Browser Add-ons (Part 2): Traveling Back in Time
 As we discussed in part one, you can customise your web browser with ‘add-ons’ and get amazing extra functionality to support your internet research. Chrome and Firefox have the widest variety of add-ons, but some are also available for other browsers.
As we discussed in part one, you can customise your web browser with ‘add-ons’ and get amazing extra functionality to support your internet research. Chrome and Firefox have the widest variety of add-ons, but some are also available for other browsers.
I previously looked at add-ons that help users grab videos and images of web pages, trace the hosting of web servers and download YouTube videos. Here are a few more essentials:
Reading image metadata
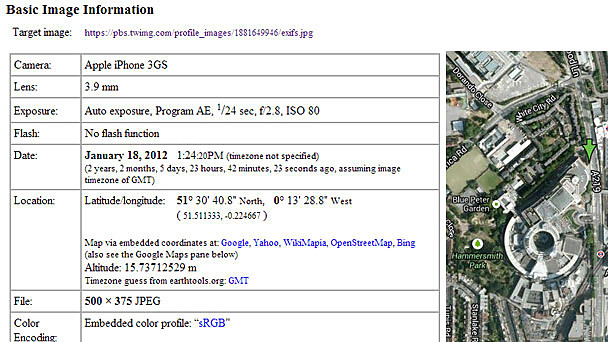
Digital photos often have metadata – known in the trade as ‘Exif’. This information contains treasure for investigators. You can see when a photo was taken, which camera was used, where it was taken (down to a few square meters), and even how far above sea level the photographer was at the time.
A lot of this is contingent on the photographer having their phone camera’s ‘location services’ turned on. On some cameras the accuracy of time and date information also depends on the camera being programmed properly at the start (others set themselves) and it’s also possible (though difficult) to fake this information. Some sites like Facebook strip out the Exif data. But there is often some useful information that will aid your investigation or help authenticate a source.
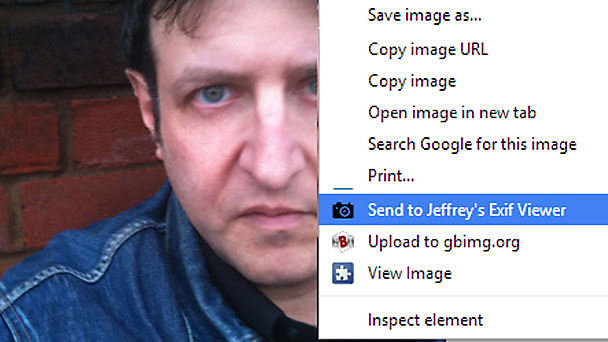
Quite a few add-ons and websites will read the Exif data, but Jeffrey’s is one of my favourites. Installing this (Chrome) add-on will allow you to right-click on an image and send it to Jeffrey’s for analysis. Other Exif readers are available for Firefox.
Reverse image searching
Another add-on will help you to search for an image on Google. It can help to identify anonymous profile pics, buildings, even logos. Simply install the Search by image for Google add-on for Firefox (or its nearest equivalent for Chrome), then right-click on the photo you are interested in and choose ‘search by image on Google’ from the menu that pops up.
If you can’t find the photo on Google, try using Tineye. This produces add-ons for all the main browsers.
Look up domain names
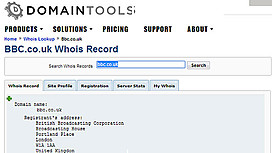 It is often essential to see who is behind a website. Checking domain name registration with a ‘whois’ search is one way to achieve this. Sites like DomainTools, Who.is and many others will allow you to find these details. You can copy a web address, visit a Whois search site, paste in the url and wait for the search results… or you can install a button that will automate the procedure.
It is often essential to see who is behind a website. Checking domain name registration with a ‘whois’ search is one way to achieve this. Sites like DomainTools, Who.is and many others will allow you to find these details. You can copy a web address, visit a Whois search site, paste in the url and wait for the search results… or you can install a button that will automate the procedure.
Whois add-ons are available for Chrome, Firefox and most other browsers.
Find information from the past
Investigators often need to find information that has been deleted from the web. You might need the former postal address of an organisation that is now using a PO Box. You might need to check that a person was employed by a company back in 2008. Maybe you need to find a photo that has disappeared from a web page. Don’t despair – there are a few ways to time travel on the web.
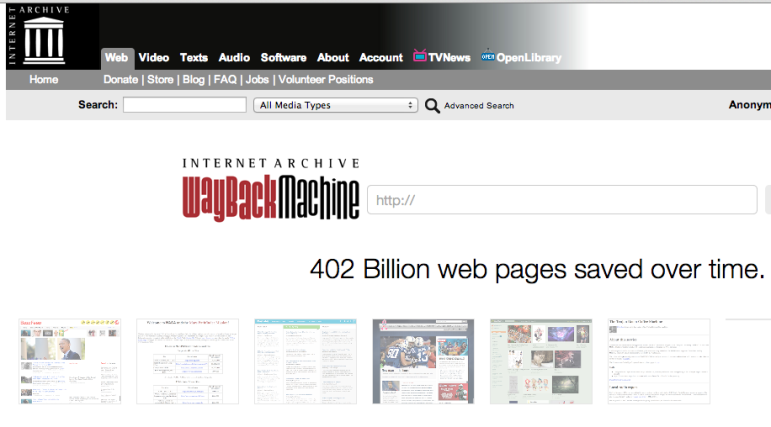
 Search engines keep recent copies of web pages in their cache. If you suspect a site has recently changed you can go back a few days and see what it used to look like. If you need information from further back in time, it could be worth your while looking for the site on the Wayback Machine. This stores copies of websites going back to 1996.
Search engines keep recent copies of web pages in their cache. If you suspect a site has recently changed you can go back a few days and see what it used to look like. If you need information from further back in time, it could be worth your while looking for the site on the Wayback Machine. This stores copies of websites going back to 1996.
Add-ons will take you back in time with the click of an extra browser button. I am currently using Resurrect Pages on Firefox and Web Cache on Chrome, but, as with all of these add-ons, exciting alternatives are available – many for Opera, Safari and Internet Explorer.
Here’s part one of this Paul Myers blog on customising your browser.

Paul Myers is the BBC College of Journalism‘s Internet Research Specialist. His role involves helping TV & Radio programs conduct investigations that involve trickier aspects of Internet research. He also hosts regular training courses inside and outside the BBC. Blending his previous career as a computer programmer with journalism, Paul pioneered many online research techniques now widely used. This post originally appeared on the blog of the College of Journalism at the BBC Academy. Cross-posted with permission.

Reporter’s Guide to Investigating Cryptocurrency

Tipsheet on Partnering with Civil Society Organizations and Non-Governmental Organizations

AI Accountability Reporting Guide
Guide to Mapping Analysis Using QGIS

First Look: IJ WEEK World-Class Speakers and Cutting-Edge Sessions
Do You Have ‘the OSINT Mindset’?: Try Our Quiz for Those Who Like ‘a Little Light Online Sleuthing’

Building an Engaged Community through Collaboration and In-Depth Investigations, All While Maintaining a Sense of Humor

Aleph Pro Tutorial: How to Get the Most from OCCRP’s Updated Investigative Data Platform

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
IJ WEEK
First Look: IJ WEEK World-Class Speakers and Cutting-Edge Sessions
With just 12 weeks left until IJ WEEK, GIJN is offering a sneak preview of some of the event’s more than 100 speakers as well as the expert panels and networking sessions.
Investigative Techniques Reporting Tools & Tips Teaching & Training
Do You Have ‘the OSINT Mindset’?: Try Our Quiz for Those Who Like ‘a Little Light Online Sleuthing’
The most important thing to learn if you wish to integrate elements of OSINT into your investigative practice is the overall mindset behind the approach.
Member Profiles
Building an Engaged Community through Collaboration and In-Depth Investigations, All While Maintaining a Sense of Humor
This small Lithuanian outlet Siena punches above its weight by publishing agenda-setting stories — but the founders say they also never want to take themselves too seriously.
Databases Reporting Tools & Tips
Aleph Pro Tutorial: How to Get the Most from OCCRP’s Updated Investigative Data Platform
A step-by-step guide to using Aleph Pro, the latest iteration of OCCRP’s data platform, offering access to a massive trove of property and financial documents, as well as other records.