
Quatre angles régulièrement utilisés par les datajournalistes pour traiter un sujet
Lire cet article en
Dans cet article, initialement publié par Paul Bradshaw sur Online Journalism Blog et reproduit ici avec sa permission, le spécialiste de data journalisme enseignant à l’Université de Birmingham dévoile les quatre angles à connaître pour traiter un sujet en mode #ddj.
Dans le cadre de mon enseignement du journalisme de données, il m’arrive souvent de parler des différents formats utilisés dans le journalisme de données. Il m’a donc paru utile de dresser une liste de 100 articles de data journalisme puis de les analyser afin de voir à quelle fréquence l’on retrouve ces différents formats-types.
Ce travail m’a révélé qu’il existe sept approches-types pour traiter des ensembles de données. Beaucoup d’articles intègrent d’autres approches de manière secondaire (ainsi, le récit d’une évolution peut dans un deuxième temps parler de l’ampleur du problème), mais tous les articles de data journalisme que j’ai examinés ont pris l’une d’elles comme fil conducteur.
Dans ce premier article d’une série en deux parties, j’explique comment les quatre angles les plus couramment employés peuvent vous aider à trouver des idées de sujet puis à les mettre en œuvre. J’explique également ce qu’il faut garder à l’esprit tout au long de ce travail.
Angle n°1 : l’ampleur – “Voici l’ampleur du problème”
Quantifier l’ampleur d’un problème est probablement le sujet de data journalisme le plus fréquent. Il s’agit d’articles qui identifient un problème majeur ou établissent l’ampleur d’un problème qui fait déjà d’actualité.

Image : Capture d’écran, The New York Times
Fondamentalement, ces articles informent les lecteurs des dernières données disponibles : qu’il s’agisse des derniers chiffres du chômage, du taux de criminalité, de la pollution de l’air, de l’argent investi dans certains domaines, des naissances, des décès ou des mariages.
Pendant les premiers mois de la pandémie, par exemple, les médias ont publié quotidiennement des articles traitant entre autres du nombre de cas, de décès et de tests de dépistage.
“Le nombre de morts du coronavirus dans les maisons de retraite au Royaume-Uni pourrait avoir atteint 6 000, selon une étude” (Financial Times, avril 2020) et “Le programme de révision des peines indûment clémentes serait « inadéquat »” (BBC News, juillet 2019) sont deux exemples d’articles qui se focalisent sur la question de l’ampleur d’un problème.
La question de l’ampleur est parfois secondaire, servant de contexte à un évènement particulier – “Un drone perturbe l’aéroport de Gatwick” (combien d’accidents liés à des drones ont été évités de peu ?) – ou à une idée de réforme politique : “Les nouveaux conducteurs pourraient être interdits de conduite la nuit, selon plusieurs ministres” (combien de nouveaux conducteurs ont moins de 19 ans ?).
Traiter de l’échelle d’un problème n’est pas ce qu’il y a de plus compliqué à faire : dans de nombreux cas, aucun calcul n’est nécessaire.
Le travail consiste dans la plupart des cas à contextualiser l’information : dans le pire des cas, un article traitant de l’ampleur d’un problème devient simplement une histoire de “chiffres impressionnants” (“Beaucoup d’argent a été dépensé” ou “Quelque chose est arrivé à un grand nombre de personnes”), sans qu’il soit précisé pourquoi cette information est digne d’intérêt.
C’est pourquoi il est important de replacer l’ampleur révélé dans un contexte plus large, en utilisant des pourcentages et des proportions (par exemple “un sur cinq”), voire des comparaisons et des analogies (“L’argent investi dans ce programme équivaut au salaire de 500 enseignants”).
Vous pouvez également introduire l’idée d’une évolution comme angle secondaire, en montrant comment ces chiffres évoluent dans le temps.
Dans l’article du New York Times ci-dessus, le “véritable bilan” (l’ampleur) de l’épidémie de coronavirus est immédiatement contextualisé par des graphiques qui montrent les évolutions statistiques depuis le début de l’année, et ce dans différentes régions du pays.
Angle n°2 : évolution et constance – Augmentations, diminutions, chiffres stables

Screenshot, Belfast Telegraph
Les articles traitant d’évolutions sont presque aussi courants que ceux traitant d’ampleur, et probablement plus simples à vendre à un rédacteur-en-chef.
Après tout, toute évolution est intrinsèquement digne d’intérêt et vous permet de titrer votre article avec un verbe de mouvement (“monte”, “chute”, etc.).
Une fois que vous aurez remarqué une évolution dans les données dont vous disposez, vous aurez probablement besoin de travailler davantage pour en déterminer les causes. Pourquoi ces chiffres augmentent-ils ou diminuent-ils ?
Vous pouvez également ajouter un angle secondaire à votre traitement, en explorant les variations au sein de cette tendance – c’est-à-dire les domaines dans lesquels ces chiffres ont le plus augmenté ou diminué.
Cela peut vous aider à comprendre les causes de l’évolution que vous avez remarquée : il y a de fortes chances que les zones les plus touchées soient particulièrement conscientes du problème et à même de vous l’expliquer.
Lorsque vous faites état d’un changement, il est important de garder deux éléments à l’esprit : la saisonnalité et les marges d’erreur.
La saisonnalité est le rôle que jouent les facteurs saisonniers (généralement prévisibles et normaux, et donc non dignes d’intérêt) dans les chiffres, comme la fin d’un exercice financier ou d’un trimestre scolaire, la sortie de nouveaux modèles de voiture ou simplement les changements de température. Des comparaisons annuelles (ce mois d’août par rapport à août dernier, par exemple) ou une correction saisonnière permettent d’éviter cet écueil.
La marge d’erreur, quant à elle, est la plage dans laquelle se situent les vrais chiffres. Puisque de nombreux ensembles de données sont tirés d’échantillons, qui sont ensuite extrapolés au reste de la population examinée, une marge d’erreur (ou intervalles de confiance) permet d’indiquer le degré de précision de cette extrapolation. Si une évolution se situe dans cette marge d’erreur, nous ne pouvons affirmer que quelque chose a changé.
Une variante du format évolution est l’absence d’évolution. Ainsi, ce reportage sur les faillites d’entreprises a pris comme point de départ une évolution probable, mais a fini par découvrir que le nombre d’entreprises faisant faillite n’a pas augmenté pendant la pandémie. Les journalistes ont donc sollicité les points de vue d’experts pour analyser cette réalité contre-intuitive.
Angle n°3 : classement et valeurs aberrantes – Qui est le meilleur, qui est le pire ? Qui sort des sentiers battus et pourquoi ?

Cet article de The Economist est un article de « classement » car il identifie le mois le plus “déprimant”. Image : Capture d’écran, The Economist
Les articles de classement s’intéressent aux points de données les plus positifs ou négatifs dans un ensemble de données, ou permettent de comparer l’entité qui nous intéresse (qu’il s’agisse d’une police municipale, d’une école ou d’une filière de l’économie) à d’autres.
“Ce quartier connait un taux de criminalité particulièrement élevé” ou “Ces écoliers ont obtenu les troisièmes meilleurs résultats du pays” sont deux exemples de ce genre d’article de datajournalisme.
Vous pouvez vous concentrer sur les endroits “les plus touchés”, comme dans l’article “Ce quartier de Birmingham figure dans le top 10 des endroits au Royaume-Uni les plus touchés par les paiements anticipés sur les prestations sociales”, ou encore comparer la filière qui vous intéresse à d’autres, comme dans l’article “Le bâtiment est la troisième filière la plus dangereuse au Royaume-Uni”.
Mais les articles de classement peuvent également porter sur les meilleurs ou les pires moments, lieux ou catégories qu’un ensemble de données “révèle”.
L’article de The Economist ci-dessus, par exemple, porte sur le mois où le plus grand nombre de personnes écoutent des chansons tristes. Une histoire de Birmingham Live couvre “les crimes les plus courants à Sandwell – et les endroits qui dénombrent le plus grand nombre de victimes”.
Soit dit en passant, The Economist a consacré toute une partie d’un bulletin d’information sur le journalisme de données à “Comment réaliser un indice” :
“Dans quelle mesure de tels indices sont-ils utiles ? Tout classement qui ne repose pas sur des critères objectifs est susceptible d’être critiqué. Les classements qualitatifs reposent sur des mesures subjectives. L’adjectif “tolérable” pourrait signifier presque la même chose pour quelqu’un que l’adjectif “inconfortable” – alors que “intolérable” peut sembler deux fois pire qu’”indésirable” ? Sur les échelles ordinales, la distance entre ces mesures est subjective – et pourtant, il faut leur attribuer un score numérique pour que le classement fonctionne.
“The Economist publie son indice Big Mac, une mesure de la valorisation des devises, depuis 1986. En 2011, nous avons publié l’indice Shoe-Thrower [lanceur de chaussure], qui évaluait le potentiel de troubles dans le monde arabe. Et cette année, nous avons créé un indice de normalité mondial, qui suit la reprise des pays après le Covid-19. Mieux vaut une mesure imparfaite que de n’avoir aucun moyen de comparaison”.
Les articles de classement doivent être attentifs au contexte : une zone peut connaître le plus de criminalité, de maladies ou de pollution simplement parce qu’elle compte également le plus d’habitants. Les dates de collecte des données peuvent également fausser les résultats : le nombre de cas de Covid a tendance à augmenter le mardi parce que ces chiffres « incluent de nombreux décès non signalés au cours du week-end », comme le fait remarquer FullFact.

Image : Capture d’écran, FullFact.org
Angle n°4 : Variation – Hasard géographique, cartes et distributions

Cet article par Aimee Stanton de la BBC Shared Data Unit a relevé les différences d’accès aux stations de recharge pour voitures électriques. Image : Capture d’écran, BBC
Les articles traitant de variations sont d’autant plus intéressants lorsque celles-ci sont inattendues ou révèlent quelque chose de notre quotidien.
De nombreux articles de ce genre emploient une carte choroplèthe ou une carte thermique pour montrer comment les régions d’un pays ont plus ou moins accès à quelque chose, ou connaissent plus ou moins de demande pour quelque chose.
Ces cartes peuvent mettre en lumière le fait que l’accès d’une personne à quelque chose qui est censé être distribué de manière égale sur tout le territoire dépend en réalité du lieu où elle se trouve.
Ainsi, l’article de la cellule de datajournalisme de la BBC “Le système de la santé publique rationne l’accès de certains couples à la fécondation in vitro” montre que là où on habite peut déterminer si on aura ou non accès à un traitement de fertilité.
Un article sur les variations géographiques peut révéler des injustices – ou approfondir nos connaissances d’injustices déjà connus.
Les articles sur les dérives des algorithmes, dont la série “Les biais des machines” de ProPublica, traitent en particulier des variations et des injustices que révèle une analyse poussée du fonctionnement des algorithmes. Ainsi, les algorithmes peuvent fixer des devis d’assurance différents pour deux personnes dont les critères sont pourtant très proches.
Ce genre d’article peut également mettre en évidence les zones de demande mal desservie ou les zones où l’offre manque : dans le cadre d’un article sur lequel j’ai travaillé pour la BBC Shared Data Unit concernant les stations de recharge pour voitures électriques, il nous a fallu établir le nombre et l’emplacement des infrastructures existantes dans tout le pays. Ces données ont fourni une base de travail pour réaliser des études de cas et alimenter nos réflexions sur le sujet.
Dans la deuxième partie de cette série, j’aborde les trois autres formats-types : les articles d’exploration ; ceux qui se concentrent sur la qualité, l’existence ou l’absence de données ; et ceux qui traitent de relations. Une version du diagramme est également disponible en finnois.
This post was originally published by Paul Bradshaw in the Online Journalism Blog and is reprinted here with permission. Bradshaw leads the MA in Data Journalism at Birmingham City University.
In my data journalism teaching and training I often talk about common types of stories that can be found in datasets — so I thought I would take 100 pieces of data journalism and analyze them to see if it was possible to identify how often each of those story angles is used.
I found that there are actually broadly seven core data story angles. Many incorporate other angles as secondary dimensions in the storytelling (a change story might go on to talk about the scale of something, for example), but all the data journalism stories I looked at took one of these as its lead.
In the first of a two-part series I walk through how the four most common angles can help you identify story ideas, the variety of their execution, and the considerations to bear in mind.
Data Angle 1: Scale — ‘This Is How Big a Problem Is’
Perhaps the most common type of story found in data is the scale story: these are stories that identify a big problem, or the size of an issue which has become topical.
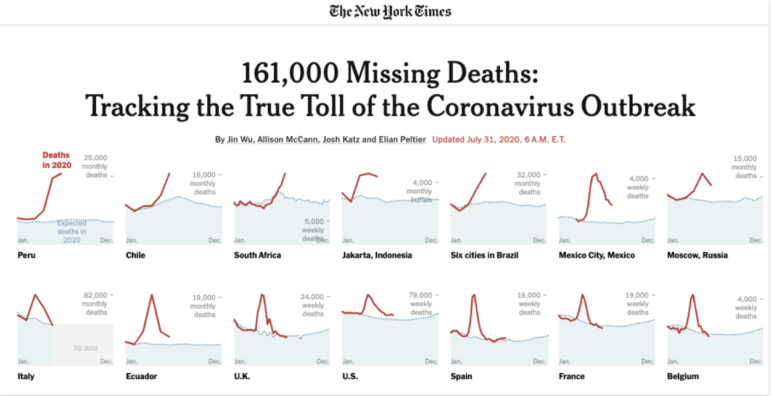
Image: Screenshot, The New York Times
At their most simple scale stories provide an update on new numbers being released: it could be the latest unemployment figures, the amount of crime, air pollution, money spent on some area, births, deaths, or marriages.
During the first months of the pandemic, for example, we had daily scale stories on the numbers of cases, deaths, and tests, among other things.
Examples of scale stories include Death Toll in UK Care Homes from Coronavirus May Be 6,000, Study Estimates, but also stories like Unduly Lenient Sentences Review Scheme ‘Inadequate,’ where the lead is based on reaction to the scale of an issue you have identified.
Sometimes scale is provided as background to a single-event story, as in Drone Causes Gatwick Airport Disruption (how many near misses are there?) or to a policy proposal, such as in New Drivers Could Be Banned from Driving at Night, Ministers Say (how many new drivers are under 19?).
Scale stories are one of the easier genres to write: in many cases no calculation is needed.
Indeed, the main work involved is likely to be in setting context to that scale — at its worst a scale story simply becomes a “big number” story (“A lot of money was spent on stuff” or “Something happens to a lot of people”), and the reader is left unclear whether this is actually newsworthy or just normal.
For that reason it’s important to put scale into context by using percentages or proportions (e.g. “one in five”) or comparisons and analogies (“The money spent on the scheme is the equivalent of the wages of 500 teachers”).
You might also bring in change and/or variation as a secondary angle: establishing historical context to the scale you’ve just outlined, or how that scale varies.
In the New York Times piece above, for example, the “true toll” (scale) of the coronavirus outbreak is immediately contextualized by charts which show how that has changed since the start of the year, in different parts of the country.
Data Angle 2: Change and Stasis — Things Are Going Up, Things Are Going Down, Things Aren’t Happening

Image: Screenshot, Belfast Telegraph
Change stories are almost as common as scale stories — and probably more straightforward to pitch.
After all, change is inherently newsworthy and gives you the verb (“rises,” “plummets,” “[goes] up”) that you need in a headline.
Once you’ve identified some sort of change in your data it’s likely you will need further reporting to answer the “why?” question. Why are those numbers going up or down?
You might also add a secondary angle to your story which explores variation in that trend – the areas where those numbers have gone up, or dropped, the most and least.
This can help you direct your reporting on “Why?” because chances are that the areas affected most will be those most aware of the issue, and able to comment on it.
When reporting on change it’s important to be aware of two considerations: seasonality and margins of error.
Seasonality is the role that (typically predictable and normal, and therefore non-newsworthy) seasonal factors can play in numbers, such as the end of a financial year or school term, the release of new cars or simply changing temperatures. Year-on-year comparisons (this August compared to last August, for example) or seasonal adjustment is often used to prevent this effect.
The margin of error, meanwhile, is the range within which the real numbers actually lie. Because many datasets are based on samples, which are then generalized to the rest of the population being looked at, a margin of error (or confidence intervals) is used to indicate how accurate that generalization actually is. If any change is within that margin of error then we can’t really report that anything has changed.
A variation of the change story is the lack of change angle. This story on company insolvencies, for example, looks for change where you would expect it, but identifies the absence of any increase in companies going bust during the pandemic and seeks expert comment for this counterintuitive finding.
Data Angle 3: Ranking and Outliers — Who’s Best and Who’s Worst? Who’s Unusual and Why?
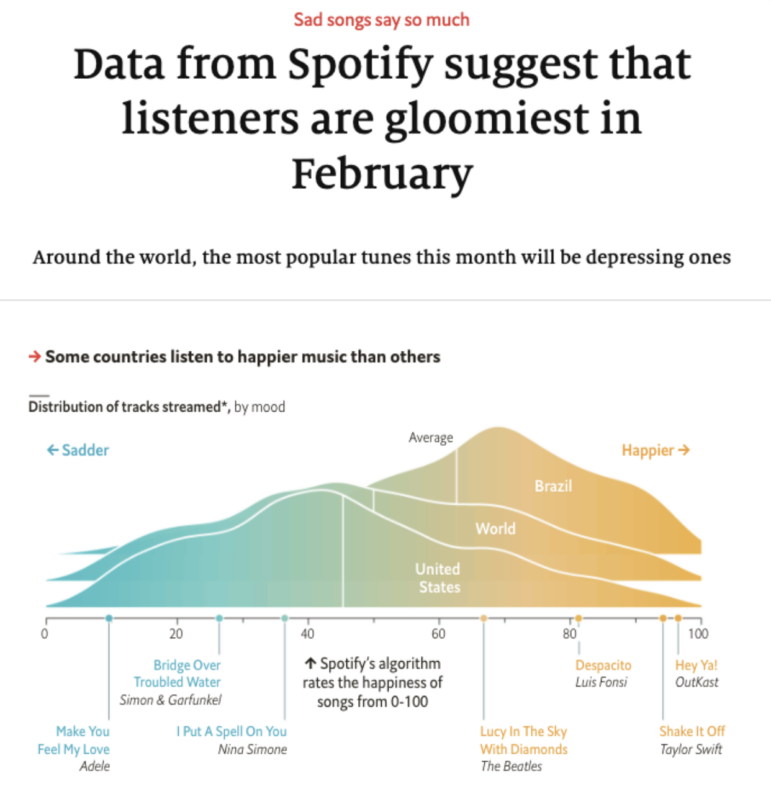
This article by The Economist is a “ranking” story because it identifies the “gloomiest” month. Image: Screenshot, The Economist
Ranking stories are all about who or what comes out worst or best in a dataset, or where a particular entity of interest (the local police force, schools or teams, or an industry if it’s the specialist press) sits in comparison to others.
Typical stories in this category might include “Local area one of worst areas for crime” or “Local schoolchildren get third-best results in the country.”
You might focus on the places “worst-hit,” as in The Parts of Birmingham in Top 10 UK Areas Worst-Hit by Universal Credit Advances, or you might look at where your sector compares to others, as in Construction Is Third-Most Dangerous UK Industry.
But ranking stories can also be about the best or worst times, places, or categories that a dataset “reveals.”
The Economist article above, for example, is about the top-ranked month for listening to gloomy songs. A Birmingham Live story, on the other hand, leads on The Most Common Crimes in Sandwell — And Where You’re Most Likely to Be a Victim.
The Economist, by the way, dedicated part of one data journalism newsletter to “How to compile an index:”
“How useful are such indices? Any ranking that isn’t built on objective criteria is open to criticism. Qualitative rankings are built on subjective measures. Perhaps ‘tolerable’ means almost the same to someone as ‘uncomfortable’ — whereas ‘intolerable’ might feel twice as bad as ‘undesirable?’ On ordinal scales the distance between these measures is subjective—and yet they have to be assigned a numerical score for the ranking to work.
“The Economist has been publishing its Big Mac index, a measure of currency valuations, since 1986. In 2011 we published the Shoe-Thrower’s index, which assessed the potential for unrest across the Arab world. And this year, we’ve created a global normalcy index, which is tracking countries’ recovery from COVID-19. An imperfect measure is better than having no means of comparison at all.”
Ranking stories need to be careful about context: an area may have the most crime, disease, or pollution simply because it also has the most people. Reporting dates can skew data, too: COVID case rates tended to peak on Tuesdays because the figures “include many deaths not reported over the weekend,” as FullFact pointed out.
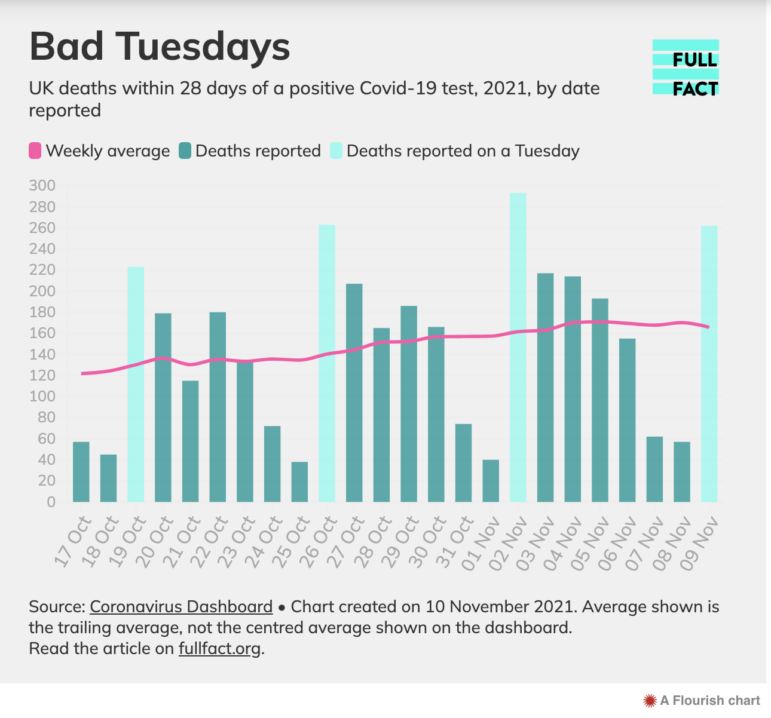
Image: Screenshot, FullFact.org
Data Angle 4: Variation — ‘Postcode Lotteries,’ Maps, and Distributions
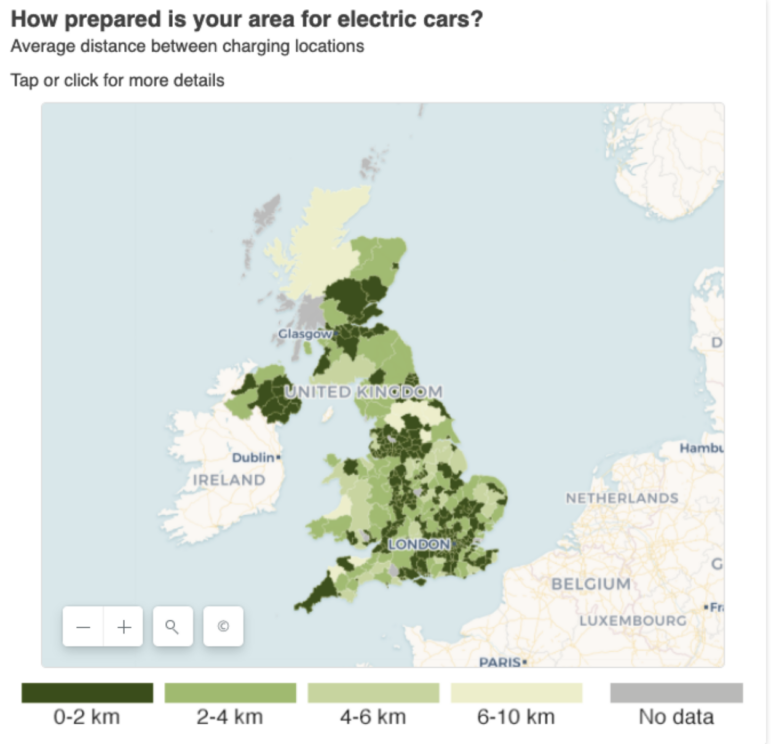
This BBC Shared Data Unit story by Aimee Stanton focused on the variation in access to electric car charging point. Image: Screenshot, BBC
Variation stories work best when we expect equal treatment, or when we seek to hold a mirror up to a part of life.
The classic example uses a choropleth map or heatmap to show how some parts of a country have less access to something, or more demand for something, than other parts.
The phrase “postcode lottery,” for example, reflects the sense that a person’s access to something that is supposed to be equally distributed is actually a game of chance.
The BBC data unit story IVF: NHS Couples ‘Face Social Rationing,’ for example, maps out how where you live in England can mean the difference between being able to access fertility treatment or not.
A variation story may be revealing that the unfairness exists — or, if people are aware of it, precisely how and where it plays out (particularly in their area).
Algorithmic accountability stories such as ProPublica’s Machine Bias series are often about variation and the unfairness that is revealed when an algorithm is unpicked: it may be people being sentenced differently, or given different insurance quotes, despite no meaningful difference between them on the dimensions that matter.
A variation story can equally be used to highlight areas of underserved demand, or lack of supply: one story that I worked on for the BBC Shared Data Unit about electric car charging points involved identifying how much infrastructure existed in the country, and where. The picture that the data painted provided a foundation for case studies and reaction.
In the second part of this series I look at the other three angles: exploratory stories; those that focus on data quality, existence, or absence; and angles about relationships. A version of the diagram is also available in Finnish.
Ressources complémentaires
10 étapes pour se lancer dans le data journalisme
Boîte à Outils : extraire des données sans savoir coder
Comment créer votre propre base de données
Découvrir les liens entre différents sites webs avec SpyOnWeb, VirusTotal et SpiderFoot HX
Les meilleurs outils pour collecter des données exclusives
 Paul Bradshaw encadre les masters de Data Journalisme et de journalisme multimédia et mobile at l’Université de Birmingham au Royaume-Uni. Il est également consultant en data journalisme au service data de BBC England.
Paul Bradshaw encadre les masters de Data Journalisme et de journalisme multimédia et mobile at l’Université de Birmingham au Royaume-Uni. Il est également consultant en data journalisme au service data de BBC England.

Guide pour enquêter sur les algorithmes des réseaux sociaux

Guide pour enquêter sur l’insécurité alimentaire
Guide du journaliste pour détecter les contenus générés par l’IA

Guide pour enquêter sur les entreprises chinoises en open source

« La recherche de preuves » : Ce qui a attiré les femmes datajournalistes de premier plan vers ce domaine

Humaniser sans sensationnaliser : enquêter sur le féminicide

10 erreurs courantes dans le data-journalisme

“Polluants éternels”, massacres de civils, trafic de bois africain : notre sélection des meilleures enquêtes 2023 en français

Ce travail est sous licence (Creative Commons) Licence Creative Commons Attribution-NonCommercial 4.0 International
Republier gratuitement nos articles, en ligne ou en version imprimée, sous une licence Creative Commons.
Republier cet article
Ce travail est sous licence (Creative Commons) Licence Creative Commons Attribution-NonCommercial 4.0 International
Lire la suite
Actualités et analyses Data journalisme
« La recherche de preuves » : Ce qui a attiré les femmes datajournalistes de premier plan vers ce domaine
À l’occasion de la Journée internationale du droit des femmes, GIJN a interrogé des femmes datajournalistes d’Argentine, du Kenya, de Suède et de Turquie pour savoir pourquoi elles ont choisi cette voie et quels sont les défis qui restent à relever.
Actualités et analyses Data journalisme Féminicide Outils et conseils pour enquêter
Humaniser sans sensationnaliser : enquêter sur le féminicide
Comment les journalistes peuvent-ils enquêter sur les féminicides sans réduire le meurtre de femmes à des statistiques criminelles, et comment produire un récit qui humanise sans sensationnaliser ?
Actualités et analyses Climat Data journalisme
10 erreurs courantes dans le data-journalisme
Riches retours d’expériences. GIJN a demandé à des data-journalistes à travers le monde quelles étaient les lacunes en matière de data-journalisme qu’ils constataient et quels étaient les sujets peu couverts que les salles de presse pouvaient aborder.
Actualités et analyses Climat Data journalisme Études de cas Outils et conseils pour enquêter
“Polluants éternels”, massacres de civils, trafic de bois africain : notre sélection des meilleures enquêtes 2023 en français
Du Cameroun au Canada, de Tunis à Paris, découvrez les huit enquêtes qui ont retenu l’attention de l’équipe francophone de GIJN cette année.