
Превращение нечитаемого текста в доказательства. Фото предоставлено Хенком ван Эссом.
Как превратить нечитаемый текст в доказательства: Советы Хенка ван Эсса
ЧИТАЙТЕ ЭТУ СТАТЬЮ НА ДРУГИХ ЯЗЫКАХ

Ресурс Путеводитель
Расследования по открытым источникам с Хенком ван Эссом

Ресурс Путеводитель Глава
Методы Хенка ван Эсса для поиска в соцсетях: Facebook

Ресурс Путеводитель Глава
Методы Хенка ван Эсса для поиска в соцсетях: Instagram

Ресурс Путеводитель Глава
Методы Хенка ван Эсса для поиска в соцсетях: X (бывший Twitter)

Ресурс Путеводитель Глава
Методы Хенка ван Эсса для поиска в TikTok и Telegram

Ресурс Путеводитель Глава
Методы Хенка ван Эсса для поиска в соцсетях: LinkedIn

Ресурс Путеводитель Глава
Методы Хенка ван Эсса: Простые способы распознавания лиц
Ресурс Путеводитель Глава
Как превратить нечитаемый текст в доказательства: Советы Хенка ван Эсса
Ресурс Путеводитель Глава
Выявление контента, созданного с помощью ИИ: Пособие для журналистов




Вам знакомо это чувство, когда вы смотрите на важнейший элемент доказательства — размытый номерной знак, пиксельный документ с именами, которые невозможно разобрать, зернистый скриншот, который содержит нужную вам информацию, закрытую густой вуалью пикселей?
От этих нескольких пикселей в OSINT зачастую зависит, окажетесь ли вы в тупике или совершите прорыв в расследовании.
Если вам это чувство не знакомо, то вы — счастливчик. В своих расследованиях я постоянно сталкиваюсь с этой проблемой — будь то извлечение текста из видео, расшифровка элементов чисел из постов в социальных сетях или чтение искажённого текста в документах. Пока все вокруг живут свою жизнь, я играю в игру «угадай пиксель». Но я не жалуюсь. Способность превращать нечитаемые символы в осмысленную информацию — восхитительна.
Пора создать пособие по преобразованию размытой бессмыслицы в нечто осмысленное. Инструменты и методы, описанные в этой статье, взяты не из теории. Это практические методы, которые вы можете применить к собственным трудночитаемым доказательствам. Потому что в OSINT зачастую извлечь информацию из последних нескольких пикселей означает выйти из тупика и совершить прорыв.
Настоящая работа происходит у вас между ушами. Её суть — знать, какие инструменты комбинировать, как проверять результаты и когда доверять (или не доверять) своим результатам. Ведь, в конце концов, разница между аматорским подходом и профессиональным расследованием — это наличие системы, которая работает всегда — даже когда пиксели оказывают сопротивление.
Размытый номерной знак
У тех, кто проводят расследования на основе открытых источников, есть свои любимые инструменты. Попросите любого специалиста дать пару рекомендаций — и они начнут говорить «просто используй Topaz Gigapixel Pro» или «попробуй любой инструмент Neural Single Image Deblurring на основе Gyro — вот список всех этих инструментов. Но решение далеко не всегда найдётся в вашем любимом приложении; зачастую оно состоит в том, чтобы признать, что вам известно не всё.
Во время сессии в Лондоне я показал этот размытый номерной знак 50 людям из BBC Verify. Большинство из них могли сходу назвать три инструмента, которые должны были помочь восстановить резкость изображения. Но дело в том, что все они оказались бесполезны. И какие тогда остаются варианты?

Размытый номерной знак. Фото предоставлено Хэнком ван Эссом.
Мой любимый приём в 2025 году: я помещаю свои провальные попытки в чат-бот, словно это цифровая терапевтическая сессия: «я пробовал Topaz, Remini, DeblurGAN v2, ImageJ+ DeconvolutionLab2», и наблюдаю, как он мне предлагает попробовать «BeFunky Image Editor». Серьёзно? Я до этого ни разу не слышал о BeFunky. Но этот бесплатный инструмент с названием, которое больше напоминает отвергнутый Netflix фильм, на поверку оказывается лучше, чем навороченное программное обеспечение за 200 долларов США. И в этот момент проявляется максимальная растерянность: «наверное, я знаю не всё». И честно говоря, именно здесь происходят настоящие прорывы.

Результаты применения BeFunky Image Editor. Фото предоставлено Хэнком ван Эссом.
Этот инструмент больше не давал хороших результатов, однако, когда я указал его в списке других испробованных мной инструментов, я получил новые предложения. Порой, когда делишься своими неудачами, получаешь самые ценные советы. Когда удалось прочитать текст, нужно найти контекст.
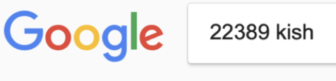
Когда я исследовал номерной знак красного Chevrolet Camaro (на котором ездил голландский преступник), рассмотреть цифры труда не составило. Моя проблема состояла в обратном поиске изображений. Иногда Google просто не распознаёт обрезанную деталь фотографии.

Иногда Google просто не распознаёт обрезанную деталь фотографии. Фото предоставлено Хэнком ван Эссом.
Эту загвоздку можно обойти, если вместо обратного поиска самой фотографии в Google Images ввести видимый текст. Это привело меня к фотографиям туристов в Иране на том же красном Chevrolet Camaro, с тем же номерным знаком. Ах да, преступник брал эту машину в аренду (читайте эту историю здесь).

Красное авто помогло разыскать преступника. Фото предоставлено Хэнком ван Эссом.
Открытый ноутбук
Ловите профессиональный совет, который звучит практически неправдоподобно: если ваш текст не полная каша, просто попросите ИИ прочитать его для вас. Никаких модных инструментов, никакой магической обработки изображений — просто загрузите его и спросите: «Что здесь написано?» Сейчас мой фаворит — Gemini Pro 2.5, который, видимо, решил стать самым высококвалифицированным корректором в мире.
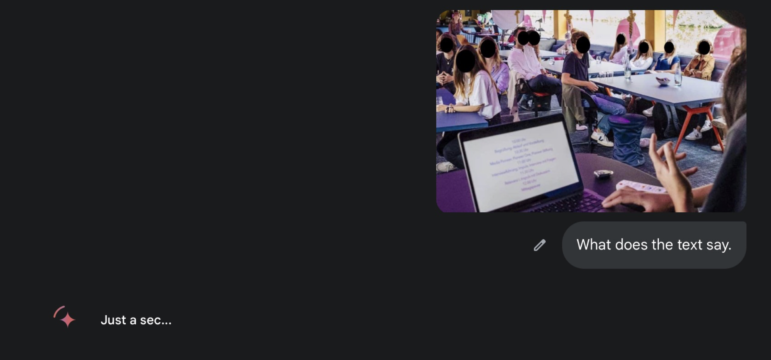
Что написано на мониторе компьютера. Фото предоставлено Хэнком ван Эссом.
Пока вы щуритесь, пытаясь разобрать: это «а» или грустный смайлик, чат-бот уже расшифровал и перевёл нечитаемый текст:

Фото предоставлено Хэнком ван Эссом.
170 нечитаемых слов
Посмотрите на эту фотографию. Я много путешествую, поэтому не могу таскать за собой мониторы. Вместо этого для работы я использую очки виртуальной реальности. Сколько слов вы можете разобрать на этом скриншоте, который я нарочно размыл по максимуму?
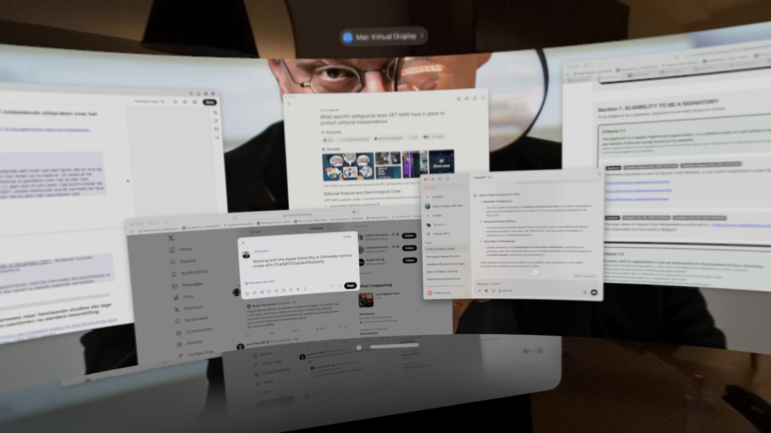
Очки виртуальной реальности. Фото предоставлено Хэнком ван Эссом.
Пока вы продолжаете щуриться на изображение, я загрузил его в Gemini 2.5 Pro. Он смог прочитать на этом фото около 170 слов и точно резюмировал то, чем я на самом деле занимался.
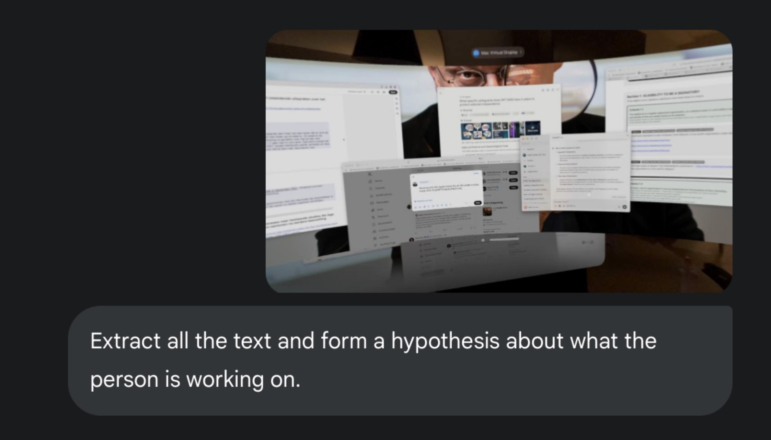

Расшифровка нечитаемого текста. Фото предоставлено Хэнком ван Эссом.
Геолокация с помощью текста
Недавно я провёл две недели в Берлине по работе. Мне нравится вести небольшие водные курсы OSINT для студентов. В них я показываю, насколько эффективными могут быть методы онлайн-расследований. Студенты не только учатся — они также ужасаются и немедленно бросаются проверять свои настройки приватности.
Давайте проанализируем эту фотографию. Вопрос: Где и когда она сделана?

Геолокация с помощью текста. Фото предоставлено Хэнком ван Эссом.
Благодаря знаку «парковка велосипедов запрещена» понятно, что можно исключить Мальту, Кипр, Испанию, Люксембург и Великобританию, а наиболее вероятные кандидаты — Нидерланды, Дания и Финляндия. Объяснение здесь очень простое: знак «парковка велосипедов запрещена» распространён в странах, где все ездят на велосипедах. Эти знаки вряд ли используются там, где на велосипедах никто не ездит. Они нужны там, где на велосипедах ездит так много людей, что им нужно активно говорить не парковаться здесь. Это как если бы вы увидели знак «купание запрещено» на пляже, а не посреди Сахары. В первом случае это забота об общественной безопасности, во втором — мираж. Вы видите текст, который появляется дважды — слово «essen» или заканчивающиеся на «essen» и зеленоватый логотип с несколькими словами на нём. В этом случае ИИ справился с расшифровкой ничуть не лучше нас:
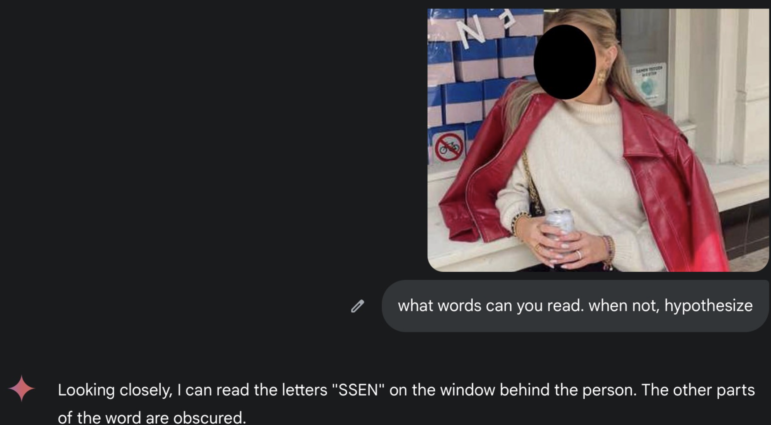
Здесь ИИ не справился с расшифровкой нечёткого текста. Фото предоставлено Хэнком ван Эссом.
Возможно, нас снова выручит BeFunky? Он улучшил качество текста настолько, что я смог прочитать слова «samen redden»? Это означает, что текст на голландском языке, и он гласит «samen redden [что-то ]», в переводе это означает «вместе спасти [что-то ]».

Расшифровка нечитаемого текста. Фото предоставлено Хэнком ван Эссом.
Что же требует спасения? Это наклейка на окне магазина или ресторана, поэтому вряд ли там написано что-то вроде «вместе спасти… коммунизм». Может, там написано «вместе спасти… капитализм»?
Нет, забудьте — это слишком. Наверное, там что-то воодушевляющее вроде «вместе сэкономить… энергию» или «вместе спасти… китов», или «вместе сэкономить… на парковке». Или, возможно… Подождите, нет — кажется, я снова мудрю. Не надо выдумывать. Хватит гадать. Начните искать.
Мы можем быть практически уверены в том, что после «вместе спасти» стоит одно или два слова — вероятно, не более семи символов, если размер шрифта такой же, как в первой строке. Теперь самое интересное: каким образом объяснить Google эту невероятно специфическую оценку количества слов, основанную на анализе шрифта, не звуча при этом как сторонник теорий заговора, который перебрал кофе? В этом месте обычные поисковые запросы пересекаются с судебной типографикой (которую мы обсудим во второй части этой статьи) — и сразу возникают сомнения в правильности выбора профессии.
Как сказать Google, что вы не знаете правильных слов?
Замените неизвестные элементы звёздочкой:

Иллюстрация предоставлена Хэнком ван Эссом.
Зачем использовать кавычки? Потому что без них Google предполагает, что вы имели в виду «samen» и «redden» где угодно, тогда как на самом деле вам нужны эти слова рядом в именно таком порядке. Кавычки заставляют Google найти эти слова как реальную фразу, а не разбросанными по разным абзацам, как языковое конфетти. И что самое важное, когда вы добавляете эту звёздочку в конце, вы говорите Google:
«После этих слов текст продолжается, не показывай мне результаты, где на этом месте предложение заканчивается».
По сути, это означает: «Нет, я правда имею в виду, что эти два слова рядом, и я знаю, что текст на этом не заканчивается». Вот результат:

Иллюстрация предоставлена Хэнком ван Эссом.
Оказывается, это «samen redden we eten» — из приложения Too Good to Go. Прежде чем мы пойдём дальше, давайте проясним, почему мы использовали Google Images. Обычный поиск в Google оказывается сложнее обработки естественного языка, тогда как Google Images как будто говорит: «О, вы хотите найти текст в изображениях? У меня их миллионы, и я вам покажу те из них, где эти слова стоят рядом, в том числе такие, о существовании которых вы даже не подозревали».
Разница здесь такая же, как если бы вы попросили библиотекаря дать вам книги о «совместном спасении еды» и показать вам все фотографии, на которых есть именно эти слова. В первом случае вы получите статьи и размышления, а во втором –– реальные витрины магазинов и плакаты компаний. Как этот прекрасный новый инструмент, который показывает все тексты в режиме StreetView в Нью-Йорке:

Иллюстрация предоставлена Хэнком ван Эссом.
Вернёмся к нашему делу. Too Good to Go –– это, по сути, приложение знакомств с овощами и сегодняшней выпечкой, в котором рестораны, магазины и кафе выставляют свою непроданную еду, чтобы спасти её в последний момент.

Иллюстрация предоставлена Хэнком ван Эссом.
Пора исследовать буквы «SSEN». Следующая остановка –– Claude, семантический анализатор.
Я дал ему конкретику –– голландские слова на окнах ресторанов или магазинов, заканчивающиеся на «essen» –– и он мгновенно выдал «Delicatessen». Естественно. Пока я играл в детектива, настоящее решение состояло в том, чтобы просто спросить ИИ, который специализируется на языковых паттернах.
Иллюстрация предоставлена Хэнком ван Эссом.
Иногда самый простой подход –– просто признать, что здесь нужен мозг лучше моего, особенно если он владеет голландским.
Я скачал приложение Too Good to Go и стал искать delicatessen. Чуда не произошло. Claude объяснил, почему:
Иллюстрация предоставлена Хэнком ван Эссом.
Большинство объектов находятся в Амстердаме, поэтому я начал оттуда. На окне стоят бело-синие коробки.

Иллюстрация предоставлена Хэнком ван Эссом.
Держите маленькую забавную уловку, о которой вам никто не расскажет: если ваше расследование зависит от конкретных цветов, просто добавьте их в конце поиска в Google Images, как если бы они были своего рода цифровым алгоритмом.

Иллюстрация предоставлена Хэнком ван Эссом.
Это как добавить посыпку к мороженому, только посыпка –– криминалистические доказательства, а мороженое –– поиск в Google. Внезапно «Delicatessen Amsterdam white blue» превращается в невероятно конкретный запрос, который, минуя все общие списки ресторанов, выводит вас к магазинам с теми самыми цветными коробками на подоконнике. Кто бы знал, что цвета могут быть параметрами поиска? Это очевидно до гениальности.

Иллюстрация предоставлена Хэнком ван Эссом.
Наш первый кандидат –– магазин Flo’s Deli в Амстердаме.

Иллюстрация предоставлена Хэнком ван Эссом.
И, представьте себе, это точное совпадение с первой попытки.
Мы здесь столкнулись с OSINT-эквивалентном выигрыша в лотерею с первого билета. Видите, слева наша отправная точка –– неизвестная особа в красной куртке, сидящая около магазина, который может находиться буквально где угодно в Европе. У неё заботливо зачернено лицо, потому что, видимо, приватность всё ещё важна. Нам осталось отработать только знак «парковка велосипедов запрещена» и непонятные цветные узоры, которые могут оказаться чем угодно: рекламой барбершопа или необычной доской для крестиков-ноликов.
Справа показан кульминационный момент: магазин Flo’s Deli с надписью «samen redden we eten», на котором мы так надолго зациклились, и с точно такой же чередой бело-синих коробок и знаком «парковка велосипедов запрещена», который гордо маячит там, словно говорит: «да, это именно то место!»
Пометавшись между разными инструментами анализа ИИ, как мячик для цифрового пинбола, мы с их помощью выясняем, что да –– эта фотография вероятно была сделана весной или осенью (спасибо роботам за прекрасную работу по выяснению сезона). И на этом с помощью проверенного классического инструмента из арсенала OSINT –– Time Machine (машины времени) в Google Maps –– мы завершаем первую часть «Превращения нечитаемого текста в доказательства».

Иллюстрация предоставлена Хэнком ван Эссом.
В мае 2022 года этот магазин ещё не открылся. Поэтому на снимке время между маем 2022 года и сегодняшним днём, правильно?

Иллюстрация предоставлена Хэнком ван Эссом.
Ну, если у вас много времени и более достойного занятия нет, то вы можете даже выяснить точное время –– для этого надо пересмотреть тысячи фотографий этого магазина, сделанных туристами. Потому что, очевидно, это вполне нормальный способ потратить полдня.
Что за сине-белые коробки? В них рогалики.

Иллюстрация предоставлена Хэнком ван Эссом.
В великой схеме расследовательских прорывов это открытие настолько же значимое, как то, что лёд холодный. Но вот прекрасное своей нелепостью открытие: рассматривая другие контекстные фотографии и отслеживая сезонное повышение и снижение уровня коробок с рогаликами, можно действительно точно определить, что фотография сделана осенью 2024 г.
Итак, что мы узнали? Что иногда продвинутые техники криминалистического исследования означают попросить чат-бота ИИ о помощи, что инструмент за 200 долларов может проиграть редактору под названием «BeFunky», и что теперь анализ спада и подъёма потребления рогаликов в Амстердаме –– серьёзная детективная работа.
Но вот настоящий вывод: секрет превращения нечитаемого текста в читаемый не в одном инструменте. Здесь важно наличие системы: тщательно изучайте каждую деталь, комбинируйте разные подходы, признавайте, когда вы застряли, и просите помощи (даже у ИИ).
В следующий раз мы представим вашему вниманию больше приёмов Тимми Аллена из команды Bellingcat на примере нашего расследования китайской кредитной карты. В частности мы расскажем, как разгадать финансовые загадки с помощью сильно размытой видеозаписи. Поскольку, похоже, именно этим может занять своё типичное воскресенье современный специалист по цифровой криминалистике.
Примечание редактора: Эта статья впервые появилась в издании Digital Digging, информационном бюллетене Хэнка ван Эсса на платформе Substack. Её слегка отредактировали и перепечатали здесь с его разрешения.
 Хэнк ван Эсс родом из Голландии, он преподаёт, выступает и пишет об онлайн-разведке в открытых источниках и исследованиях с помощью ИИ. Популярный лектор и тренер, он путешествует по всему миру и проводит семинары по интернет-расследованиям. Его проекты: Digital Digging (ИИ и расследования), Fact-Checking the Web, Пособие по дата -журналистике (загрузка бесплатная) и выступления в качестве специалиста по социальным сетям и расследования в интернете.
Хэнк ван Эсс родом из Голландии, он преподаёт, выступает и пишет об онлайн-разведке в открытых источниках и исследованиях с помощью ИИ. Популярный лектор и тренер, он путешествует по всему миру и проводит семинары по интернет-расследованиям. Его проекты: Digital Digging (ИИ и расследования), Fact-Checking the Web, Пособие по дата -журналистике (загрузка бесплатная) и выступления в качестве специалиста по социальным сетям и расследования в интернете.

Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Перепечатывайте наши статьи бесплатно по лицензии Creative Commons
Перепостить эту статью
Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Читать дальше

Советы и инструменты
8 журналистов-расследователей поделились своими любимыми инструментами
Новые, хорошо известные или созданные для других целей инструменты, которые оказались неожиданно удобными и стали самыми любимыми у 8 наших коллег-журналистов из разных стран.
Вы применяете методы OSINT, даже не догадываясь об этом
Как геолоцировать изображение с помощью грамотного поискового запроса в Google? Несколько неожиданных и простых трюков от независимого исследователя открытых источников Юри ван дер Вейде.
Журналистика данных
Инструментарий GIJN: спутниковые данные, поиск по логинам и распознавание лиц
Анализ спутниковых изображений в инфракрасном спектре, противоречивая практика применения технологии распознавания лиц, отправка запросов к NASA о предоставлении спутниковых данных, новый инструмент поиска документов от Google и кое-что ещё.

Советы Журналистика данных
Использование солнца и теней для геолокации фото и видео
Расследователь и тренер Bellingcat Юрий ван дер Вайде пошагово разъясняет, как инструмент SunCalc можно использовать не только для определения времени съёмки (хронолокации), но и для определения места (геолокации).