Image: Shutterstock
डेटा जर्नलिज़्म: पत्रकारों के लिए ‘मानक विचलन’ से सबंधित 4 जरूरी बातें
इस लेख को पढ़ें





इमेज: शटरस्टॉक
डेटा पत्रकारों को ‘अकादमिक शोध’ से महत्वपूर्ण खबरें मिलती हैं। ऐसे शोध दस्तावेज में ‘मानक विचलन’ शब्द का अक्सर उपयोग होता है। पत्रकारों को इसका अर्थ अच्छी तरह समझना चाहिए। तभी आप अपने पाठकों को इसके बारे में बेहतर जानकारी दे पाएंगे। इस आलेख में ‘मानक विचलन’ शब्द के बारे में विस्तार से बताया गया है। ‘मानक विचलन’ के संबंध में चार प्रमुख चीजें हैं, जिन्हें आपको जानना आवश्यक है।
1. ‘मानक विचलन’ (Standard Deviation) ऐसी संख्या है, जो बताती है कि डेटा में कितनी भिन्नता है।
संख्यात्मक या मात्रात्मक डेटा में इसका प्रयोग होता है। जैसे, जन्म-दर, तापमान की गणना, या छात्रों की परीक्षा के अंकों का विश्लेषण। ऐसे मामलों में शोधकर्ता आमतौर पर डेटा के ‘मानक विचलन’ की गणना करते हैं। इसमें बताते हैं कि डेटा कितना करीब या दूर है। अगर यह ‘उच्च मानक विचलन’ हो, तो इसका मतलब है कि डेटा अधिक फैला हुआ है। अगर ‘मानक विचलन’ निम्न हो, तो डेटा का औसत मूल्य उस डेटा क्लस्टर से ज्यादा करीब होगा।
‘ओहियो स्टेट यूनिवर्सिटी’ में सांख्यिकी विषय की प्रोफेसर डेबोरा जे. रुम्सी अपनी पुस्तक ‘स्टैटिस्टिक्स फॉर डमीज़’ में लिखती हैं – “मानक विचलन से हमें महत्वपूर्ण संदर्भ मिलता है। इसके बिना, हमें किसी डेटा का केवल एक हिस्सा मिल सकता है। सांख्यिकीविद किसी ऐसे व्यक्ति की कहानी सुनाना पसंद करते हैं, जिसका एक पैर बर्फ के पानी वाली बाल्टी में हो जबकि दूसरा पांव किसी उबलते पानी वाली बाल्टी में हो। वह व्यक्ति ऐसा कह सकता है कि औसतन उसे ठंडे और गर्म दोनों तरह के पानी के एहसास से बहुत अच्छा लगा! लेकिन उसके दोनों पैर के अलग-अलग दो तापमानों के बीच काफी फर्क होगा।”

प्रोफेसर डेबोरा जे. रुम्सी ने कुछ और दिलचस्प उदाहरण दिए। अपनी पुस्तक में वह लिखती हैं- “अगर आपको किसी क्षेत्र में मकानों की औसत कीमत बताई जाए, तब भी आपको उस खास मकान की कीमत का सही पता नहीं चल पाएगा, जो आपको पसंद है। यानी वह औसत मूल्य से कितना सस्ता या कितना महंगा है। इसी तरह, किसी कंपनी में औसत वेतन से कोई अंदाज लगाना मुश्किल होगा, यदि उसके न्यूनतम और अधिकतम वेतन के बीच का फासला बहुत अधिक हो।”
2. भविष्यवाणी करने, प्रवृत्तियों की जांच और शोध प्रश्न का उत्तर देने में ‘मानक विचलन‘ का उपयोग।
डेटासेट का ‘मानक विचलन‘ कई अकादमिक अध्ययनों में सीमित भूमिका निभाता है। वैज्ञानिक केवल उस ‘मानक विचलन’ के मान की तालिका या सूची बना सकते हैं, या अपने लेख के मुख्य भाग में उनका उल्लेख कर सकते हैं।
लेकिन कई बार शोधकर्ता अपने अध्ययन के लिए केंद्रीय प्रश्नों का उत्तर देने में मदद के लिए माप पर काफी भरोसा करते हैं। जैसे:
- मौसम का अनुमान, मतदाता व्यवहार, टैक्स राजस्व, स्वास्थ्य देखभाल सामग्री का उपयोग इत्यादि मामलों में एकत्र किए गए डेटा के ‘मानक विचलन’ के आधार पर भविष्यवाणियां कर सकते हैं।
- इक्विटी मार्केट के शोधकर्ता आमतौर पर शेयर बाजार की अस्थिरता को मापने के लिए स्टॉक की कीमतों के ‘मानक विचलन’ का उपयोग करते हैं। इसमें ‘उच्च मानक विचलन’ का मतलब है कि शेयर मार्केट में उच्च अस्थिरता का संकेत है।
- छात्रों की परीक्षा के अंकों की जांच करने वाले शोधकर्ता ‘मानक विचलन’ का उपयोग करके बता सकते हैं कि अधिकांश छात्रों को औसत या उसके करीब अंक मिले या इसमें काफी भिन्नता है। इसके जरिए उन छात्रों के अनुपात का पता लगा सकते हैं जिन्हें अधिक सहायता की आवश्यकता है।
‘मानक विचलन’ की गणना कैसे करें? इसका संक्षिप्त विवरण यहां दिया गया है।
3. कुछ वैज्ञानिक ‘इंच’ या ‘पाउंड’ जैसी किसी माप इकाई के बजाय ‘मानक विचलन’ के रूप में अपने निष्कर्ष प्रस्तुत करते हैं.
जब डेटासेट में विभिन्न इकाइयों के साथ डेटा बिंदु होते हैं, तो वैज्ञानिकों को अक्सर तुलना करने और संबंधों की तलाश करने से पहले डेटा का मानकीकरण करने की आवश्यकता होती है। जैसे, संतरे के रस की खपत को ‘औंस’ या ‘ग्राम’ में मापा गया हो। इसके साथ ‘फ्लू टीकाकरण’ की दर के बीच संबंधों की जांच करना हो। प्रति एक लाख नागरिकों में हर महीने कितने टीके लगाए गए।
डेटा के मानकीकरण की प्रक्रिया में प्रत्येक संख्यात्मक डेटा बिंदु को डेटासेट के ‘मानक विचलन’ से विभाजित किया जाता है। ऐसा करने से माप की इकाइयों में परिवर्तन होता है। सामान्य इकाइयों जैसे औंस, इंच, पाउंड या किलोग्राम का उपयोग करके निष्कर्ष बताने के बजाय इन्हें ‘मानक विचलन’ के रूप में रिपोर्ट करना चाहिए।
हाइपोथेटिक या परिकल्पना के रूप में देखें। संतरे के रस की खपत और फ्लू टीकाकरण दरों पर शोध करने वाले वैज्ञानिक यह निष्कर्ष निकाल सकते हैं कि संतरे के रस की खपत में एक ‘मानक विचलन’ की वृद्धि होने पर टीकाकरण दरों में एक ‘मानक विचलन’ की कमी होगी।
डेटासेट का मानकीकरण करने से शोधकर्ताओं का काम आसान होता है। ‘हार्वर्ड मेडिकल स्कूल’ में न्यूरोलॉजी के एसोसिएट प्रोफेसर ब्रायन हीली के अनुसार सामान्य पाठकों को शोध के परिणाम समझने में कठिनाई हो सकती है। इसलिए पत्रकारों को ऐसे शोध पत्रों को बारीकी से पढ़ने के बाद आम पाठकों को समझाने लायक भाषा में लिखना चाहिए।
“जब तक आप वास्तव में कागज में बारीकी से नहीं देखते हैं, आपको पता नहीं चलेगा कि एक ‘मानक विचलन‘ का क्या अर्थ है।” ब्रायन हीली कहते हैं। वह ब्रिघम स्थित ‘पार्टनर्स मल्टीपल स्केलेरोसिस सेंटर’ और बोस्टन स्थित महिला अस्पताल में प्रमुख बायो स्टैटिस्टियन भी हैं।
वे कहते हैं- “किसी शोध के परिणाम जिन इकाइयों में दिखाए जा रहे हैं, उन इकाइयों को अच्छी तरह समझें। यदि रिपोर्ट में कोई संख्या दी गई है, तो आपको यह समझना होगा कि उस संख्या की व्याख्या कैसे करें। उन इकाइयों को जाने बिना आप यह नहीं समझ सकते कि संख्या की व्याख्या कैसे करें।”
4. ‘मानक विचलन’ के जरिए यह पुष्टि कर सकते हैं कि कोई डेटा बिंदु ‘बाहरी’ है अथवा नहीं।
बाहरी (आउटलाइअर) परिणाम ऐसे अत्यधिक उच्च या निम्न मान हैं जो सांख्यिकीय विश्लेषणों और विषम परिणामों को जटिल बना सकते हैं। कई शोधकर्ता किसी त्रुटि के कारण होने वाले आउटलाइअर्स को बदल या हटा देते हैं। जैसे, डेटा एकत्र करने या दर्ज करने में त्रुटि।
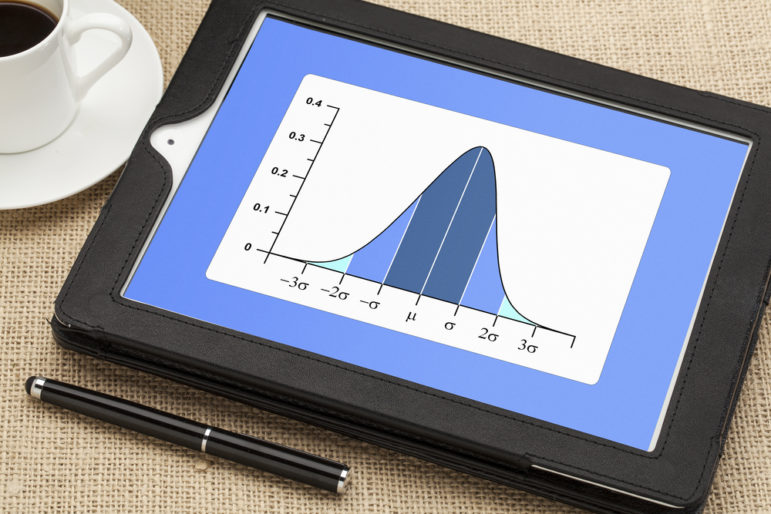
किसी डेटासेट में सभी डेटा के ग्राफ़ को देखने पर कुछ डेटा बिंदु बाहरी या आउटलाइअर प्रतीत होते हैं क्योंकि वे दूसरों से बहुत भिन्न होते हैं। डेटासेट का ‘मानक विचलन’ इस बात को ध्यान में रखता है कि व्यक्तिगत मान किसी औसत से कितनी दूर है। वैज्ञानिक अक्सर इसका उपयोग यह पता लगाने के लिए करते हैं कि क्या असामान्य डेटा बिंदु एक ‘बाहरी’ है। यह तरीका उन डेटासेट में अच्छी तरह काम करता है, जो एक घंटी के आकार के वक्र के पैटर्न का पालन करते हैं। इसमें अधिकांश डेटा का घंटी के केंद्र के पास अभिसरण होता है, जहां औसत मान स्थित होता है।
उस डेटासेट के लिए ‘मानक विचलन’ की गणना करने के बाद, आउटलाइअर्स को खोजना आसान है। घंटी के आकार के वक्र का अनुसरण करने वाले डेटा के लिए एक सामान्य नियम यह है कि लगभग 99.7 प्रतिशत डेटा औसत के तीन ‘मानक विचलन’ के भीतर होगा। इस सीमा से बाहर के डेटा को आमतौर पर आउटलाइअर माना जाता है।
किसी डेटासेट का ‘मानक विचलन’ आउटलाइअर्स द्वारा प्रभावित होता है। लेकिन पत्रकारों को यह नहीं समझना चाहिए कि कोई बड़ा ‘मानक विचलन’ किसी डेटा की गुणवत्ता की समस्याओं को इंगित करता है। ‘स्टैटिस्टिक्स फॉर डमीज़’ में प्रोफेसर डेबोरा जे. रुम्सी लिखती हैं- “एक बड़ा ‘मानक विचलन’ जरूरी नहीं कि एक बुरी चीज हो। यह सिर्फ अध्ययन किए जा रहे उस समूह में बड़ी मात्रा में भिन्नता को दर्शाता है।”
इस पोस्ट का मूल रूप से प्रकाशन ‘द जर्नलिस्ट्स रिसोर्स’ द्वारा किया गया। इसे ‘क्रिएटिव कॉमन्स लाइसेंस’ के तहत यहां पुनर्मुद्रित किया गया है। ‘द जर्नलिस्ट्स रिसोर्स’ इस टिपशीट को बनाने में मदद के लिए यूनिवर्सिटी ऑफ साउथ फ्लोरिडा के कॉलेज ऑफ पब्लिक हेल्थ में स्वास्थ्य अर्थशास्त्र के प्रोफेसर ट्रॉय क्वास्ट और हार्वर्ड मेडिकल स्कूल में न्यूरोलॉजी के एसोसिएट प्रोफेसर ब्रायन हीली का आभारी है।
अतिरिक्त संसाधन
5 Things Journalists Need to Know About Statistical Significance
New Data Tools and Tips for Investigating Climate Change
GIJN Resource Center: Data Journalism
 डेनिस-मैरी ऑर्डवे ‘द जर्नलिस्ट्स रिसोर्स’ की प्रबंध संपादक हैं। उन्होंने यूएसए और मध्य अमेरिका में समाचार पत्रों और रेडियो स्टेशनों के लिए भी काम किया है। उनका लेखन यूएसए टुडे, द न्यूयॉर्क टाइम्स और द वाशिंगटन पोस्ट में प्रकाशित हुआ है। वह 2014-15 में ‘हार्वर्ड नीमन फैलो भी रह चुकी हैं।
डेनिस-मैरी ऑर्डवे ‘द जर्नलिस्ट्स रिसोर्स’ की प्रबंध संपादक हैं। उन्होंने यूएसए और मध्य अमेरिका में समाचार पत्रों और रेडियो स्टेशनों के लिए भी काम किया है। उनका लेखन यूएसए टुडे, द न्यूयॉर्क टाइम्स और द वाशिंगटन पोस्ट में प्रकाशित हुआ है। वह 2014-15 में ‘हार्वर्ड नीमन फैलो भी रह चुकी हैं।

यह कार्य लाइसेंस के अन्तर्गत है क्रिएटिव कॉमन्स एट्रिब्यूशन-नोडेरिवेटिव्स 4.0 अंतर्राष्ट्रीय लाइसेंस
क्रिएटिव कॉमन्स लाइसेंस के तहत हमारे लेखों को निःशुल्क, ऑनलाइन या प्रिंट माध्यम में पुनः प्रकाशित किया जा सकता है।
आलेख पुनर्प्रकाशित करें
यह कार्य लाइसेंस के अन्तर्गत है क्रिएटिव कॉमन्स एट्रिब्यूशन-नोडेरिवेटिव्स 4.0 अंतर्राष्ट्रीय लाइसेंस
अगला पढ़ें

डेटा पत्रकारिता रिपोर्टिंग टूल्स और टिप्स
पत्रकारों को ‘सांख्यिकीय महत्व’ पर ये 5 बातें अवश्य जानना चाहिए
अकादमिक पत्रिकाएं अक्सर ‘सांख्यिकीय महत्व’ वाले परिणामों के साथ अनुसंधान को प्राथमिकता देती हैं। इसलिए शोधकर्ता अक्सर उस दिशा में अपने प्रयास केंद्रित करते हैं। कई अध्ययनों से पता चलता है कि सांख्यिकीय रूप से महत्वपूर्ण निष्कर्षों वाले रिसर्च पेपर्स के प्रकाशित करने की अधिक संभावना रहती है।

यौन अपराधियों को बचाने वाले सिस्टम पर कैसे रिपोर्टिंग करें
अपनी जांच के लिए सबसे उपयोगी जानकारी कहां मिलेगी? इसके लिए आपको यह पता लगाना होगा कि कहां खोजना है। थॉम्पसन कहते हैं- “परिकल्पना के बारे में सोचें। जानकारी कहां से एकत्र की जाएगी? यह कहां होगी?“
जैसे, यौन हिंसा के अपराधों से जुड़ी जानकारी कहां मिलेगी? इसके लिए मेडिकल रिकॉर्ड, पुलिस रिपोर्ट, मानसिक स्वास्थ्य सहायता डेटा से जानकारी मिल सकती है। सोशल मीडिया में पीड़ितों ने अपनी कहानी सुनाई होगी। हम जानकारी के ऐसे स्रोतों का चयन करें, जिन्हें बुद्धिमानी से जुटाया गया है।

रिपोर्टिंग टूल्स और टिप्स सुरक्षा और बचाव
जासूसी का शिकार होने से कैसे बचें पत्रकार?
हमारे समूह के दो पत्रकारों के एक जोड़े के साथ भी दिलचस्प मामला हुआ। लंबे दुपट्टे वाला एक युवक उनका पीछा कर रहा था। जबकि ऐसा लग रहा था वह किसी काम से बैंक जा रहा है। एक और बात यह है कि यह एक बूढ़ा, गंदा स्पॉटर था जिसे किसी ब्लॉकबस्टर फिल्म में एमआई6 एजेंट के रूप में नहीं लिया गया होगा।

रिपोर्टिंग टूल्स और टिप्स
वेबसाइट सामग्री की जांच में उपयोगी है ‘इन्फॉरमेशन लॉन्ड्रोमैट’
वेबसाइट विश्लेषण के लिए Information Laundromat सबसे नया, दिलचस्प और मुफ्त टूल है। जॉर्ज मार्शल फंड के अलायंस फॉर सिक्योरिंग डेमोक्रेसी – (एएसडी) ने यह टूल विकसित किया है। यह सामग्री और मेटाडेटा का विश्लेषण कर सकता है।