
Information Laundromat — один із найновіших інструментів аналізу сайтів. Зображення: Shutterstock
Information Laundromat: Як працює інструмент для аналізу вмісту та метаданих сайтів



Я люблю досліджувати сайти — написав про це розділ для останнього видання «Посібника з верифікації» й завжди шукаю нові інструменти та методи встановлення зв’язків між сайтами, ідентифікації власників, аналізу вмісту, інфраструктури та поведінки сайтів.
Information Laundromat — один з найновіших безкоштовних інструментів для аналізу вебсайтів, і, мабуть, найцікавіший із тих, з якими мені доводилося стикатися. Альянс за безпеку демократії (ASD) Фонду Джорджа Маршалла розробив цей інструмент для аналізу контенту і метаданих. ASD разом із дослідниками з Амстердамського університету та Інституту стратегічного діалогу використовували його під час підготовки свого звіту «Матрьошка російської пропаганди: як RT вбудовується в цифрове інформаційне середовище».
Information Laundromat може аналізувати два елементи: контент, розміщений на сайті, і метадані, використані для його створення та запуску. Щоб зрозуміти, як він працює, я протестував інструмент і поговорив із його розробником Пітером Бенцоні.
Пітер сказав мені, що Information Laundromat найліпше застосовувати для пошуку зачіпок: «Він не має на меті автоматизувати ваше розслідування». Information Laundromat має відкритий вихідний код і доступний на GitHub-акаунті Альянсу за безпеку демократії.
Аналіз подібності контенту
Зображення: знімок екрана, Digital Investigations
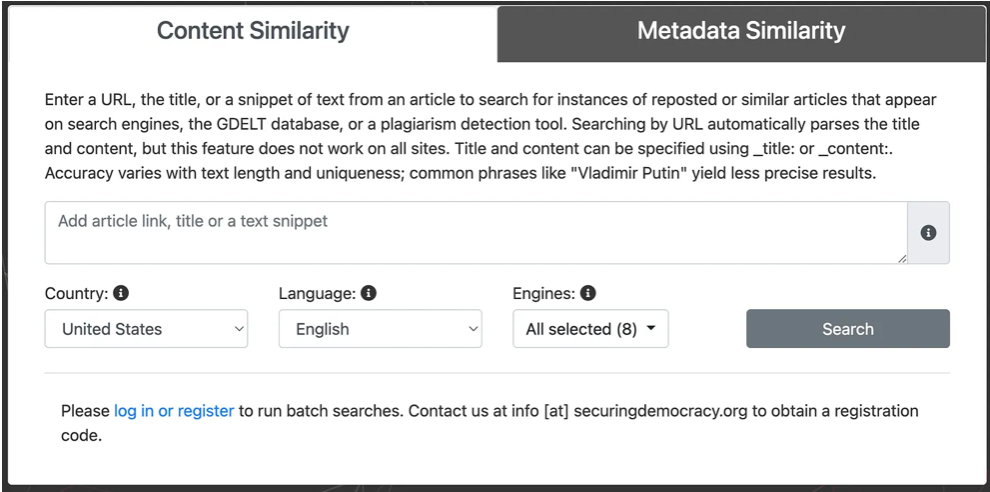
Інструмент аналізує посилання, заголовок або фрагмент тексту, щоб виявити інші вебресурси зі схожим або ідентичним контентом. Він допоміг Альянсу за безпеку демократії в пошуку вебсайтів, які регулярно копіюють матеріали Russia Today (RT). У дослідженні вдалося виявити сайти, які постійно передруковували контент RT і допомагали просувати наративи RT в інтернеті, «відмиваючи» їх.
Як це працює
- Введіть URL-адресу, заголовок або фрагмент тексту, який потрібно перевірити.
- Система використовує пошукові системи, інструмент перевірки на плагіат Copyscape та базу даних GDELT, щоб проаналізувати й оцінити схожість цього контенту з вмістом інших сайтів.
- Сторінка результатів сортує сайти за відсотком вмісту, схожого на ваше першоджерело.
Я запустив вибірковий пошук за URL-адресою, де містилася майже точна копія новини, опублікованої в іншому місці. Information Laundromat правильно визначив першоджерело тексту, вказавши на 97% схожості.
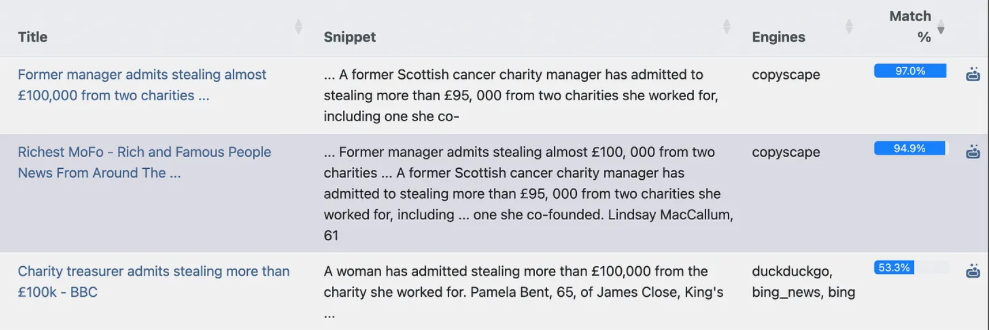
Information Laundromat правильно визначив першоджерело тексту, вказавши на 97% схожості. Зображення: знімок екрану, Digital Investigations
Інструмент також підкреслює, чого він не робить:
Пошук за схожістю вмісту намагається знайти схожі статті або тексти у відкритому доступі. Він не надає доказів походження цього тексту, або будь-яких зв’язків між двома суб’єктами, що опублікували два схожі тексти. Визначення походження певного тексту не входить до завдань цього інструменту.
Якщо під час роботи з інструментом ви отримаєте багато результатів, Пітер радить «завантажити все в Excel і переглянути їх самостійно за допомогою зведеної таблиці».
За словами Пітера, найбільший інтерес представляють сайти з рейтингом схожості 70% або вище. Інструмент також надає можливість пакетного завантаження зареєстрованим користувачам.
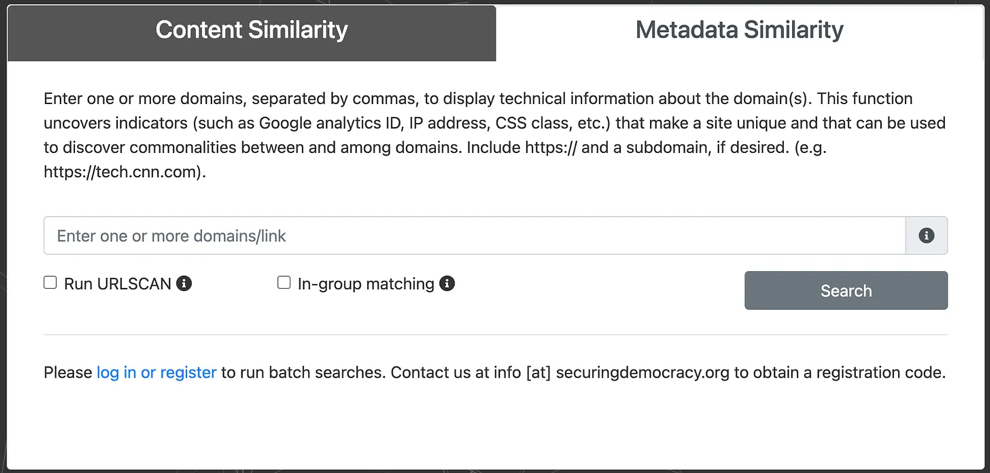
Аналіз подібності метаданих
Зображення: знімок екрана, Digital Investigations
Інструмент схожості метаданих Information Laundromat найкраще працює, коли ви маєте набір сайтів, які хочете проаналізувати. Також можна використовувати його для аналізу одного сайту, але це менш ефективно.
Як це працює
- Введіть набір доменів, які потрібно проаналізувати на наявність спільних зв’язків.
- Інструмент сканує кожен домен, зокрема його інфраструктуру, IP-адресу та вихідний код, щоб виокремити унікальні показники та визначити, чи є збіги між доменами. Він позначає прямі збіги IP-адрес, а також показує, чи розміщені сайти в одному діапазоні IP-адрес (що є слабшим зв’язком, але все ж потенційно вартим уваги). Окрім пошуку унікальних рекламних та аналітичних кодів, інструмент сканує CSS-файл сайту на предмет схожості. Пітер сказав, що «має бути понад 90% схожих класів CSS», щоб інструмент позначив його як вартий уваги. (Повний список індикаторів сайту можна переглянути тут).
- На сторінці метаданих результати сортують за двома розділами:
- перша таблиця містить перелік індикаторів, присутніх на кожному сайті;
- друга таблиця визначає спільні для всіх сайтів індикатори.
- Інструмент також сортує результати в кожній таблиці відповідно до відносної сили кожного індикатора. (Пояснюю детальніше в останньому розділі цієї статті).
«Ідея полягала в тому, щоб спробувати виявити будь-які вказівки на спорідненість сайтів та взаємозв’язки між ними», — сказав мені Пітер.
Якщо ви не знайомі з методом виявлення зв’язків між сайтами за допомогою аналітики та рекламних кодів, ви можете прочитати цей базовий посібник і мій допис (спочатку прочитайте посібник!).
Модуль метаданих Information Laundromat може стати в пригоді, якщо ви знайомі з інфраструктурою вебсайтів, наприклад, з IP-адресами, і якщо ви розумієте, як пов’язувати сайти між собою за допомогою індикаторів. Якщо ви не розумієте відносних сильних і слабких сторін кожного індикатора і зв’язку, тоді використання цього інструменту може бути ризиковане. (Детальніше про це нижче).
Пітер сказав, що інструмент аналізу метаданих є чудовою відправною точкою для пошуку зв’язків між сайтами з певного набору.
«Якщо у вас є набір сайтів, і ви хотіли б отримати уявлення про потенційні повтори, то це хороший спосіб провести швидкий аналіз, щоб не запускати його вручну, застосовуючи купу інших інструментів», — сказав він.
Я згоден, що це потенційно хороша відправна точка, якщо у вас є набір сайтів, які, на вашу думку, можуть бути пов’язані. Information Laundromat дасть вам корисний огляд потенційних зв’язків. Із цими результатами в руках ви можете зануритися глибше, використовуючи такі інструменти, як DNSlytics, BuiltWith, SpyOnWeb і вашу улюблену платформу пасивних DNS.
Хоча інструмент найкраще працює з групою доменів, можна запустити пошук метаданих і за однією URL-адресою. Це корисно, адже система може витягувати, наприклад, коди аналітики для зручного пошуку в таких місцях, як DNSlytics. Ви також можете побачити, чи має URL спільні індикатори з набором із приблизно 10 000 доменів, які зберігаються в базі даних Information Laundromat. Джерела перераховані на сторінці про інструмент.
- База EUvsDisinfo.
- Дослідження партнерських та суміжних організацій, наприклад, звіт Інституту стратегічного діалогу про дзеркальні сайти RT.
- Відомі державні медіасайти.
- Списки ненадійних джерел, сайтів «рожевого слизу» («інфопомийки») та фейкових місцевих новин.
- Список фейкових новинних сайтів з Вікіпедії та список новинних сайтів Wikidata.
Пітер зазначив, що наразі інструмент не додає до бази даних домени, введені користувачем. Тож якщо ви шукаєте за набором доменів, які вважаєте конфіденційними, ви можете втішитися тим, що інструмент не додасть ваш сайт(и) до бази Information Laundromat.
Рейтинг технічних показників сайту
Украй важливо розуміти відносні сильні та слабкі сторони індикаторів сайту, визначених цим інструментом, інакше є ризик переоцінити ступінь зв’язку між сайтами. На щастя, документація Information Laundromat наводить корисну розбивку показників.
Наприклад, це слабкий зв’язок, якщо декілька сайтів використовують систему управління контентом WordPress. Таку систему застостовують сотні мільйонів сайтів, сама по собі вона не є корисним сигналом для виявлення зв’язку між ними. Проте можна говорити про сильний зв’язок між сайтами, якщо всі вони використовують однаковий код Google AdSense.
В ідеалі варто визначити декілька технічних показників, які пов’язують набір сайтів, і об’єднати їх з іншою інформацією, щоб належним чином оцінити ступінь зв’язаності.
Щоб полегшити аналіз, Information Laundromat сортує індикатори за трьома рівнями. На сторінці результатів зручно орієнтуватися за кольоровим кодуванням, воно вкаже на сильні, помірні або слабкі індикатори. Усе одно вам доведеться проводити власний аналіз, але це корисна відправна точка.
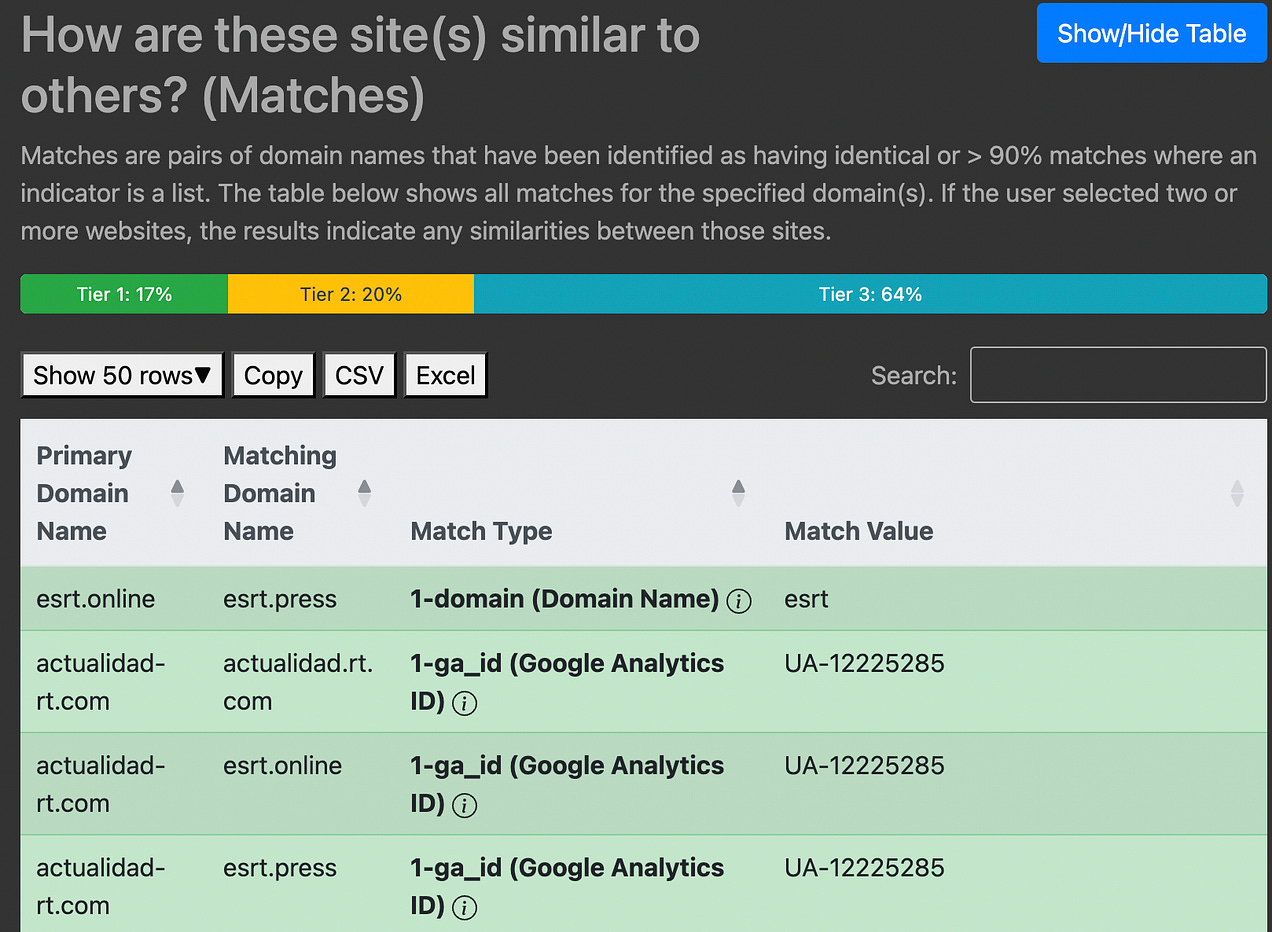
Приклад пошуку метаданих із застосуванням доменів, пов’язаних з RT. Зображення: знімок екрана, Digital Investigations.
Ось три рівні індикаторів з документації Information Laundromat
- Рівень 1: Вони зазвичай є «унікальними або дуже показовими щодо походження вебсайту» й містять «унікальні ідентифікатори для верифікації та вебсервісів, таких як Google, Яндекс тощо, а також метадані сайту, такі як інформація WHOIS та сертифікаты».
- Рівень 2: Такі індикатори «пропонують помірний рівень впевненості щодо походження вебсайту». Вони «надають цінний контекст» і включають «IP-адреси в одній підмережі, однакові метатеги та спільні риси в стандартних і спеціальних заголовках відповідей».
- Рівень 3: На ці індикатори варто орієнтуватися в поєднанні з індикаторами вищого рівня. Рівень 3 включає «спільні класи CSS, UUID та систем управління контентом».
Примітка редактора: Цю статтю Крейг Сільверман спершу опублікував на своєму сайті «Цифрові розслідування», й ми передруковуємо та перекладаємо її з його дозволу.
 Крейг Сільверман — національний репортер ProPublica, який висвітлює голосування, платформи, дезінформацію та маніпуляції в інтернеті. Раніше працював редактором медійного напряму в BuzzFeed News, де започаткував розслідування цифрової дезінформації.
Крейг Сільверман — національний репортер ProPublica, який висвітлює голосування, платформи, дезінформацію та маніпуляції в інтернеті. Раніше працював редактором медійного напряму в BuzzFeed News, де започаткував розслідування цифрової дезінформації.

Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Читати далі

Поради та інструменти
ChatGPT як інструмент для прискорення пошуку: Поради розслідувачам
Про ефективний пошук контактів та швидкий аналіз документів за допомогою ШІ розповів доповідач IRE24 Джеремі Джоджола – журналіст-розслідувач KUSA-TV.

Поради Путівник Методологія Поради та інструменти
Як перетворити нечитабельний текст на доказ: Поради Хенка ван Есса
Треба розшифрувати числа зі скриншоту, прочитати спотворені рядки в документах чи визначити геолокацію лише за фрагментом тексту на фото? Інтернет-дослідник Хенк ван Есс розповідає, як безкоштовні онлайн-інструменти можуть допомогти перетворити фрагменти даних на переконливі докази.

Поради та інструменти
Інструментарій GIJN: спробуйте нові безкоштовні інструменти для онлайн-розслідувань
Передові й безплатні онлайн-інструменти для перевірки фактів і зображеннь, захисту від шкідливого програмного забезпечення, та підготовки інформаційних довідок на задану тему, якими ділилися з учасниками конференції NICAR 2024 року.

Поради Путівник Ресурс Розділ
Найновіші інструменти для розслідувань в Telegram
Журналістка-розслідувачка й дослідниця дезінформації Джейн Литвиненко пропонує досконало опанувати навички пошуку та аналізу даних у Telegram, використовуючи постійно оновлюваний список інструментів і пошукових систем.