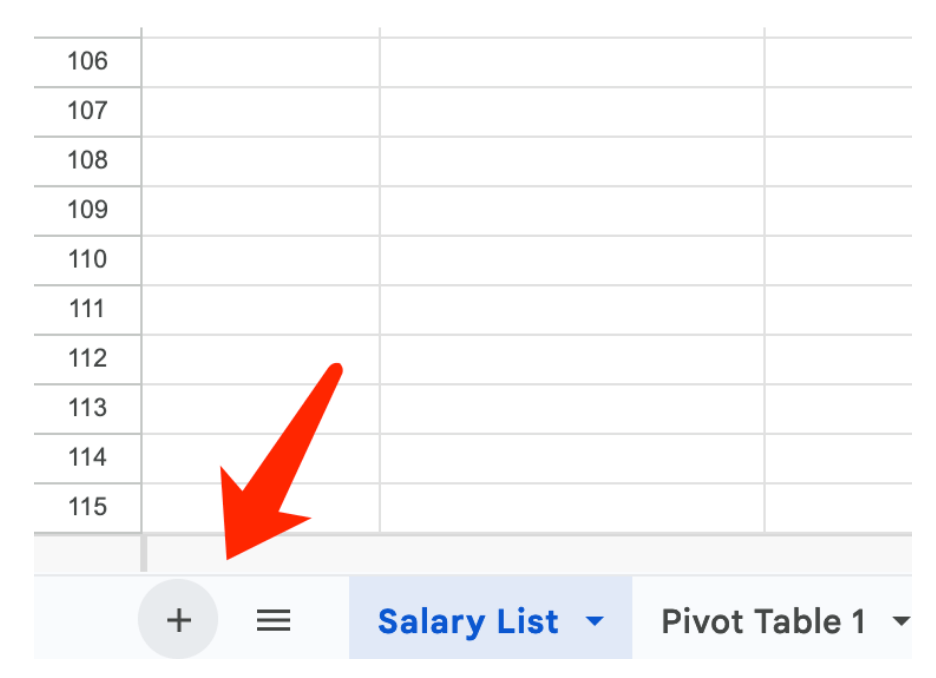
Тепер вставте дані, і ви побачите, що рядки знову пронумеровані правильно. Це тому, що тепер немає більше прихованих даних, і ви можете використовувати функцію =SUM або інші функції обчислення даних для вашого дослідження.
Цей посібник створено на основі порад і методів, викладених на сесії Глобальної конференції журналістів-розслідувачів у Гетеборзі, Швеція, 19-22 вересня 2023 року. На сесії виступили Марк Горвіт, професор Школи журналістики Університету Міссурі; Томмі Каас, співзасновник Kaas & Mulvad; та Ендрю Лерен, старший редактор програми розслідувань NBC News Investigations. Ви можете переглянути повний запис сесії на нашому каналі YouTube (англійською).
Матеріал відредагував і скоротив для більшої наочності онлайн-продюсер GIJN Леонардо Перальта.
 Марк Горвіт — професор Школи журналістики Університету Міссурі, де він викладає журналістські розслідування, а також очолює програму «Висвітлення діяльності органів влади штату» і завідує кафедрою журналістських професій. Раніше Горвіт працював виконавчим директором організації Investigative Reporters and Editors (IRE) та Національного інституту комп’ютерної журналістики (NICAR), де проводив тренінги з журналістських розслідувань та журналістики даних для різних країн. До роботи в IRE Горвіт працював репортером і редактором протягом 20 років.
Марк Горвіт — професор Школи журналістики Університету Міссурі, де він викладає журналістські розслідування, а також очолює програму «Висвітлення діяльності органів влади штату» і завідує кафедрою журналістських професій. Раніше Горвіт працював виконавчим директором організації Investigative Reporters and Editors (IRE) та Національного інституту комп’ютерної журналістики (NICAR), де проводив тренінги з журналістських розслідувань та журналістики даних для різних країн. До роботи в IRE Горвіт працював репортером і редактором протягом 20 років.
 Томмі Каас — редактор видання Kaas & Mulvad (засноване у 2007 році), яке спеціалізується на пошуку цікавинок і закономірностей у складних даних та представленні результатів онлайн. Томмі має багаторічний досвід роботи в низці данських ЗМІ та викладає журналістику даних, в тому числі на факультеті журналістики в Університеті Роскілле. Він також є співзасновником Foreningen for Computerstøttet Journalistik 1997 та DICAR 1999.
Томмі Каас — редактор видання Kaas & Mulvad (засноване у 2007 році), яке спеціалізується на пошуку цікавинок і закономірностей у складних даних та представленні результатів онлайн. Томмі має багаторічний досвід роботи в низці данських ЗМІ та викладає журналістику даних, в тому числі на факультеті журналістики в Університеті Роскілле. Він також є співзасновником Foreningen for Computerstøttet Journalistik 1997 та DICAR 1999.
 Ендрю Лерен — старший редактор команди розслідувань NBC News. Він висвітлював реагування на пандемію та роздачу фінансової допомоги, а також керував роботою над п’ятьма розслідуваннями Міжнародного консорціуму журналістів-розслідувачів, зокрема про імпланти, про Китай та «файли FinCEN». Його матеріал про людей, травмованих відбитими м’ячами, змусив Вищу бейсбольну лігу посилити захист на всіх своїх стадіонах. Раніше він майже 13 років працював репортером у The New York Times, де публікував американські й міжнародні матеріали та журналістські розслідування. Він був одним із провідних репортерів газети, який аналізував зливи WikiLeaks — дипломатичні телеграми, бойові донесення з Афганістану та Іраку, а також досьє в’язнів Гуантанамо. Ці матеріали були опубліковані в книзі-бестселері «Відкриті секрети» (“Open Secrets”). Він брав участь у серії публікацій, відзначених Пулітцерівською премією, яка досліджувала неякісні китайські хімікати, що використовуються в американській фармацевтиці. Він отримав освіту в Університеті Міссурі та Лехайському університеті.
Ендрю Лерен — старший редактор команди розслідувань NBC News. Він висвітлював реагування на пандемію та роздачу фінансової допомоги, а також керував роботою над п’ятьма розслідуваннями Міжнародного консорціуму журналістів-розслідувачів, зокрема про імпланти, про Китай та «файли FinCEN». Його матеріал про людей, травмованих відбитими м’ячами, змусив Вищу бейсбольну лігу посилити захист на всіх своїх стадіонах. Раніше він майже 13 років працював репортером у The New York Times, де публікував американські й міжнародні матеріали та журналістські розслідування. Він був одним із провідних репортерів газети, який аналізував зливи WikiLeaks — дипломатичні телеграми, бойові донесення з Афганістану та Іраку, а також досьє в’язнів Гуантанамо. Ці матеріали були опубліковані в книзі-бестселері «Відкриті секрети» (“Open Secrets”). Він брав участь у серії публікацій, відзначених Пулітцерівською премією, яка досліджувала неякісні китайські хімікати, що використовуються в американській фармацевтиці. Він отримав освіту в Університеті Міссурі та Лехайському університеті.
Посібник із розслідувань з використанням бібліотек цифрової реклами
Ресурси для пошуку та використання супутникових зображень
Як отримати безкоштовні супутникові знімки: порадник журналіста
Information laundromat: Як працює інструмент для аналізу вмісту та метаданих сайтів

Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Читати далі

Журналістика даних Поради та інструменти
10 типових помилок у журналістиці даних
На конференції NICAR репортер GIJN розпитав спікерів та учасників про прогалини в журналістиці даних, теми, що часто залишаються в тіні, і навички, яких бракує редакціям.

Журналістика даних Профілі членів мережі
Журналістика даних на війні: українські «Тексти» та битва за правду
Як редакція «Текстів» — офіційна назва Texty.org.ua — перетворилися з першого в Україні центру журналістики даних у впливове медіа світового рівня.

Поради Журналістика даних Поради та інструменти
Робота з даними: Практичні поради для невеликої редакції
Кроки, які допоможуть сформувати дата-команду за обмеженого бюджету та штату співробітників. Рекомендації дата-журналістки й турецької редакторки GIJN Пінар Даг.

Методологія Новини та аналітика Поради та інструменти Приклади розслідувань
Використання супутникових знімків у розслідуваннях: Поради Лабораторії доказів Amnesty International
Супутникові зображення – швидкий та економний спосіб підтвердження фактів. Спеціальна радниця з дистанційного зондування лабораторії доказів Amnesty International Міка Фарфур поділилася інструментами, які вона щодня використовує у своїй роботі.