
Как использовать анонимизацию для защиты своих источников
How Data Journalists Can Use Anonymization to Protect Privacy
Read this article in

Step-By-Step Guide for Journalists on the Basics of Google Sheets

Tipsheet for Using Ocean Data in Your Investigations

No Coding Required: A Step-by-Step Guide to Scraping Websites With Data Miner

GIJC23 – The Future of Data Journalism: New Analytical Tools, Data Visualization, and AI
In the pursuit of a story, journalists are often required to protect the identity of their source. Many of the most impactful works of journalism have relied upon such an arrangement, yet the balancing act between publishing information that is vital to a story and protecting the person behind that information can present untold challenges, especially when the personal safety of the source is at risk.
These challenges are particularly heightened in this age of omnipresent data collection. Advances in computing technology have enabled large volumes of data processing, which in turn promotes efforts to monetize data or use it for surveillance. In many cases, the privacy of individuals is seen as an obstacle, rather than an essential requirement. Recent history is peppered with examples of privacy violations, ranging from Cambridge Analytica’s use of personal data for ad targeting to invasive data tracking by smart devices. The very expectation of privacy protection seems to be withering away in the wake of ongoing data leaks and data breaches.
With more data available than ever before, journalists are also increasingly relying on it in their reporting. But, just as with confidential sources, they need to be able to evaluate what information to publish without revealing unnecessary personal details. While some personal information may be required, it’s likely that most stories can be published without needing to identify all individuals in a dataset. In these cases, journalists can use various methods to protect these individuals’ privacy, through processes known as de-identification or anonymization.
Defining Personal Information
While the definition of what constitutes personal information has become more formalized through legal reform in the late 2000s, it has long been the role of journalists to uncover if a release of data, whether intended or accidental, jeopardizes the privacy of individuals. After AOL published millions of online search queries in 2006, journalists were able to piece together individual identities solely based on individuals’ search histories, including sensitive information about some individuals’ health statuses and dating preferences. Similarly, in the wake of Edward Snowden’s revelations of NSA spying, various researchers have shown how communication metadata — information generated by our devices — can be used to identify users, or serve as an instrument of surveillance.
But, when using a dataset as a source in a story, journalists are put in the new position of having to evaluate the sensitivity of the information at hand themselves. And this assessment starts with understanding what is and isn’t personal information.
Personally identifiable information (PII), legally described as “personal data” in Europe or “personal information” in some other jurisdictions, is generally understood as anything that can directly identify an individual, although it is important to note that PII exists along a spectrum of both identifiability and sensitivity. For instance, names or email addresses have a high value in terms of identifiability, but a relatively low sensitivity, as their publication generally doesn’t endanger an individual. Location data or a personal health record may have lower identifiability, but a higher degree of sensitivity. For illustration purposes, we can plot various types of PIII along the sensitivity and identifiability spectrums.
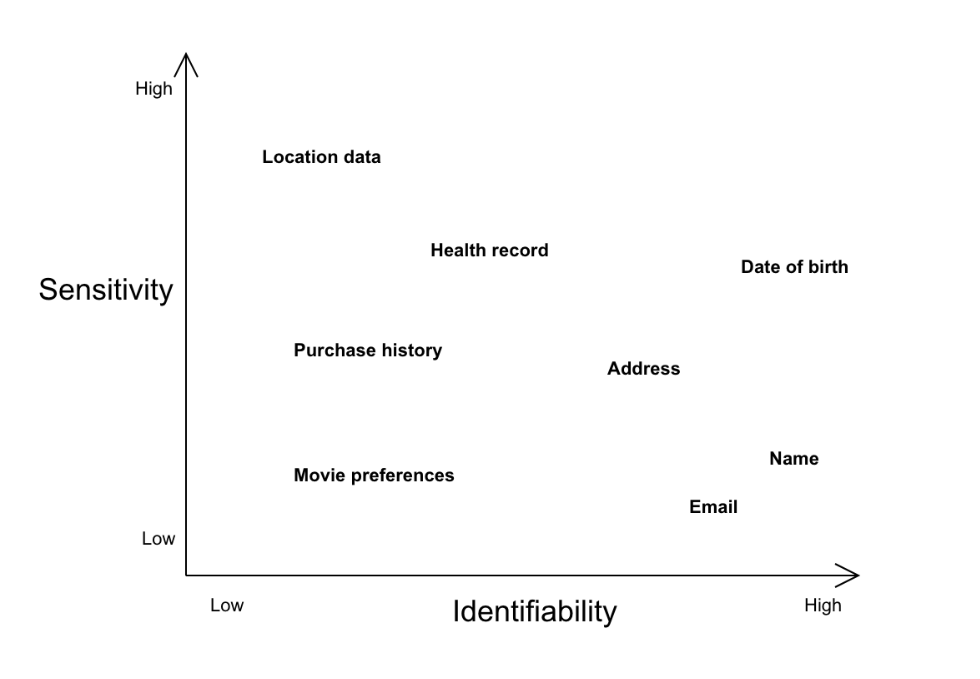
PII exists along a spectrum of sensitivity and identifiability. Image: Datajournalism.com
The degree to which information is personally identifiable or sensitive depends on both context and the compounding effect of data mixing. A person’s name may carry a low risk in a dataset of Facebook fans, but if the name is on a list of political dissidents, then the risk of publishing that information increases dramatically. The value of information also changes when combined with other data. On its own, a dataset that contains purchase history may be difficult to link to any given individual; however, when combined with location information or credit card numbers, it can reach higher degrees of both identifiability and sensitivity.
In a 2016 case, the Australian Department of Health published de-identified pharmaceutical data for research purposes, only to have academics decrypt one of the de-identified fields. This created the potential for personal information to be exposed, prompting an investigation by the Australian Privacy Commissioner. In another example, Buzzfeed journalists investigating fraud among pro tennis players in 2016 published the anonymized data that they used in their reporting. However, a group of undergraduate students was able to re-identify the affected tennis players by using publicly available data. As these examples illustrate, a journalist’s ability to determine the personal nature of a dataset requires a careful evaluation of both the information it contains, and also the information that may already be publicly available.

While these tennis players’ names may appear anonymous, BuzzFeed’s open-source methodology also included other data which allowed for the possibility of re-identification. Image: Datajournalism.com
What Is De-identification?
In order to conceal the identity of a source, a journalist may infer anonymity or use a pseudonym, such as Deep Throat in the case of the Watergate scandal. When working with information, the process of removing personal details is called de-identification or, in some jurisdictions, anonymization. Long before the internet, data de-identification techniques were employed by journalists, for example by redacting names from leaked documents. Today, journalists are armed with new de-identification methods and tools for protecting privacy in digital environments, which make it easier to analyze and manipulate ever larger amounts of data.
The goal of de-identifying data is to avoid possible re-identification, in other words, to anonymize data so that it cannot be used to identify an individual. While some legal definitions of data anonymization exist, the regulation and enforcement of de-identification is usually handled on an ad-hoc, industry-specific basis. For instance, health records in the United States must comply with the Health Insurance Portability and Accountability Act (HIPAA), which requires the anonymization of direct identifiers, such as names, addresses, and social security numbers, before data can be published for public consumption. In the European Union, the General Data Protection Regulation (GDPR) enforces anonymization of both direct identifiers, such as names, addresses, and emails, as well as indirect identifiers, such as job titles and postal codes.
In developing their story, journalists have to decide what information is vital to a story and what can be omitted. Often, the more valuable a piece of information, the more sensitive it is. For example, health researchers need to be able to access diagnostic or other medical data, even though that data can have a high degree of sensitivity if it is linked to a given individual. To strike the right balance between data usefulness and sensitivity, when deciding what to publish, journalists can choose from a range of de-identification techniques.
Data Redaction

An example of a redacted CIA document. Image: Wikimedia
The simplest way to de-identify a dataset is to remove or redact any personal or sensitive data. While an obvious drawback is the possible loss of the data’s informative value, redaction is most commonly used to deal with direct identifiers, such as names, addresses, or social security numbers, which usually don’t represent the crux of a story.
That said, technological advances and the growing availability of data will continue to increase the identifiability potential of indirect identifiers, so journalists shouldn’t rely on data redaction as their only means of de-identification.
Pseudonymization
In some cases, removing information outright limits the usefulness of the data. Pseudonymization offers a possible solution, by replacing identifiable data with pseudonyms that are generated either randomly, or by an algorithm. The most common techniques for pseudonymization are hashing and encryption. Hashing relies on mathematical functions to convert data into unreadable hashes. Encryption, on the other hand, relies on a two-way algorithmic transformation of the data. The primary difference between the two methods is that encrypted data can be decrypted with the right key, whereas hashed information is non-reversible. Many databases systems, such as MySQL and PostgreSQL, enable both the hashing and encryption of data.
Data pseudonymization played an important role in the Offshore Leaks investigation by the International Center for Investigative Journalism (ICIJ). Given the vast volume of data that needed to be processed, journalists relied on unique codes associated with each individual and entity that appeared in the leaked documents. These pseudonymized codes were used to show links between leaked documents, even in cases when the names of individuals and entities didn’t match.
Information is considered pseudonymized if it can no longer be linked to an individual without the use of additional data. At the same time, the ability to combine pseudonymized data with other datasets renders pseudonymization a possibly weak method of de-identification. Even by using the same pseudonym repeatedly throughout a dataset, its effectiveness can decrease, as the potential for finding relationships between variables grows with every occurrence of the pseudonym. Finally, in some cases, the very algorithms used to create pseudonyms can be cracked by third parties, or have inherent security vulnerabilities. Therefore, journalists should be careful when using pseudonymization to hide personal data.
Statistical Noise
Since both data redaction and pseudonymization carry the risk of re-identification, they are often combined with statistical noise methods, such as k-anonymization. These ensure that at least a set number of individuals share the same indirect identifiers, thereby obscuring the process of re-identification. As a best practice, there should be no less than 10 entries with unique combinations of identifiers. Common techniques for introducing statistical noise into a dataset are generalization, such as replacing the name of a country with a continent, and bucketing, which is the conversion of numbers into ranges. In addition, data redaction and pseudonymization are often used with statistical noise techniques to ensure that no unique combinations of identifiers exist in a dataset. In the following example, data in certain columns is generalized or redacted to prevent re-identification of individual entries.
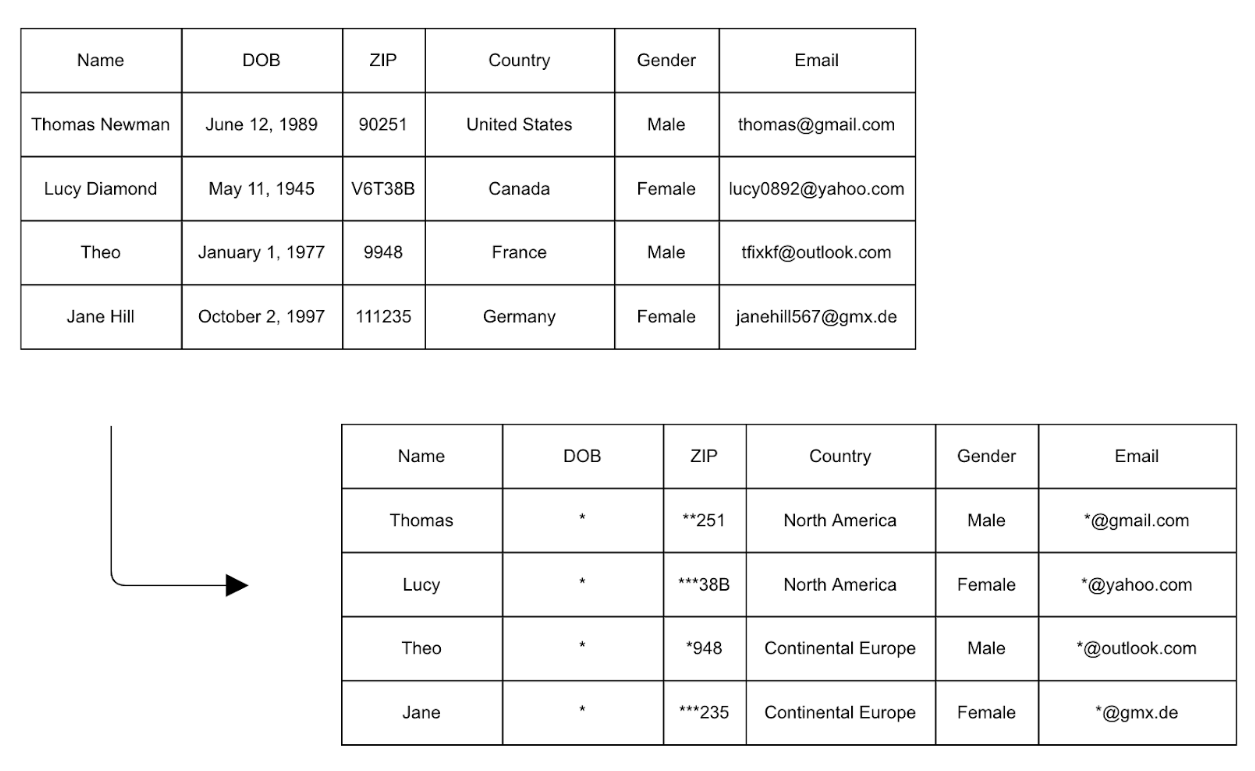
Adding statistical noise to prevent re-identification. Image: Datajournalism.com
Data Aggregation
When the integrity of raw data doesn’t need to be preserved, journalists can rely on data aggregation as a method for de-identification. Instead of publishing the complete dataset, data can be published in the form of summaries that omit any direct or indirect identifiers. The principal concern with data aggregation is ensuring that the smallest segments of the aggregated data are large enough, so as to not reveal specific individuals. This is particularly relevant when multiple dimensions of aggregated data can be combined.
De-identification Workflows
For journalists on a deadline, de-identification may appear to play second fiddle to more substantive decisions, such as assessing data quality or deciding how to visualize a dataset. But ensuring the privacy of individuals should nevertheless have a firm place in the journalistic process, especially since improper handling of personal data can undermine the very credibility of the piece. Legal liability under privacy laws may also be of concern if the publication is responsible for data collection or processing. Therefore, data journalists should take the following steps to incorporate de-identification into their workflows:
- Does my dataset include personal information?
It may be the case that the dataset you are working with includes weather data, or publicly available sport statistics, which absolves you from the need to worry about de-identification. In other cases, the presence of names or social security numbers will quickly make any privacy risks apparent. Often, however, determining whether data is personally identifiable may require a closer examination. This is particularly the case when working with leaked data, as explained in this long read by Susan McGregor and Alice Brennan. Aside from noting the presence of any direct identifiers, journalists should pay close attention to indirect identifiers, such as IP addresses, job information, and geographical records. As a rule of thumb, any information relating to a person should be considered a privacy risk and processed accordingly.
- How sensitive and identifiable is the data?
Personal information carries different risks based on the context in which it exists, including whether it can be combined with other data. This means that journalists need to evaluate two things: 1) how identifiable a piece of data is and 2) how sensitive it is to the privacy of an individual. Ask yourself: Will an individual’s association with the story endanger their safety or reputation? Can the data at hand be combined with other available datasets that may expose an individual’s identity? If so, do the benefits of publishing this data outweigh the associated privacy risks? A case by case approach is required to balance the public interest in publishing with the privacy risks of revealing personal details.
- How will the data be published?
A journalist writing for a print publication in the pre-internet era didn’t have to worry about how data would be disclosed, as printed charts and statistics do not allow for the further querying of their underlying data. However, at the cutting edge of data journalism today, sophisticated tools and interactive visualizations enable audiences to undertake a detailed examination of the data used in a particular story. For example, many journalists opt for an open source approach, with code and data shared on GitHub. To open source with privacy in mind, all data needs to be carefully scrubbed of personal information. When it comes to visualizations, some journalists protect privacy by leveraging pre-aggregated data, which obfuscates the original dataset. But it’s important to check whether these aggregated samples exceed a minimum threshold of identifiability.
- Which de-identification technique is right for your data?
Journalists will often need to deploy a combination of de-identification techniques to best suit the data at hand. For direct identifiers, data redactions and pseudonymization — if properly implemented — usually suffice in protecting the privacy of individuals. For indirect identifiers, consider adding some statistical noise by grouping data into buckets or generalizing information that may not be vital to the story. Data aggregation is the best option for highly sensitive data, although journalists still have to ensure that there is a broad enough range of data and sufficiently uniform distribution in the aggregated variables to ensure that no personal information is inadvertently exposed.
Leading by Example
Once data is available online, there is no possibility for revisions or corrections. Even if you consider that your dataset has been scrubbed of any personal details, there remains a risk that someone, somewhere may combine your data with another source to re-identify individuals, or crack your pseudonymization algorithm and expose the personal information that it contains. As always, the risks of re-identification will continue to increase with the development of new technologies, such as machine learning and pattern recognition, which enable unanticipated ways of combining and transforming data.
Remember that seemingly impersonal data points may be used for identification purposes when combined with the right data. When Netflix announced its notorious Netflix prize for the best recommendation algorithm, the available data was scrubbed of any personal identifiers. But again, researchers were able to cross-reference personal movie preferences with data from IMDb.com and other online sources to identify individuals in the “anonymized” Netflix dataset.
Despite the limitations of today’s de-identification methods, journalists should always be diligent in their efforts to protect the privacy of individuals.
Leading by example, the ICIJ handles vast volumes of personal data with privacy front of mind. When reporting on the Panama Papers, journalists both protected the anonymity of the source of the leak, by using the pseudonym John Doe, and carefully evaluated how to publish the private information within the leaked documents. There is no reason why journalists of all backgrounds can’t take similar steps to strike a balance between privacy and the public interest in their reporting.
And there are many examples of possible fallouts from disclosure of personal data when privacy conscious steps aren’t taken, from personal tragedies following the Ashley Madison [extramarital dating website] leak, or the vast exposure of sensitive data associated with Wikileaks. Data journalists should strive to avoid the same pitfalls and instead promote responsible data practices in their reporting at all times.
This article was originally published by Datajournalism.com. The version published by GIJN has been shortened but you can read the full piece here. We are republishing with permission.
Additional Reading
How The New York Times Is Visualizing the Smartphone Tracking Industry
Offshore Leaks Database by the International Consortium of Investigative Journalists
Privacy and Data Leaks: How to Decide What to Report
 Vojtech Sedlak is a data scientist who currently works at SumOfUs, an organization trying to curb the growing power of corporations. He previously worked at Mozilla and OpenMedia and keenly follows the RStudio, measure slack, and open data communities and is a big fan of open source analytical practices.
Vojtech Sedlak is a data scientist who currently works at SumOfUs, an organization trying to curb the growing power of corporations. He previously worked at Mozilla and OpenMedia and keenly follows the RStudio, measure slack, and open data communities and is a big fan of open source analytical practices.
Step-By-Step Guide for Journalists on the Basics of Google Sheets
Tipsheet for Using Ocean Data in Your Investigations
No Coding Required: A Step-by-Step Guide to Scraping Websites With Data Miner
GIJC23 – The Future of Data Journalism: New Analytical Tools, Data Visualization, and AI

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
Data Journalism
One Name at a Time: How Die Zeit Built a Searchable Database of Nazi Party Members
An online tool set up by the German newspaper Die Zeit, in cooperation with archives in Germany and in the United States, allows people to search several million Nazi Party membership cards.

Data Journalism
How the Hindu Is Embedding AI Into Its Data Journalism
LLMs are quietly reshaping data journalism workflows at The Hindu, helping reporters process vast document sets, write scripts and build interactive tools.

Data Journalism
Developing a Data State Of Mind: Key Tips for Editors
Data is woven into how journalists cover everything from local government spending to global climate change patterns, but for editors without a specialist background, it can be daunting.

Data Journalism
2026 Sigma Awards for Data Journalism Open for Entries – Deadline Extended
The Sigma Awards celebrate the best data journalism from around the world. Submissions are now open for data projects published in 2025.