Beginner’s Guide to Extracting Data from PDFs
Read this article in




Journalists get lots of data in PDF format — they can be tables of data that are embedded in reports, or spreadsheets that have been thoughtfully saved as PDFs before they’re emailed to you — but until you can get that data into a spreadsheet, there’s not much you can do with it.
Luckily, there are a few great tools that can liberate your data quickly and relatively easily. I’ve listed some of the ones that I’ve tried out here (though there are no doubt loads more out there) as well as some tips on some of the more fiddly parts of scraping PDFs, including rotated tables, converting scanned PDFs and password protected PDFs.
Tabula
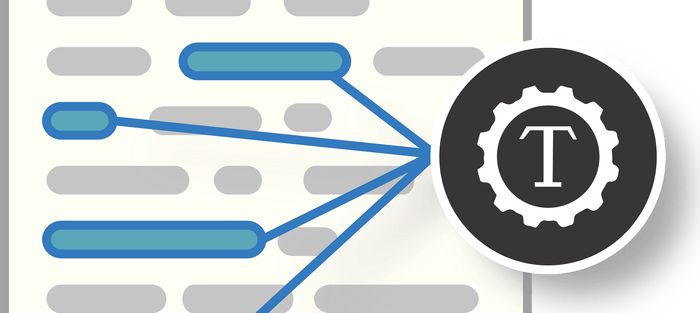
![]() I love Tabula. It’s my go-to option, firstly because it’s free, and secondly because it’s really easy to use. Its website says it was created “by journalists for journalists,” which is probably why it’s so popular with non-techie people like me.
I love Tabula. It’s my go-to option, firstly because it’s free, and secondly because it’s really easy to use. Its website says it was created “by journalists for journalists,” which is probably why it’s so popular with non-techie people like me.
I often need to extract tables of data from biggish PDF reports. Tabula lets you upload an entire document and select just the tables you want. You can convert one table at a time, or a few, depending on the layout of your document, into a CSV, TSV of JSON file, which you can import to Google Sheets (free), Libre Office Calc (free), Excel (not free), or whatever program you prefer.
The only times I don’t go straight to Tabula is when I have PDFs that have been scanned in, or when the tables I want to convert are rotated 90 degrees. But I’ll deal with those later.
Cometdocs
This one is also popular with journalists — not least because Investigative Reporters and Editors members get free premium membership — and it’s really easy to use. You can convert up to five documents a week for free, but you have to subscribe if you want to do more. I quite like the fact that you can subscribe for a month at a time for $9.99, but if you really like it you can get a lifetime membership for about $130.
 This is how it works: upload or import the PDF you want to convert, click the convert button and choose between Excel and .ODS (which you can open in Libre Office), unfortunately .CSV isn’t an option. If you don’t have either of those spreadsheet packages, you can upload the file to Google Drive and open it in Google Sheets.
This is how it works: upload or import the PDF you want to convert, click the convert button and choose between Excel and .ODS (which you can open in Libre Office), unfortunately .CSV isn’t an option. If you don’t have either of those spreadsheet packages, you can upload the file to Google Drive and open it in Google Sheets.
It works quickly and well, but the really nice thing about Cometdocs is that it does optical character recognition (OCR), so it can convert scanned PDFs. You need to check the converted document against the original, though, just to be sure it picked everything up correctly. Like Tabula, it can’t handle tables that are rotated.
Adobe Export PDF
This one’s not free, but it’s not terribly expensive either — about $24 a year. If you use Adobe Reader, which is Adobe’s free PDF reader, Export PDF allows you to convert a PDF document that you’ve opened in Acrobat Reader to Excel, Word, PowerPoint or RTF. It works well and quickly with fairly big documents. But, like Tabula, it can’t do scanned documents or rotated tables.
Nitro Pro
 If you have a Windows machine, Nitro is a great tool for editing and converting PDFs to useful formats, but it’s not free (about $160) and the fact that it only works with Windows means it’s out of reach for me and my MacBook. I have tried it out on somebody else’s machine, though, and I was suitably impressed.
If you have a Windows machine, Nitro is a great tool for editing and converting PDFs to useful formats, but it’s not free (about $160) and the fact that it only works with Windows means it’s out of reach for me and my MacBook. I have tried it out on somebody else’s machine, though, and I was suitably impressed.
Acrobat Pro
This one is accessible for Mac users, but it’s also not free (about $15 a month and it requires an annual commitment).
Zanran
 This UK-based company has developed software to automate PDF processing. It’s not free, but you can see what it can do by trying out it’s demo document converter — as long as your document is 1.5MB or smaller. You upload your PDF, tell them what you want it converted to, give them your email address and they’ll mail you the converted document.
This UK-based company has developed software to automate PDF processing. It’s not free, but you can see what it can do by trying out it’s demo document converter — as long as your document is 1.5MB or smaller. You upload your PDF, tell them what you want it converted to, give them your email address and they’ll mail you the converted document.
Zamzar
This is another online conversion tool where you can upload your document, choose the format you want to convert it to and it’ll email the converted document to the email address of your choice.
Rotated Tables
Sometimes the tables in PDF documents have been rotated 90 degrees. You need to be able to rotate the tables back to a normal orientation before any conversion tool will be able to identify them as text. Just rotating the page in Acrobat Reader or Preview, for example, won’t work. You need to rotate the table itself. To do this you need a proper PDF editor such as Acrobat Pro or Nitro Pro.
If you have Acrobat Pro, here’s what you do:

- If your tables are part of a larger document, open your document and, using the Organize Pages option, extract the pages with the tables you want to rotate. If you want to extract a number of consecutive pages, it’s easier to extract them into separate files.
- Open the page with the table on it. Go to the View menu and rotate until your table is upright.
- If there are headers and footers or any other text that is not rotated in the same direction as your table, remove them using the Edit PDF function – you need to delete them, covering them up doesn’t work.
- Go to the Enhance Scans option and choose Recognize Text; check the settings to make sure the option “Save as editable text and images” is selected. This may take a few minutes and when it’s finished your table may be rotated 90 percent again.
- Go back to View and rotate your page until the table is upright again. Then save your file.
- You can try to convert your page to an Excel spreadsheet using the Export PDF function, but I find that Tabula generally does the job better.
- Always check the converted data against the original documents because sometimes 8s can be mistaken for 6s or Bs. But even if your converted document isn’t absolutely perfect, converting it this way will be much quicker than manually typing it into a spreadsheet.
Converting Scanned PDFs
 In a scanned PDF, a table will be identified as an image rather than text, so if you want to extract the data from a table you first need to convert it to text with something that has optical character recognition (OCR). You can use Cometdocs, Acrobat Pro or Nitro Pro. Acrobat Pro’s Enhance Scans tool should recognize the text in your PDF as long as the quality of the scan isn’t terrible. Sometimes it helps to save a snapshot of the table you want to extract into its own PDF before you use the Enhance Scans tool. Once the scan is converted to text and images I still save it as a PDF and convert it to a CSV with Tabula. And, of course, always check your data against the original.
In a scanned PDF, a table will be identified as an image rather than text, so if you want to extract the data from a table you first need to convert it to text with something that has optical character recognition (OCR). You can use Cometdocs, Acrobat Pro or Nitro Pro. Acrobat Pro’s Enhance Scans tool should recognize the text in your PDF as long as the quality of the scan isn’t terrible. Sometimes it helps to save a snapshot of the table you want to extract into its own PDF before you use the Enhance Scans tool. Once the scan is converted to text and images I still save it as a PDF and convert it to a CSV with Tabula. And, of course, always check your data against the original.
Password Protected PDFs
 Sometimes PDFs are password protected so that you can’t edit them or convert them to any other format. If you have a Mac with Preview, try opening your PDF in Preview, then select the Export as PDF option under the File menu. Open the new version of your PDF and see if you’re able convert it to a spreadsheet now.
Sometimes PDFs are password protected so that you can’t edit them or convert them to any other format. If you have a Mac with Preview, try opening your PDF in Preview, then select the Export as PDF option under the File menu. Open the new version of your PDF and see if you’re able convert it to a spreadsheet now.
Do you have a favorite tool for extracting data from PDFs? Let me know. You can find me on Twitter: @laurajgrant.
This is part three of an occasional series on useful tools for data journalists on the Media Hack Collective’s Journalism Toolbox. It is reposted here with permission.
 Laura Grant is a data journalist and a managing partner of the Media Hack Collective, a collaboration dedicated to digital storytelling. She has been a journalist for more than 20 years, and is the former associate editor of digital and data projects at South Africa’s Mail & Guardian, where she produced data-driven stories, interactive graphics and maps.
Laura Grant is a data journalist and a managing partner of the Media Hack Collective, a collaboration dedicated to digital storytelling. She has been a journalist for more than 20 years, and is the former associate editor of digital and data projects at South Africa’s Mail & Guardian, where she produced data-driven stories, interactive graphics and maps.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next

Data Journalism Reporting Tools & Tips
From NICAR25, Four Free Cutting Edge and Time-Saving Investigative Data Tools
GIJN shares some of the no-cost, easy-to-use data tools that NICAR25 conference panelists described as surprisingly useful but unknown by investigative reporters.
Data Journalism Data Journalism Top 10
Data Journalism Top 10: Climate Crises, Tech Layoffs, Border Fences, and Banned Books
This week our top ten in data journalism features stories digging into the link between Ebola outbreaks and deforestation, on the stark impact of global warming on everything from crop yields to species loss, and the undeniable increase in the number of hot nights in Singapore.

Data Journalism
Data Journalists Offer Tools for the Future
Data journalism has evolved from simple spreadsheet analysis of local government data to the spectacular tracking of the hidden wealth of oligarchs, autocrats, and corporate leaders from gigantic datasets. In a session at GIJC21, leading data journalists looked at this transition but also, at what is next.

Reporting Tools & Tips
Digging Up Hidden Data with the Web Inspector
Many reporters never notice the “inspect element” option below the “copy” and save-as” functions in the right-click menu on any webpage related to their investigation. But it turns out that this little-used web inspector tool can dig up a wealth of hidden information from a site’s source code, reveal the raw data behind graphics, and download images and videos that supposedly cannot be saved.