
Editörün notu: Bu kılavuz , Pulitzer Merkezi Yapay Zeka Sorumluluk Grubu ve GIJN’nin ortak çalışmasıdır. Karen Hao, Lais Martins ve Pablo Jimenez Arandia, bu makalede açıklanan materyallerin bir kısmının ortak yazarlarıdır.
Yapay zekâ (YZ), toplumun birçok alanında hayati bir güç haline geldi. Bu teknoloji, birçok ekonomide önemli bir rol oynuyor ve dünyadaki bilgi işçilerini etkiliyor. Bu pazardaki en etkili oyuncular, çoğunlukla ABD, Avrupa ve Çin’den olmak üzere, milyarlarca dolarlık yatırım çeken ve bu teknolojinin dünya çapındaki gelişiminde ve benimsenmesinde öncü rol üstlenmeye hazır olan bir avuç özel teknoloji devidir.
Ancak, tedarik zincirinden uygulamasına kadar yapay zekâ, tartışmalara yabancı değil. Yapay zekâ geliştirme için gerekli veri merkezleri inanılmaz miktarda su ve elektrik tüketiyor. Yapay zekâ için gerekli verileri etiketlemekle görevli çalışanlar düşük ücretlerle ve ruh sağlığı sorunlarıyla karşı karşıya kalıyor. Yapay zekâ teknolojilerinin kendilerinin de önyargılı olduğu ve kullanıldığında halüsinasyonlara yol açtığı gösterilmiştir.
Yapay zekâ alanı, araştırmacı gazetecilik için sayısız fırsat sunmakta. Bu kılavuz, gazetecilerin yapay zekânın ardındaki teknolojinin bazı inceliklerini anlamalarına ve onu analiz etmek için bir çerçeve sağlamalarına yardımcı olmayı amaçlamakta.
Yapay zeka nedir?
Birçok insan yapay zekâ fikriyle ilk kez ChatGPT aracılığıyla tanıştı. Bu nedenle, insanlar genellikle ChatGPT’yi yapay zekâ, yapay zekâyı ise ChatGPT olarak düşünür.
Ancak gerçekte durum çok daha karmaşık. Yapay zekâ, insan karar verme süreçlerini taklit etmek için makinelerin kullanılması sürecini tanımlar ve daha ziyade çok çeşitli teknolojileri kapsayan, oldukça farklı terimlerin bir araya getirilmesi olarak değerlendirilmelidir.
Bu terim 1950’lerde bilim insanları ve araştırmacılar tarafından ortaya atıldı ve o zamandan beri teknoloji kullanılarak insan zekasını yeniden yaratmanın birçok farklı yolu bulundu.
Günümüzde yapay zekanın en popüler ve yaygın olarak kullanılan yöntemlerinden biri derin öğrenme ve üretken yapay zeka gibi alt türleri de dahil olmak üzere makine öğrenimi ve tüm biçimleri.
Makine öğrenimi, sonuçlara dayalı tahminler veya kararlar vermeyi sağlayan kalıpları belirlemek için verileri analiz etme sürecidir. Bu analizler, işlenen veri hacmine bağlı olarak, basit istatistiklerden karmaşık sinir ağlarına kadar çeşitli matematiksel yöntemler kullanır. Bu eğitimin sonucu, yeni verileri alıp tahminlerde bulunabilen veya eski verilere dayanarak yeni bilgiler üretebilen bir bilgisayar programı veya yapay zeka modelidir. Birçok açıdan, makine öğrenimi sonuçları eski verilerin yeniden işlenmesi olarak düşünülebilir. Bir kullanım örneğinde, devlet kurumları, sosyal yardımdan yararlanma potansiyeli olan veya konut yardımı için başvuran kişiler arasında ihtiyaçları ve dolandırıcılık riskini değerlendirmek için basit makine öğrenimi modelleri kullanabilir.
Derin öğrenme, genellikle milyonlarca kayıt içeren daha büyük miktarda veri gerektiren ve bu verileri anlamlandırmak için sinir ağları gibi gelişmiş analitik yöntemler kullanan makine öğrenmesinin bir alt kümesidir. Sinir ağları, beynin yapısını taklit eden ve birbirine bağlı düğümlerden oluşan matematiksel yöntemlerdir. (Sinir ağları hakkında daha fazla bilgiyi burada bulabilirsiniz .) Bu tür makine öğrenmesi, genellikle büyük teknoloji şirketleri tarafından arama sorgularını tahmin etmek veya yayın hizmetlerinde öneri sistemleri için kullanılır.
Sırada ise daha da fazla veri gerektiren ve eğitim aşamasında modellerini oluşturmak için daha fazla enerji ve karmaşık matematiksel yöntemler kullanan, makine öğrenmesinin bir alt kümesi olan üretken yapay zeka var. Üretken yapay zeka, diğer birçok makine öğrenme yönteminden farklı olarak, yalnızca zaman çizelgesi önerileri veya tahminler üretmekle kalmaz, aynı zamanda metin veya görüntü biçiminde yeni içerik de oluşturur. Şu anda Büyük Dil Modelleri (LLM’ler), ChatGPT veya Gemini gibi sohbet botları ve Midjourney gibi metin komutlarına dayalı olarak görüntü üreten uygulamalar şeklinde karşılaştığımız teknolojilerdir.
Aşağıdaki diyagram, tüm makine öğrenimi seçeneklerini göstermektedir.
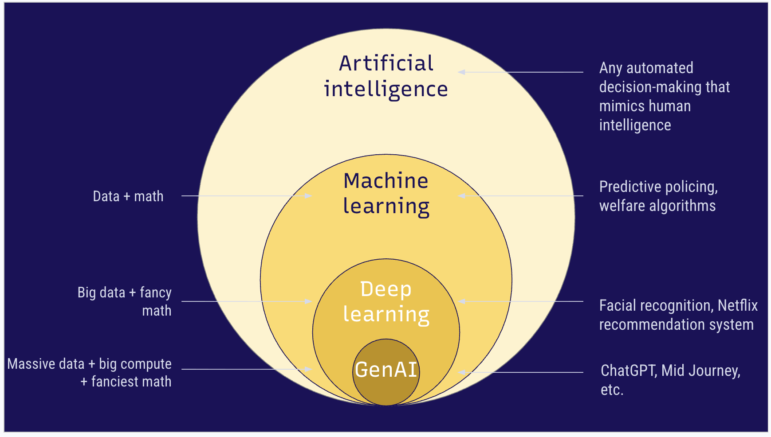
Yapay zekâ ve alt türleri, makine öğrenimi, derin öğrenme ve üretken yapay zekâ. Görsel: Pulitzer Merkezi
Makine öğreniminin temel prensiplerini anlamak, gazetecilerin bu konuda nasıl konuşacaklarını bulmalarına, teknoloji hakkında bilinçli sorular sormalarına ve haberlerinde yapay zeka gelişiminin çeşitli aşamalarını daha etkili bir şekilde açıklamalarına yardımcı olabilir.
Yapay Zekâ Hesap Verebilirliği Haberleri İçin Bir Çerçeve
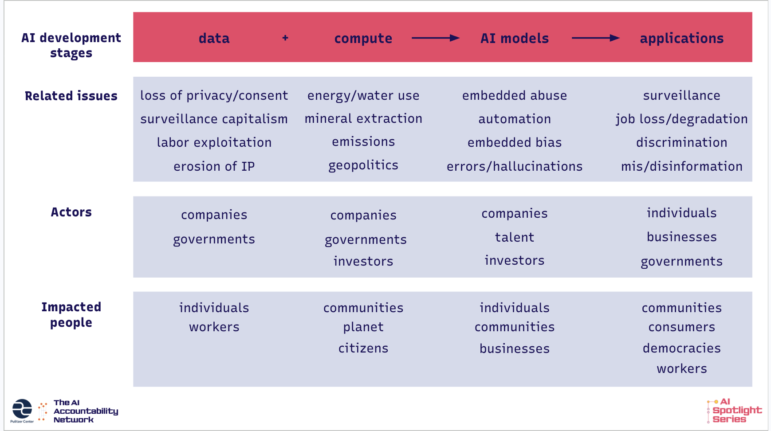
Kullanılan verilerin incelenmesi
En basit yapay zeka modelleri, eğitim için birkaç yüz veri noktası içeren veri kümelerini kullanabilirken, LLM gibi en karmaşık modeller genellikle büyük miktarda İnternet verisi üzerinde eğitilir. Eğitim verilerindeki materyal yelpazesi de aynı derecede geniş olabilir. Düzenli bir şekilde satır ve sütunlara ayrılmış yapılandırılmış tablo verilerinden veya sosyal medya platformlarından, haber sitelerinden ve çevrim içi forumlardan toplanan yapılandırılmamış metinlerden oluşabilir. Giderek artan bir şekilde, görüntüler ve videolar da içeriyor.
Veri bilimi aşamasına ilişkin raporların çoğu, endüstriyel ölçekte devasa veri kümeleri üzerinde eğitilmiş daha karmaşık sistemlere odaklanma eğiliminde. Bu makalelerin birçoğu, özellikle telif hakkıyla korunan materyallerin veya kişisel verilerin yapay zeka model eğitim süreçlerine nasıl girdiğine dair gizlilik ve fikri mülkiyet sorunlarını ele almakta. Örneğin, The Atlantic, Meta’nın üretken yapay zeka modeli Llama’yı eğitmek için binlerce korsan kitap kullandığı iddiasını inceliyor. Meta sözcüsü, şirkete karşı devam eden davayı gerekçe göstererek The Atlantic’in sorularını yanıtlamayı reddetti. New York Times’da yer alan bir makale ise, sigorta şirketlerinin sürücülerin riskini değerlendirmek için görünüşte zararsız uygulamalardan kişisel sürüş verilerini satın aldığını bildiriyor .
Ancak verilere bakmak, eğitim veri kümelerini kullanılabilir hale getiren insan emeğine de bakmayı gerektirir. Şirketler veri toplama ve eğitim süreçlerini son derece otomatik bir süreç olarak sunma eğilimindeyken, gerçek şu ki, eğitim kümeleri genellikle çoğunlukla Küresel Güney’de bulunan ve dış kaynak firmaları ve dijital işgücü platformları aracılığıyla çalışan büyük bir veri etiketleyici alt sınıfı tarafından temizlenir ve kategorize edilir. Bu çalışanlar, görüntü sınıflandırıcılarına beslenen kedi ve köpek resimlerini etiketler, sürücüsüz araçları eğitmek için kullanılan araç içi kamera görüntülerindeki nesnelerin etrafına kutular çizer veya LLM’lerin bunu yeniden üretmesini önlemek için nefret söylemi ve şiddet içerikli içerikleri belirler.
Dünyanın dört bir yanından gelen haberler, veri işçilerinin sömürüldüğünü, düşük ücret aldığını ve bazen travmatik içerikle karşılaşmaya zorlandığını gösteriyor. Araştırmacı Gazetecilik Bürosu’nun bu araştırması, dünyanın dört bir yanındaki düşük ücretli geçici işçilerin, Rus hükümeti tarafından kullanılan yüz tanıma sistemlerinin eğitimine farkında olmadan nasıl yardımcı olduklarını ortaya koyuyor . Africa Uncensored’dan bir başka haber ise, yüksek eğitimli çalışanların LLM sohbet robotlarını daha yüksek kaliteli yanıtlar üretmeleri için eğittiği, giderek büyüyen ‘yapay zeka eğitmeni’ sektörünü inceliyor .
Yapay Zekânın Hesaplama Altyapısını İncelemek
Eğitim veri setleri toplandıktan ve temizlendikten sonra, şirketler bunları yapay zeka modellerini eğitmek için kullanırlar. Basit yapay zeka modelleri bir tüketici dizüstü bilgisayarında saniyenin çok küçük bir bölümünde eğitilebilirken, OpenAI’nin ChatGPT’si gibi daha karmaşık modeller muazzam miktarda işlem gücü gerektirir. Genellikle “işlem gücü” olarak adlandırılan bu işlem gücü, tipik olarak devasa veri merkezlerinde bulunan özel bilgisayar çipleri tarafından sağlanır.
“Hesaplama” geliştirme aşamasına ilişkin haberler, modern yapay zeka gelişimini destekleyen yaygın ve hızla genişleyen fiziksel altyapının çevresel, sosyal ve ekonomik etkilerine odaklanma eğiliminde. 2024 yılında Yapay Zeka Odak Noktası Serisi’ni ilk geliştirdiğimizde, veri merkezleri nispeten haber konusuydu. O zamandan beri, Latin Amerika , Asya , Afrika ve Amerika Birleşik Devletleri’nden veri merkezlerinin tükettiği muazzam miktardaki enerji ve suyun yanı sıra bu rakamları gizlemeye yönelik kurumsal veya hükümet çabalarını gösteren çok sayıda haber yayınlandı. Örneğin Brezilya’da, Pulitzer ödüllü Laís Martins, bir TikTok veri merkezinin 2,2 milyon insanın tükettiği kadar elektrik tüketeceğini tespit etti şirket muhabire yanıt vermedi.
Veri merkezleri hakkındaki raporlama, çevresel etkilerin ötesine uzanır. Ayrıca veri merkezlerinin yerel toplulukları nasıl yeniden şekillendirdiğini , ekonomik büyüme vaatlerinin sıklıkla yerine getirilmemesini ve hem yerel hem de ulusal düzeyde veri merkezlerini çekmek ve inşa etmek için yapılan yoğun lobi faaliyetlerini de inceler. Laís, aşağıda bulabileceğiniz, yalnızca veri merkezi raporlamasına odaklanan, çerçevemizin uyarlanmış bir versiyonunu geliştirdi.
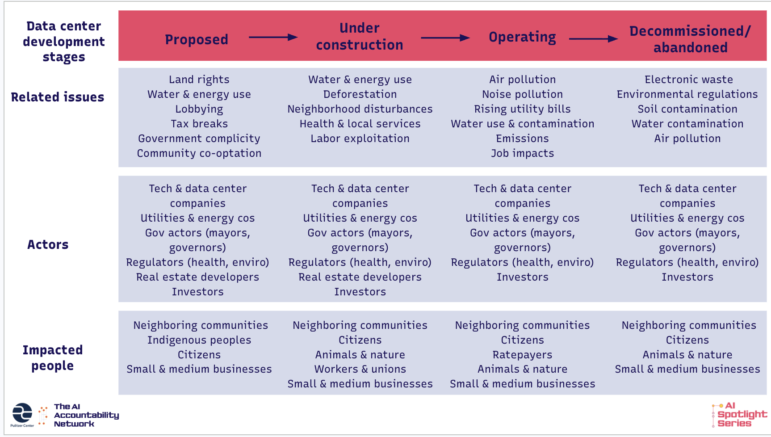
Modelleri Araştırmak
Eğitim verileri ve işlem gücünün birleşimi, tahminlerde bulunan, sınıflandırma yapan veya üretken yapay zeka durumunda tamamen yeni içerik oluşturan teknik bir ürün olan bir yapay zeka modeli üretir. Veri ve işlem gücü gibi, yapay zeka modelleri de karmaşıklık ve ölçek bakımından çeşitlilik gösterir; sağlık hizmetleri primlerini hesaplamak için kullanılan nispeten basit makine öğrenme sistemlerinden, gerçekçi görüntüler üretebilen gelişmiş derin öğrenme sistemlerine kadar uzanır.
Yapay zekâ modellerine odaklanan hikayeler genellikle önyargı, hatalar veya otomasyonun topluluklar ve kurumlar üzerindeki olumsuz etkileri gibi konulara odaklanır.
Bu araştırmalar, erişilebilir olduklarında, örneğin bir model tarafından kullanılan eğitim verileri veya parametreler gibi tasarım seçimlerini inceleyebilir. Örneğin, El Confidencial’ın bu araştırması, Katalonya cezaevi sisteminde gelecekte kimin suç işleyeceğini tahmin etmek için kullanılan bir yapay zeka sisteminin formülünü elde etti. Gazetecilere göre, model ayrımcı veya alakasız faktörlere dayanarak belirli gruplara sistematik olarak daha yüksek risk puanları atadı.
Bu tür bilgiler mevcut olmadığında, bunun yerine modelin çıktılarını analiz edebilirsiniz. Rest of World’den bir haber, popüler bir görüntü oluşturma aracı olan MidJourney AI tarafından üretilen 3.000 görüntüyü sistematik olarak analiz etti ve sistemin çeşitli kültürler hakkında kaba klişeler ürettiğini buldu . Gazetecilere göre, şirket yorum taleplerine yanıt vermedi. Filipinler Araştırmacı Gazetecilik Merkezi’nden bir başka araştırma ise, popüler bir araç çağırma uygulaması olan Grab’ın algoritmik çıktısını binlerce yolculuk fiyat teklifi toplayarak tersine mühendislik yöntemiyle inceledi. Grab’ın, yalnızca yoğun trafik saatlerinde geçerli olması gereken ek ücretler uyguladığını buldu . PCIJ’ye yazılı bir yanıtta, Grab’ın Filipinler operasyonları, duruşmalara katılarak “[Kara Ulaşım Ruhsatlandırma ve Düzenleme Kurulu]’nun soruşturmasıyla tam iş birliği yaptığını” belirtti.
Yapay Zekâ Uygulamalarını İncelemek
Son olarak, gazetecilerin yapay zekanın gerçek dünyada nasıl kullanıldığını incelemesi önemli. Yapay zeka teknolojisi beklendiği gibi çalışmadığında veya arızalandığında, algoritmalar veya üretken yapay zeka uygulamaları gibi otomatik sistemler tarafından alınan kararlara tabi olan birçok insan zarar görebilir.
Guardian muhabiri Johana Bhuiyan, ABD hükümetinin yapay zekâ çeviri uygulamalarına aşırı bağımlılığının, bir sığınmacının altı ay boyunca ICE gözaltı merkezinde mahsur kalmasına nasıl yol açtığını gösterdi. Düşük kaynaklı dillerde kötü performans gösteren uygulama, sığınmacıyı yanlış çevirmiş ve kimseyle anlamlı bir şekilde iletişim kurmasını engellemişti. İç Güvenlik Bakanlığı (DHS), Guardian muhabirinin sorularına yanıt vermedi.
Hera Rizwan’ın Hindistan hükümetinin yüz tanıma teknolojisini kullanmasıyla ilgili haberinde, devlet memurlarının acil gıda yardımı dağıtmak için kullandığı uygulamanın, bazı hamile veya emziren kadınları tanıyamadığı, çünkü yüzlerinin hükümet veri tabanlarında yıllar öncesine ait olarak saklanan görüntülerden farklı göründüğü ortaya çıktı. Kadın ve Çocuk Geliştirme Bakanlığı Rizwan’ın sorularına yanıt vermedi.
Yapay Zekâ Hesap Verebilirliği Haberciliği Herkes İçindir
Yukarıdaki örneklerin de gösterdiği gibi, hesap verebilirlik çerçevemiz, gazetecilerin yapay zekâ hakkında çeşitli teknik çaba ve kaynak seviyeleriyle haber yapmalarına yardımcı olabilir. Haberler daha kısa veya daha uzun olabilir ve daha çok insan odaklı veya daha çok teknik olarak yürütülmüş olabilir. Ve umuyoruz ki bu yaklaşımlar ve örnekler, diğer gazetecilerin yapay zekâ hesap verebilirliği haberciliğine yönelik kendi yerel yaklaşımlarını bulmalarına yardımcı olur.
Kaynaklar
- Gazeteciler için Algoritmik Okuryazarlık : Gazeteciler için açıklamalar ve diğer kaynaklar içeren bir kaynak.
- Yapay Zeka Odak Serisi Açık Kaynaklı Müfredat : Pulitzer Merkezi’nin dünyanın dört bir yanındaki gazetecileri yapay zeka konusunda eğitmek amacıyla başlattığı girişimden video eğitimleri , çerçeveler ve slayt sunumları sunmaktadır .
- Gazeteciler İçin Yapay Zeka Tarafından Üretilen İçeriği Tespit Etme Rehberi
- Sosyal Medya Algoritmalarını Araştırma Rehberi
Araştırma
- Algoritmik Adalet Birliği : Algoritmik zararları belgeleyen ve inceleyen bir kuruluş.
- AI Now Enstitüsü : Yapay zeka ve algoritmik hesap verebilirlik üzerine araştırmalar yayınlayan bağımsız bir enstitü.
- Demokrasi ve Teknoloji Merkezi : Dijital çağda sivil özgürlükler konusunda raporlar yayınlayan kar amacı gütmeyen bir kuruluş.
- Veri ve Toplum : Teknoloji, veri ve politikalara odaklanan, kâr amacı gütmeyen bir araştırma kuruluşu.
- Algorithm Watch : Zürih ve Berlin merkezli, kar amacı gütmeyen bir grup.
- Privacy International : Londra merkezli, kar amacı gütmeyen bir kuruluş.
- Derechos Digitales : Latin Amerika’ya odaklanan kar amacı gütmeyen bir dijital haklar örgütü.
- Afrika Dijital Haklar Ağı : Afrika genelinde faaliyet gösteren dijital haklar örgütü.
 Gabriel Geiger, Atina, Yunanistan merkezli, gözetim ve algoritmik hesap verebilirlik haberciliği konusunda uzmanlaşmış bir araştırmacı gazetecidir. Şu anda Hollanda merkezli kar amacı gütmeyen bir haber kuruluşu olan Lighthouse Reports’ta araştırmacı gazeteci olarak çalışmaktadır. Çalışmaları WIRED, Le Monde, Der Spiegel ve Guardian gibi yayınlarda yer almıştır.
Gabriel Geiger, Atina, Yunanistan merkezli, gözetim ve algoritmik hesap verebilirlik haberciliği konusunda uzmanlaşmış bir araştırmacı gazetecidir. Şu anda Hollanda merkezli kar amacı gütmeyen bir haber kuruluşu olan Lighthouse Reports’ta araştırmacı gazeteci olarak çalışmaktadır. Çalışmaları WIRED, Le Monde, Der Spiegel ve Guardian gibi yayınlarda yer almıştır.
 Lam Thuy Vo , veri analizini saha haberciliğiyle birleştirerek sistemlerin ve politikaların bireyleri nasıl etkilediğini inceleyen bir gazetecidir. Şu anda göçmen topluluklarıyla ve onlar için haber yapmaya adanmış bağımsız, kar amacı gütmeyen bir haber kuruluşu olan Documented’da araştırmacı gazeteci ve Craig Newmark Gazetecilik Yüksek Lisans Okulu’nda veri gazeteciliği doçentidir. Daha önce The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America ve NPR’ın Planet Money programlarında gazetecilik yapmıştır.
Lam Thuy Vo , veri analizini saha haberciliğiyle birleştirerek sistemlerin ve politikaların bireyleri nasıl etkilediğini inceleyen bir gazetecidir. Şu anda göçmen topluluklarıyla ve onlar için haber yapmaya adanmış bağımsız, kar amacı gütmeyen bir haber kuruluşu olan Documented’da araştırmacı gazeteci ve Craig Newmark Gazetecilik Yüksek Lisans Okulu’nda veri gazeteciliği doçentidir. Daha önce The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America ve NPR’ın Planet Money programlarında gazetecilik yapmıştır.
Ülkelere Göre Açık Kaynak Veritabanları

Gıda Güvenliği Sorunlarını Araştırma Rehberi

Gazeteciler için Yapay Zeka Tarafından Oluşturulan İçeriği Tespit Etme Rehberi!

Sosyal Medya Algoritmalarını Araştırma Rehberi
PDF’lerden Veri Çıkartmak için ChatGPT Kullanma Potansiyelinin Test Edilmesi!

Araştırmacı Gazetecilik Hikâyelerini Her Platformun Diline Uyarlamak

Türkiye’den Demokratik Kongo Cumhuriyeti’ne: GIJN’in Yeni Üyeleri Açıklandı!

Veri Odaklı Düşünme Biçimi Geliştirmek: Editörler için Temel İpuçları!

Bu Çalışma Bir Lisans Altında Lisanslanmıştır Creative Commons Atıf-Türevi Olmayan 4.0 Uluslararası Lisansı
İçeriklerimizi bir Creative Commons Lisansı Altında Ücretsiz, Çevrim içi veya Basılı Olarak Yeniden Yayınlayın.
Bu Yazıyı Yeniden Yayınla
Bu Çalışma Bir Lisans Altında Lisanslanmıştır Creative Commons Atıf-Türevi Olmayan 4.0 Uluslararası Lisansı
Sonrakini Oku
Haber Yazım Araçları ve İpuçları
PDF’lerden Veri Çıkartmak için ChatGPT Kullanma Potansiyelinin Test Edilmesi!
PDF gibi metin belgelerini elektronik tablolara dönüştürmek sıkıcı ve pahalı bir iştir. Yapay zeka aracı ChatGPT’nin PDF’lerden ne kadar iyi veri çıkarabildiğini görmek için veri gazetecisi Brandon Roberts iki belge setini elektronik tablolara dönüştürmek için bir Python betiği yazdı.
Araştırmacı Gazetecilik Hikâyelerini Her Platformun Diline Uyarlamak
Aylar süren karmaşık bir araştırmayı, güvenilirliğini koruyarak hızlıca içerik tüketen kitlelere nasıl ulaştırabilirsiniz? Bunun yolu, her sosyal medya platformunun kitlesine ve iletişim diline uygun içerikler üretmekten geçiyor.
Türkiye’den Demokratik Kongo Cumhuriyeti’ne: GIJN’in Yeni Üyeleri Açıklandı!
GIJN, aralarında Türkiye’nin de bulunduğu dokuz ülkeden 10 yeni üyeyi ağına kabul etti. Yeni üyeler arasında sürgünde faaliyetlerini sürdüren iki haber merkezi, çevre ve iklim krizine odaklanan araştırmacı gazetecilik kuruluşları ile organize suçlar ve insan hakları ihlalleri üzerine çalışan çeşitli kurumlar yer alıyor.
Veri Gazeteciliği
Veri Odaklı Düşünme Biçimi Geliştirmek: Editörler için Temel İpuçları!
Veri, gazetecilerin yerel yönetim harcamalarından küresel iklim değişikliği örüntülerine kadar pek çok konuyu ele alış biçiminin ayrılmaz bir parçası haline gelmiş durumda ancak bu alanda uzmanlık geçmişi olmayan editörler için veriyle çalışmak göz korkutucu olabilir.