How to Save Online Evidence and Why It Matters: Part One



As journalists we are used to saving information. We securely store documents, keep meticulous notes, save and back up important emails on our computers. But what about the information we find online during the course of our investigations?
There are a few important issues to bear in mind and a few techniques you might want to consider. But, firstly, why is any of this important?
Information Changes
Content gets removed. Websites can remove controversial content with one click of a mouse. Posts sent to social media can be deleted or re-edited. If you haven’t saved this information you can’t use it later. With some stories it might also be useful to show changes to content over a period of time – for instance, the growth or decline in someone’s followers on Twitter.
Access Changes
Posts and photos sent publicly to Facebook can later be marked ‘friends only’. Friend lists can be made private. The same issues apply to Twitter and other social networks. Save the information while it’s in the public domain.
Legal Reasons
If you are making allegations based on an article or photo posted by someone online, it will be their word against yours, should they delete it. Save a copy and if need be send a copy to your legal team, as this will date stamp it on the email system.
OK, you’ve got it. But what is the best way to save information you find online? That really depends on the story and the nature of the content. It’s generally best to use a computer rather than a mobile device (unless your story relates to content found on an app). Let’s look at some of the popular techniques, starting with the basics:
Copying and Pasting
Very familiar to most of us, this involves highlighting some text and holding down the Control+c keys (Command+c for Mac users) to copy. You can then switch to the programme you are using to save the text and press Control+v keys to paste (or Command+v on a Mac). There are other ways to do this. Some prefer to choose copy and paste from the edit menu – others by right-clicking on the highlighted text or images they want to copy.
You may find that copying and pasting preserves the font used on the original web page. If you don’t want this, you can find programmes online that strip out the formatting. I use Steve Miller’s excellent PureText on my PC, but other products are available.
Saving Images from Web Pages
Images on web pages exist online independently of the web page which houses them. They have their own web address and file name and are usually in one of three formats: JPEG, PNG or GIF. You can save an image by right-clicking on it and choosing ‘Save Image’.
Tip: try to locate the largest possible version of an image to save on to your computer. It’s better to have that detail as you may need to focus on one small part of the image, like a street sign.
Screen-Grabbing or Screen Capture
You can copy an image of what you are seeing on your screen. This is done by simply pressing a few keys.
On a Mac that’s Command+Control+Shift+3. If you’re using a PC, press the Print Screen button, often marked ‘Prt Scr’, or ‘Alt Gr’ and ‘Prt Scr’ at the same time if you want to grab an active window.

You will now have a copy of your screen display, stored in your PC’s clipboard memory. You can then simply paste it into an email or a Word document or image editing program, often by pressing Control+v.
Tip: remember to close down any embarrassing tabs or remove any compromising information if your screengrab is going to be shown publicly.
Screen Capture Add-ons and Software
One of the drawbacks of the print screen function is that it will only produce an image of what you see on your screen when you press the button. Of course we have to scroll down through some web pages to see the entirety of the content and this can mean multiple screengrabs. One answer to this tedious problem is to let software handle the screen-grabbing for you.
You can find add-ons and extensions for your browser by looking in the Chrome Web Store or on the Firefox add-ons page. Many are available free of charge and install easily into your browser.
If your work involves a lot of screengrabs, it might be worth investing in serious screen capture software like Techsmith’s Snagit, which can also enable you copy regions of a web page, annotate captures, and even make videos of a website. This is sometimes vital in demonstrating the functionality of a site or preserving streaming content, videos and animations. An awful lot of screen capture programmes are out there – many free of charge.
Once you have captured a screengrab you can email it to someone, use it on a web page or stick it into a Word document and print it out.
The downside of screen-grabbing is that you only preserve a digital image of the page. You can’t click on its links to visit connected web pages. You can’t select text or separate out photos. What you see is what you get. A way around this is to save the page, its code and images, intact, on to your hard drive.
Saving Web Pages
You can save a page on most browsers by holding down Control+s when you are on a web page that you want to keep. An options box will appear asking you what you want to call the web page and where you’d like to save it.
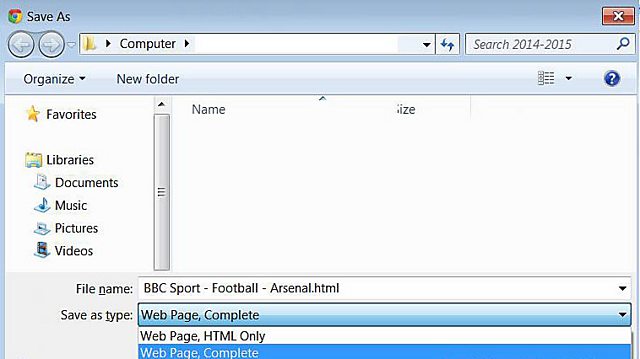
You can save a basic version of the page, with no images and limited functionality, by choosing ‘HTML Only’ as an option. But most people save a page as ‘Complete’. The latter option saves the images and some embedded technical files into a separate folder, allowing you to view and use most of the functions of the live online version.
There are some limitations. You won’t preserve embedded videos or be able to perform searches, but for most purposes this is a perfectly adequate way of saving web-based evidence.
After you have saved a copy of a page, find it on your computer and open it up. If it doesn’t look right, try saving again using a different browser. Internet Explorer allows you to save web pages as a .mht file – like a Word document that renders as a web page when viewed in Internet Explorer. You can also save a page as a PDF document.
Tip: save not only the web page you’re interested in but those connecting to it and those it links to. You may also want to save domain registration information and connected social media account pages.
This post was first published by the BBC Academy and is reproduced here with its kind permission. In part two of this blog Paul Myers looks at ways of saving information from social networks.

Paul Myers is the BBC College of Journalism‘s Internet Research Specialist, where he helps TV & radio programs conduct investigations that involve trickier aspects of online research. He also hosts regular training courses. Blending his previous career as a computer programmer with journalism, Paul pioneered many online research techniques now widely used. You can find more of his work at Research Clinic.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next
Reporting Tools & Tips
How To Save Online Evidence And Why It Matters: Part Two
In part one of this blog I discussed the need for journalists to save evidence they find online and some of the techniques for recording that information. In part two, I’ll focus on some of the issues journalists face when it comes to saving information from social media and mobile devices.

How They Did It
How ProPublica Exposed Ethics Scandals at the US Supreme Court
The Journalist’s Resource talked with ProPublica reporters about their blockbuster series, which revealed behind-the-scenes connections between billionaires and US Supreme Court justices and prompted historic reforms on the nation’s high court.

Data Journalism News & Analysis
Lessons Learned: 10 Common Mistakes in Data Journalism
GIJN asked speakers and attendees in the NICAR conference hallways for the data journalism gaps they see, and for under-covered topic areas and under-used skills that newsrooms can address.

Reporting Tools & Tips Teaching & Training
Best Practices for Election Coverage Using YouTube
At the recent International Symposium on Online Journalism (ISOJ), one workshop offered suggestions on how journalists and media outlets can better use YouTube in their election coverage.