
Putting the “Open” in Open Data: Creating a Global Standard

Step-By-Step Guide for Journalists on the Basics of Google Sheets

Tipsheet for Using Ocean Data in Your Investigations

No Coding Required: A Step-by-Step Guide to Scraping Websites With Data Miner

GIJC23 – The Future of Data Journalism: New Analytical Tools, Data Visualization, and AI
 Open Data reached a new milestone last week with publication of the first working draft of Open Data Standards by the W3C (World Wide Web Consortium). Open Data is spreading across the globe and transforming the way data is collected, published, and used. But all of this is happening without well-documented standards, leading to data published with inconsistent metadata, lacking official documentation of approval processes, corroboration of sources, and with conflicting terms of use. Often Open Data is hard to compare to other sources, even across administrative departments located in the same building. Open Data from more than one source has to be aggregated, normalized, cleansed, checked for quality, verified for authenticity, and validated for terms of use, at huge expense before it can be analyzed.
Open Data reached a new milestone last week with publication of the first working draft of Open Data Standards by the W3C (World Wide Web Consortium). Open Data is spreading across the globe and transforming the way data is collected, published, and used. But all of this is happening without well-documented standards, leading to data published with inconsistent metadata, lacking official documentation of approval processes, corroboration of sources, and with conflicting terms of use. Often Open Data is hard to compare to other sources, even across administrative departments located in the same building. Open Data from more than one source has to be aggregated, normalized, cleansed, checked for quality, verified for authenticity, and validated for terms of use, at huge expense before it can be analyzed.
The Data on the Web Best Practices Working Group (I am a co-chair) spent the better part of six months studying 26 Open Data use cases to understand how the lack of standards is retarding the growth of an industry that should be transforming government and fueling economic growth at much higher rates. We heard direct testimony on teleconferences and webinars form Open Data leaders in cities and nations across the world. We interviewed practitioners, and compiled a dossier of Open Data challenges and issues requiring standards to move the industry forward.
 In six months following our Use Case analysis, we met in San Mateo, Californiam and created the outline for the Best Practices document we published last weekIt provides the Open Data industry with recommendations and guidance for the following areas:
In six months following our Use Case analysis, we met in San Mateo, Californiam and created the outline for the Best Practices document we published last weekIt provides the Open Data industry with recommendations and guidance for the following areas:
Metadata
- What kind of metadata should be considered when describing data on the Web?
- How can metadata be provided in a machine readable way?
Data Identification
- How can unique re-use be provided for data resources?
- How should URIs be designed and managed for persistence?
Data Formats
- What kind of data formats should be considered when publishing data on the Web?
 Data Vocabularies
Data Vocabularies
- How can existing vocabularies be used to provide semantic interoperability?
- How can a new vocabulary be designed if needed?
Data Licenses
- How can data licenses be made machine readable?
- How can license information about data published on the Web be provided/gathered?
Data Provenance
- How can data provenance information about data published on the Web be provided/gathered?
Data Quality
- How can data quality information about data on the Web be provided/gathered?
 Sensitive Data
Sensitive Data
- How can data be published without infringing a person’s right to privacy or an organization’s security?
Data Access
- What kind of data access should be considered when publishing data on the Web?
- What requirements should be taken into account when deciding how to make data available on the Web?
Data Versions
- How can different versions of a dataset be tracked and managed?
Data Preservation
- How can publishers decide when and how data on the Web should be archived?
Feedback
- How can user feedback about data consumed from the Web be gathered?
This might not look very sexy, but let me tell you: Open Data that is published using these Best Practice Standards WILL BE VERY SEXY. It will be easy to collect, verify, share, analyze, monetize, and re-produce.
It will give journalists new tools in how they verify sources and document government corruption. It will provide universities with dependable Open Data that can uncover vast new areas of social, political, organizational, and scientific research. And it will provide private companies with a vast sea of free information to power new businesses and reap impressive rewards.
It isn’t magic. It is a common sense approach to standards. We are recommending things many already know and do but not everyone does it all the time or equally well.
 It is not comprehensive. We are a small team and we don’t know everything. So we invite the world to read what we have written and provide feedback. We want our ideas to spark a global dialog on how to structure Open Data Best Practices – what should be included, excluded, and refined. We welcome criticism, new ideas, and debate.
It is not comprehensive. We are a small team and we don’t know everything. So we invite the world to read what we have written and provide feedback. We want our ideas to spark a global dialog on how to structure Open Data Best Practices – what should be included, excluded, and refined. We welcome criticism, new ideas, and debate.
Our goal is simple. We want to change the world by making Open Data the dependable free resource that illuminates, enlightens, and transforms our planet with insight and knowledge without the pre-condition of publication for a purpose or select audience.
It should be free for all, and all for free. Dependable. Reliable. Available.
Please help us by reading our work and sending in your comments.
 Steven Adler (@DataGov) is chief information strategist for IBM. He is an expert in data science and an innovator who has developed billion-dollar-revenue businesses in the areas of data governance, enterprise privacy architectures, and Internet insurance. He has advised governments and large NGOs on open government data, data standards, privacy, regulation, and systemic risk.
Steven Adler (@DataGov) is chief information strategist for IBM. He is an expert in data science and an innovator who has developed billion-dollar-revenue businesses in the areas of data governance, enterprise privacy architectures, and Internet insurance. He has advised governments and large NGOs on open government data, data standards, privacy, regulation, and systemic risk.
Step-By-Step Guide for Journalists on the Basics of Google Sheets
Tipsheet for Using Ocean Data in Your Investigations
No Coding Required: A Step-by-Step Guide to Scraping Websites With Data Miner
GIJC23 – The Future of Data Journalism: New Analytical Tools, Data Visualization, and AI

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
Data Journalism
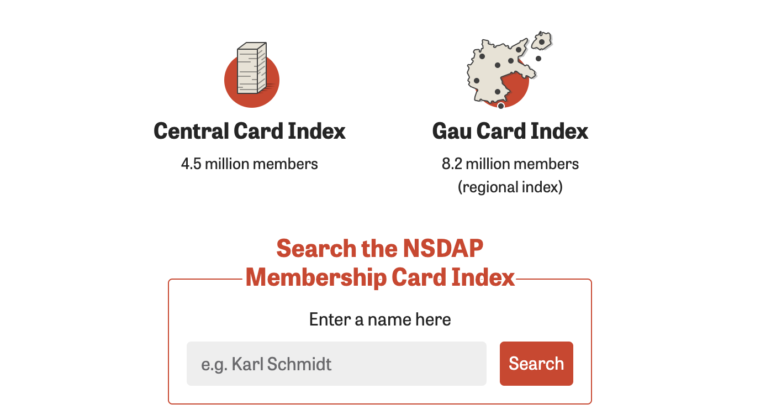
One Name at a Time: How Die Zeit Built a Searchable Database of Nazi Party Members
An online tool set up by the German newspaper Die Zeit, in cooperation with archives in Germany and in the United States, allows people to search several million Nazi Party membership cards.

Data Journalism
How the Hindu Is Embedding AI Into Its Data Journalism
LLMs are quietly reshaping data journalism workflows at The Hindu, helping reporters process vast document sets, write scripts and build interactive tools.

Data Journalism
Developing a Data State Of Mind: Key Tips for Editors
Data is woven into how journalists cover everything from local government spending to global climate change patterns, but for editors without a specialist background, it can be daunting.

Data Journalism
2026 Sigma Awards for Data Journalism Open for Entries – Deadline Extended
The Sigma Awards celebrate the best data journalism from around the world. Submissions are now open for data projects published in 2025.