
Digging Up Hidden Data with the Web Inspector
Read this article in
Many reporters never notice the “inspect element” option below the “copy” and save-as” functions in the right-click menu on any webpage related to their investigation.
But it turns out that this little-used web inspector tool can dig up a wealth of hidden information from a site’s source code, reveal the raw data behind graphics, and download images and videos that supposedly cannot be saved.
A simple understanding of this tool and HTML basics can also help reporters scrape data from any web page, with no background in computer science needed.
At IRE21, the Investigative Reporters & Editors’ annual conference, journalist and educator Samantha Sunne shared tips for journalists with little to no coding experience on how to retrieve and analyze data from any web page using two simple tools: the Web Inspector and Google Sheets.
Here are five ways you can use these tools to extract and analyze data from any web page:
1. “Inspect” a website’s source code to extract links, photos, and embedded content.
Every browser offers a version of the Web Inspector in its Developer Tools or Develop tab.
“Browsers are reading the ‘source code’ – the code that makes up the webpage – and displaying it to the user,” explained Sunne.
In her tutorial, Sunne detailed the ways the inspection tool appears on different browsers. In Safari, for example, you can right click on the area of a page you want to inspect and select “Inspect Element.”
With this, you’ll be able to find any hyperlinks and the source of any other materials embedded on the web page. You’ll also be able to read alt text — used to describe the function or content of an image or element on a page — and captions of images, which could include the names of people shown, the location it was taken, and more.
You can refer to an HTML reference guide to find the code identifying embedded photos (<img src=”url”>), as well as links (<a href=”url”>), and other elements.
2. Save images and videos from any website (even Instagram).
“Getting ahold of hard-to-get files is one great way to use the Web Inspector,” according to Sunne.
One key advantage is the ability to retrieve original files, even from websites such as Instagram, which otherwise prevent you from saving the photos or videos they host. It takes just three easy steps:
- Right click on the photo or video you want to download and choose “Inspect.” Perform a page search (control or command + F) looking for “<video>” tags, which will bracket the video’s source code.
- The Web Inspector will automatically identify all instances in which “<video>” appears in the source code. Then, hover over the highlighted links to find the source link preceded by “src=”. Or, step through all the images/tags:

- Finally, click on the source link to open up the photo or video in a separate browser tab and download it with a simple right click.
3. Collect data in an automatically updating spreadsheet.
You’ve gotten your hands on a great dataset crucial to your investigation, but it’s located on a webpage and you can’t download the data as a spreadsheet. So what do you do now?
“Copying and pasting from the webpage works,” Sunne noted. “But the information won’t stay updated, or show me additional information, like the websites the links are leading to.”
Here again, the Web Inspector comes in handy. With it, you can identify the type of data stored on the web page, import it into a Google Sheet, then analyze or visualize it in different ways.
In the example below, we used the Web Inspector to scrape COVID-19 rates from the European Centre for Disease Prevention and Control.
To retrieve the table from this website, we followed these steps:
- Right-click on the table or other data set you want to copy and select Inspect to find out what kind of HTML element it is – common elements are “table”, bullet lists (“ul”), and links (“a”).
- The Web Inspector will highlight elements on the web page and show the corresponding source code. This is how you can identify HTML elements such as this table.
- Fill in the following formula in a new Google Sheet with the element you want extracted — in this case, “table.” If there is only one table on the page you are scraping, the ID will be 0; if there are two, the second table’s ID will be 1, and so on.
=ImportHTML(“url”,“table”,”ID”)
- When you enter the =ImportHTML formula, Google Sheets provides you with an example and explanation for how the formula functions and the kinds of data it can retrieve.
=ImportHTML(“https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases”,“table”,0)
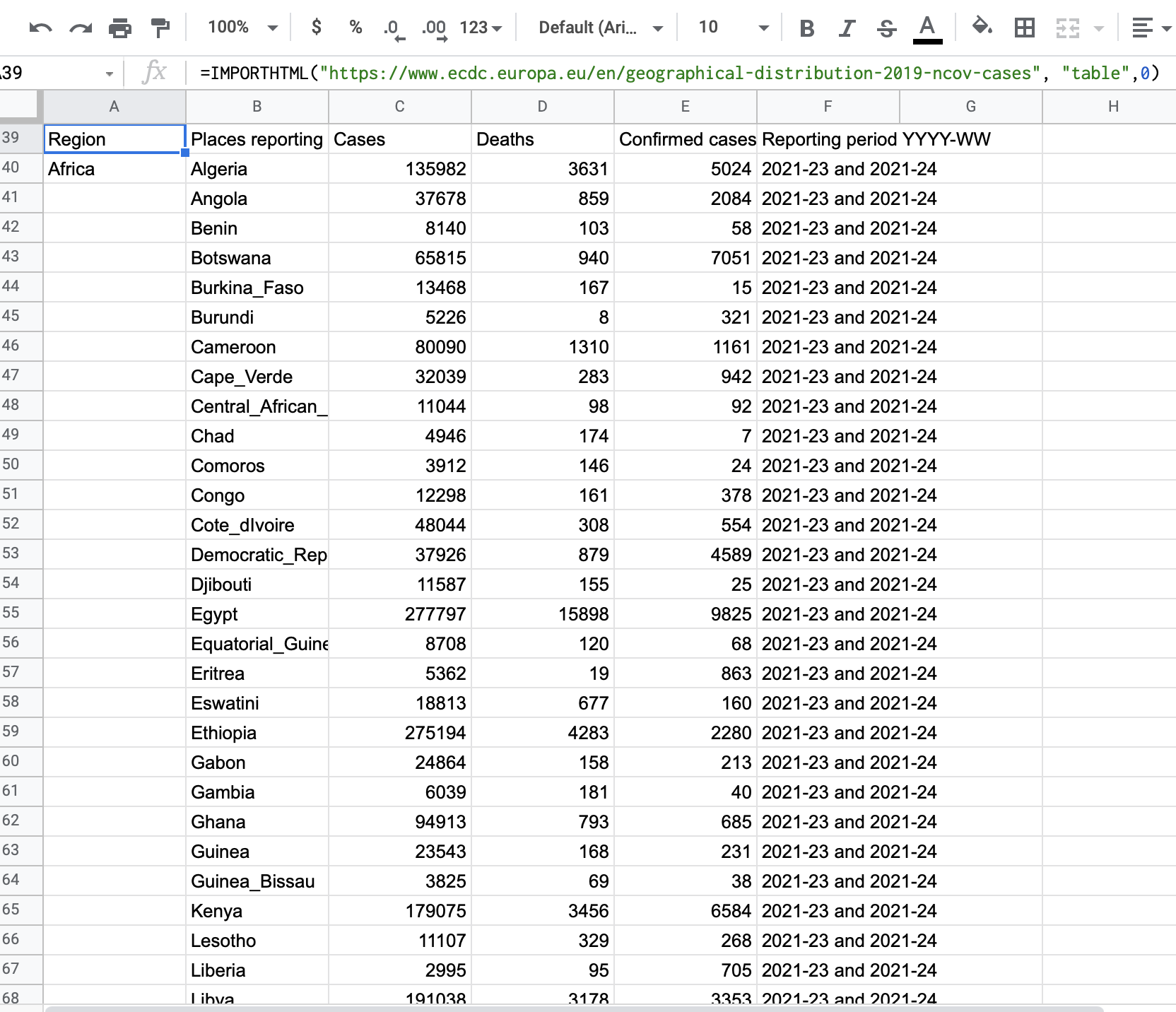
- Google Sheets will automatically fill the spreadsheet with data scraped from the web page. You can then organize, filter, and visualize the data according to your needs.
“The formula is using the source code to pull in the HTML element ‘table,’” Sunne said. She goes into more detail in her Scraping without Programming tutorial.
4. Extract only a specific type of data
Downloading all of a table or page’s data can be useful in your investigation, but what if you’re searching for all the images on a page or all the links to sources in a report?
Google Sheets allows you to perform this kind of scraping too, using the =ImportXML(“url”,”xpath_query”) formula.
“An XPATH is basically like an address to a bit of data on a page,” Sunne explained. It allows you to retrieve data, even when it’s not formatted, into a neat table on the webpage.
In the panel, Sunne showed examples of useful XPATHs, such as for scraping all headers containing a specific country name.
If you want to keep track of interesting clips on your investigation topic, you could also scrape URLs and headlines from any news site using this formula:
=IMPORTXML(“url”,”//CLASS[contains(”country”)]”)
=IMPORTXML(“https://www.nytimes.com/section/world”,”//h2“) will scrape all of the “h2” elements from the page into the Google Sheet.
=IMPORTXML(“https://www.nytimes.com/section/world”,”//h2[contains(.,’China’)]”) will just scrape the h2 elements that include the word “China”.
For instance, we scraped for all headlines containing the word “China” in The New York Times’ world section using the following:
- Inspect the webpage to identify the class (i.e., text type) you’re looking for (“p” for paragraph, “h1” for a header, “h2” for subheadings…)
- Insert the word you are looking for in the formula (replace “country”)
- Have the data automatically loaded to your Google Sheets once a day!
5. Free apps (if you’re terrified of code)
If all of this hasn’t convinced you to learn a bit of HTML, you might still try using browser extensions or free apps. They give you less control over how the data is collected and formatted, but will save you the trouble of writing code lines and spreadsheet formulas.
Sunne recommended the following:
- Parsehub: A desktop application capable of scraping data from any website, including interactive content (and will extract data from pages coded using JavaScript or AJAX). It doesn’t require coding knowledge due to its user-friendly interface and lets you upload data to Excel and JSON as well as import to Google Sheets and the Tableau analytics platform.
- Outwit: In addition to their web scraper, Outwit offers services to build a custom scraper, automate scraping, and even extract the data for you.
- WebScraper: An easy point-and-click solution for those who prefer not to deal with code, WebScraper is able to build “site maps” based on the website’s structure and data points you want to extract.
Additional Resources
- GIJN Resource Center’s Scraping Data
- GIJN’s Data Journalism Guide: Tools for Scraping, Cleaning, and Prepping Data
- Web Scraping: A Journalist’s Guide

Smaranda Tolosano manages translations and partnerships for GIJN. She previously reported for the Thomson Reuters Foundation in Morocco, covering the government’s use of spyware to target regime dissidents and the emergence of feminist movements on social media.

Step-By-Step Guide for Journalists on the Basics of Google Sheets

Tipsheet for Using Ocean Data in Your Investigations

GIJC23 – The Future of Data Journalism: New Analytical Tools, Data Visualization, and AI

GIJC23 – The Basics of Using Google Sheets

Aleph Pro Tutorial: How to Get the Most from OCCRP’s Updated Investigative Data Platform
The Power of ‘Positive Deviant’ Data Investigations: How Good Outliers Can Expose Systemic Misconduct or Policy Failure

5 Tips for Slashing FOIA Costs (Including How One Reporter Lowered a Records Request Fee from $2,800 to Just $29)

From NICAR25, Four Free Cutting Edge and Time-Saving Investigative Data Tools

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
Databases Reporting Tools & Tips
Aleph Pro Tutorial: How to Get the Most from OCCRP’s Updated Investigative Data Platform
A step-by-step guide to using Aleph Pro, the latest iteration of OCCRP’s data platform, offering access to a massive trove of property and financial documents, as well as other records.
Reporting Tools & Tips
The Power of ‘Positive Deviant’ Data Investigations: How Good Outliers Can Expose Systemic Misconduct or Policy Failure
One often overlooked approach for accountability reporting involves side-by-side comparisons between successful and failing institutions with near-identical resources.
Reporting Tools & Tips
5 Tips for Slashing FOIA Costs (Including How One Reporter Lowered a Records Request Fee from $2,800 to Just $29)
With a little research and negotiation, reporters can slash the cost of obtaining records bundles and speed up the government’s response in the process.
Data Journalism Reporting Tools & Tips
From NICAR25, Four Free Cutting Edge and Time-Saving Investigative Data Tools
GIJN shares some of the no-cost, easy-to-use data tools that NICAR25 conference panelists described as surprisingly useful but unknown by investigative reporters.