
The Next Wave Is People Data

All photos Creative Commons, Flickr c/o (clockwise: garryknight, justgrimes, r2hox, and ISOVIS)
Governments may have begun Open Data, but the next wave is People Data. Any group in any part of the world can self-organize to collect data about their community and publish it on the cloud to effect change. This is an incredibly powerful development. People know their own communities and needs better than governments and corporations, but they have heretofore lacked the methods and scale to collect data and make it available to all under an open license, with open source software, in an open cloud environment.

Residents of Khayelitsha (Creative Commons photo c/o Chris Preen, Flickr)
People Data empowers individuals to form groups to solve problems that may take too long for governments to solve on their own. For example, poor sanitation in Khayelitsha Township in Cape Town, South Africa, means that residents often don’t know which facilities are working when they need to use them. The local government collects information about maintenance requests and facility function but makes this information available on a website four to six months after incidents are reported. Six months is a long time to wait for timely information about a toilet in your neighborhood!
Using the cloud and Open Data, Khayelitsha residents could construct an SMS application to report sanitation problems to an Open Data repository that makes this information immediately available to the residents. An application like this could be created in less than a week using tools like IBM BlueMix. It could be hosted in the cloud, requiring no infrastructure and skill, and application maintenance could be funded through foundation and grant support. Best of all, local people could take control over an important element of governance for their community by self-organizing, reporting information, and sharing the Open Data as a community resource.
In Australia, 2015 will mark the 100th anniversary of the Gallipoli and ANZACS operations in World War I. ANZACS is an incredibly important part of national identity in Australia and there will be government remembrances and organized activities throughout the year. But Australians can do their part too. They can use Open Data repositories to collect personal stories, photos of artifacts, remembrances, and other data into their own data archives to augment the national archives and bring together human, family, and governmental institutional history into a living national testimony of this important event and all the events and experiences over the past century as Australia has re-experienced the trauma of The Great War.
In the United States, victims of racism, rape, and police brutality could use Open Data repositories to report and collect reports of incidents, human suffering, and personal trauma so as to expose the litany of abuse on a national level and force ongoing testimony and conversation about the impact of these events on personal, local, and national life.
People Data can be a new form of human expression in collective narratives that empower communities to make public information in aggregate which has for too long been silenced by the loneliness of human indignity. All over the world, there are opportunities for communities to help themselves by collecting and publishing their own Open Data as a common public resource. The technology is there. The methods are simple. The benefits are huge.
I predict this is going to take off like a rocket ship in the next year and Data will increasingly be collected and used as Open and Public resources, for the People and by the People.
 Steven Adler (@DataGov) is the chief information strategist for IBM. He is an expert in data science and an innovator who has developed several billion-dollar-revenue businesses in the areas of data governance, enterprise privacy architectures, and Internet insurance. He has advised governments and large NGOs on open government data, data standards, privacy, regulation, and systemic risk. He developed and leads the Open by Default Community, is co-chair of the W3C Data on the Web Best Practices Working Group, and co-chair of the XMILE System Dynamics Technical Committee at OASIS.
Steven Adler (@DataGov) is the chief information strategist for IBM. He is an expert in data science and an innovator who has developed several billion-dollar-revenue businesses in the areas of data governance, enterprise privacy architectures, and Internet insurance. He has advised governments and large NGOs on open government data, data standards, privacy, regulation, and systemic risk. He developed and leads the Open by Default Community, is co-chair of the W3C Data on the Web Best Practices Working Group, and co-chair of the XMILE System Dynamics Technical Committee at OASIS.

A Call for Debate: Taking Open Data and Government to the Next Level

Tipsheet on Partnering with Civil Society Organizations and Non-Governmental Organizations

AI Accountability Reporting Guide

Data Journalism Top 10: Measuring Mask Use, Parental Interruptions, Childbirth Woes, India’s Low Death Rate

Data Journalism Top 10: Bill Gates Conspiracies, COVID-19 Excess Mortality, Home Deaths Spike, Test Kits
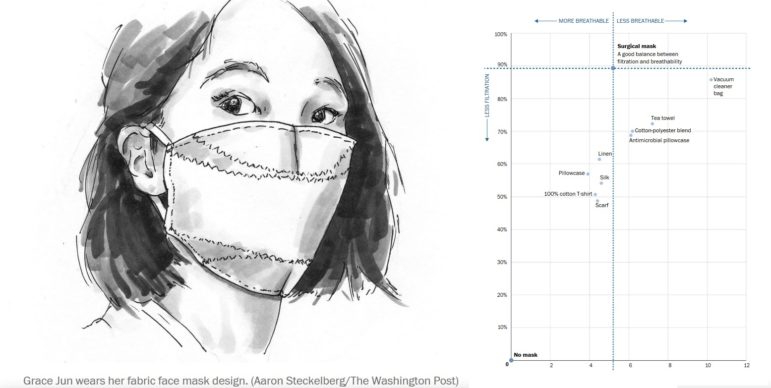
Data Journalism Top 10: Viral Dataviz, DIY Masks, Breaking the Wave, China and US Response to COVID

GIJN’s Data Journalism Top 10: Women and the Oscars, February’s Sad Songs, Hollywood’s Franchises, Moscow’s Elite Owners

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
Data Journalism
Data Journalism Top 10: Measuring Mask Use, Parental Interruptions, Childbirth Woes, India’s Low Death Rate
How widespread is mask use in your country? Our NodeXL #ddj mapping from July 13 to 19 finds The New York Times mapping the odds of people encountering other mask wearers in the United States, two university professors quantifying the number of interruptions a parent suffers on average every hour while working from home, the Committee to Protect Journalists talking to data journalists about the struggles of reporting on COVID-19, and openDemocracy documenting cases of mistreatment of women in labor around the world since the pandemic started.
Data Journalism
Data Journalism Top 10: Bill Gates Conspiracies, COVID-19 Excess Mortality, Home Deaths Spike, Test Kits
Misinformation has grown ubiquitous during the COVID-19 pandemic, so much so that World Health Organization Director-General Tedros Adhanom Ghebreyesus proclaimed: “We’re not just fighting an epidemic; we’re fighting an infodemic.” Microsoft co-founder Bill Gates has emerged as a favorite target of disinformation actors, according to The New York Times, that we discovered through our NodeXL #ddj mapping from April 13 to 19. We also found The Economist and ProPublica examining the true impact of the pandemic by looking into “excess mortalities” such as home deaths, the Associated Press releasing and updating a coronavirus public dataset for the United States.
Data Journalism
Data Journalism Top 10: Viral Dataviz, DIY Masks, Breaking the Wave, China and US Response to COVID
From “flattening the curve” to “social distancing,” and now “breaking the wave,” the global data journalism community is using new terminology in its attempts to explain the intricacies of COVID-19 to the masses. Our NodeXL #ddj mapping from April 6 to 12 finds Reuters Graphics explaining their “breaking the wave” chart, The Washington Post helping readers figure out the best material to use to make their own masks, the Financial Times comparing the response of China and the United States in handling the pandemic, and Press Gazette highlighting the huge appetite for data-driven visual journalism about COVID-19.
Data Journalism
GIJN’s Data Journalism Top 10: Women and the Oscars, February’s Sad Songs, Hollywood’s Franchises, Moscow’s Elite Owners
What’s the global data journalism community tweeting about this week? Our NodeXL #ddj mapping from February 3 to 9 finds UOL highlighting the lack of gender equality among Oscar winners and G1 looking into problems of ageism in the Best Actress category. This edition also has The Economist analyzing Spotify data to find the most depressing month for listeners, Proekt Media investigating property owners in a prestigious residential area in Russia, and The Financial Times spotlighting the lack of innovation in the movie industry.