
4 More Essential Tips for Using the Wayback Machine
Read this article in




ProPublica’s Craig Silverman explains how to bulk archive pages, compare changes, and see when elements of a page were archived.
The previous edition of Digital Investigations offered advice for getting the most out of the Wayback Machine. Now I’m back with even more tips, thanks to an interview with Mark Graham, director of the Wayback Machine.
He pointed to a few features I forgot to mention along with one I wasn’t aware of. We also talked about the challenge of archiving social media content.
The Wayback Machine is run by the Internet Archive, a 27 year-old nonprofit dedicated to providing universal access to all knowledge. “We are a digital library,” Graham said.
As a library, it has patrons instead of users, he said. Let’s look at some useful features for journalist and researcher patrons.
1. View and Compare Changes
The Changes feature lets you compare different versions of the same archived page and see the differences.
“Maybe a journalist is writing a story showing how a content material on a webpage has changed over time,” Graham said. “In that case, they would need to know about the Changes feature of the Wayback Machine, where you can compare the material on one URL on two different points of time.”
The Changes feature is accessible from the top menu of any archived page you’re browsing in the Wayback Machine:

Image: Screenshot
You can also load it directly with this URL format: https://web.archive.org/web/changes/https://www.nytco.com/journalism/
Place the URL you want to compare after https://web.archive.org/web/changes/ and it will bring up a page that shows year by year archive grids:

Image: Screenshot, Wayback Machine
Each shaded square corresponds to a page capture, and the color legend indicates which days may have significant changes. Select two captures and then click the “Compare” button at the top of the page. You get a side-by-side view of the captures.
I chose a page from early March 2023 (left) and one from early January 2022 (right). The comparison showed that the New York Times corporate page about its journalism had updated the footer menu options and text:

Image: Screenshot, Wayback Machine
2. Use ‘About this Capture’ to Verify Page Elements
The basic description of the Wayback Machine is that captures and stores archives of webpages. The reality is a little more nuanced.
“The web is messy, the web is constantly changing,” Graham said. “And when I say constantly changing, it can also be dynamic.”
I asked him how confident we can be that the archive shows exactly what was on a page at the date and time listed in the Wayback Machine. The short answer is that, yes, you can have confidence. But elements of an archived page can be drawn from different archived material, each with its own timestamp. This is where the nuance comes in.
The Wayback Machine has a feature that lets you view the timestamps of different elements on a page. You access it by clicking on the “About this capture” button in the upper right-hand corner of a page capture:

Image: Screenshot
Using https://www.nytco.com/journalism/ as an example, here’s what we get:

Image: Screenshot, Wayback Machine
Even though the page was archived on Oct. 20, 2021, the capture pulls some elements from more recent archives. Most of the page elements listed above are images that make up the page template. A couple of the files are JavaScript and CSS. Graham explained that the Wayback Machine pulls from different images, JavaScript, and CSS files to make the page when you view it.
“When we replay a page, we actually take and gather together each of those page requisites represented by its own URL with its own archive, and we put them together,” he said. “One of the challenges is that each of those objects could be archived at a different time in date.”
For example, the main photo at the top of the page (“17XP-PULITZERS2-superJumbo-article.jpg”) was pulled from a a capture taken 8 days prior to me loading the archive. If that photo/file is important to your investigation, you’d want to check its archive page to see if it’s changed over time, or to look for a capture closer to the target date. But as long as that file has remained the same over time, you’re OK.
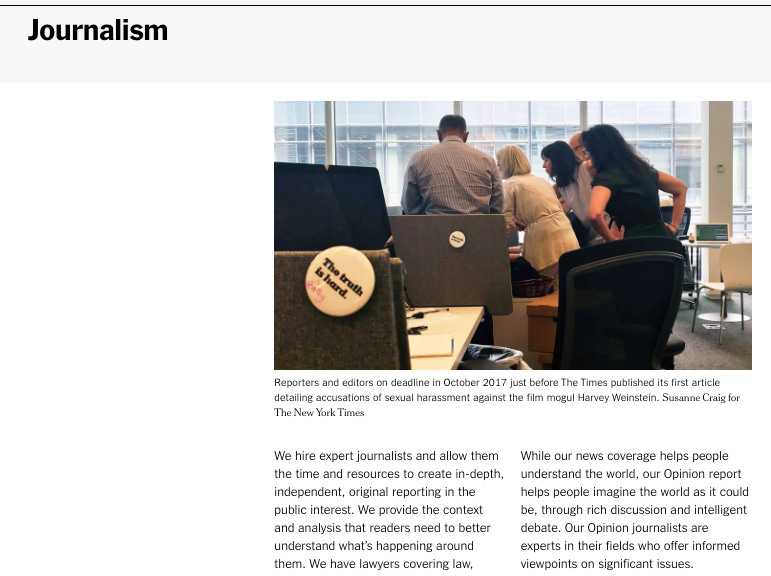
Image: Screenshot, New York Times corporate website
As a general but not absolute rule, the body text on a typical webpage is not pulled from a separate page or file. It’s therefore less likely to be affected by this dynamic. But the safest option is to check “About this capture” and make sure that the text, images, or other element on the page capture you’re citing are consistent with the date you’re interested in.
3. Bulk Archive URLs Using Google Sheets

Image: Screenshot, Internet Archive
Once that’s completed, you’ll see this screen. Click on “Archive URLs.”

Image: Screenshot, Internet Archive
Now you can insert a link to your Google Sheet containing URLs you want to archive.

Image: Screenshot, Internet Archive
Since you connected to your Google and archive.org accounts, all of the captures will be stored in your archive.org account for easy retrieval.
“That feature came about because my wife once asked me, ‘Mark, how can I easily archive a bunch of URLs?’” he said.
Graham worked with engineers at the Internet Archive to make it happen.
4. Email Your Feedback and Requests
“Many, many, many features of the Wayback Machine exists today because a patron asked for them, a patron asked a question, or made a suggestion or recommendation,” Graham said. “We really appreciate requests and questions.”
He encouraged people to email info@archive.org.
“We receive hundreds of emails a day and we have a team of people that review them and respond to them,” Graham said. “I personally respond to the ones about the Wayback Machine that can’t be handled by the first level of response.”
He especially encouraged journalists to reach out if they have questions or requests.
Bonus Info: Archiving Social Media
Power users of the Wayback Machine know it ranges from difficult to impossible to archive social media content there. This has less to do with the its functionality and limitations, and more to do with how companies like Meta try to thwart scraping.
Here’s what Graham said about why it’s hard to archive content from social media:
Just as some other websites are more challenging to archive than other websites, in particular Facebook and Instagram represent challenges. They take active measures to try to prevent various kinds of automation, including scraping. If you go to the Facebook site, for example, there’s a section about web scraping where they talk about the staffing they have dedicated to efforts to prevent web scraping and web archiving.
We work respectfully with the web. This isn’t our material. As a library we work to make material generally available. So in the case of Facebook and Instagram, we do try. And we we think it’s completely appropriate for us to archive publicly accessible information. So this would be say, for example, the public Facebook pages of the communications departments of the country of Ukraine or China.
One piece of encouraging news is Graham said the Wayback Machine is “actively working with several media organizations” to try and improve social media archiving. Hopefully things improve soon.
This post was originally published in Craig Silverman’s Digital Investigations Substack newsletter and is reprinted here with permission.
Additional Resources
My Favorite Tools with BuzzFeed’s Craig Silverman
5 Online Search Tools to Make Journalists’ Lives Easier
Tips for Using the Internet Archive’s Wayback Machine in Your Next Investigation
 Craig Silverman is a national reporter for ProPublica, covering voting, platforms, disinformation, and online manipulation. He was previously media editor of BuzzFeed News, where he pioneered coverage of digital disinformation.
Craig Silverman is a national reporter for ProPublica, covering voting, platforms, disinformation, and online manipulation. He was previously media editor of BuzzFeed News, where he pioneered coverage of digital disinformation.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next

Investigative Techniques Reporting Tools & Tips
How to Verify Bystander Video
From the Minneapolis shootings to the Guthrie kidnapping, visual investigation skills are now mandatory. Here’s how to do it.

Investigative Techniques
Updated Test of 24 LLMs for Geolocation
Bellingcat ran a series of geolocation challenges using two dozen popular AI platforms, with varying results.

Reporting Tools & Tips
This Reporter Exposed the Civilian Toll of US Airstrikes. Her Warning: Be Ready for a More Hostile World
Azmat Khan is known for her rigorous reporting on civilian casualties from US airstrikes, and for exposing systemic failures in military and government accountability.

Reporting Tools & Tips
Tips for Turning Unreadable Text Into Evidence
Whether it’s extracting names from footage, decoding social media posts, or reading distorted text in documents, Henk van Ess explains how free digital tools can take on these investigative tasks.