
Як перетворити нечитабельний текст на доказ: Поради Хенка ван Есса
Read this article in
Вам знайоме відчуття, коли дивишся на ключовий доказ — розмитий номерний знак, пікселізований документ із нерозбірливими іменами чи зернистий скриншот, що приховує важливу інформацію за щільною вуаллю пікселів?
Якщо ви такого не відчували — вам поталанило. У своїх розслідуваннях я постійно стикаюся з цією проблемою: треба витягти текст із відео, розшифрувати числа зі скриншоту в соцмережах або прочитати спотворені рядки в документах. Поки всі навколо живуть своє життя, я граю в гру «вгадай піксель». Проте не скаржуся: спроможність перетворювати нерозбірливі символи на зрозумілу інформацію — неймовірна.
Настав час створити посібник із перетворення розмитої нісенітниці на щось осмислене. Інструменти та методи, описані в цій статті, — не з теорії, а з практики. Це дієві прийоми, які можна застосовувати до власноруч знайдених нечитабельних доказів. В OSINT часто саме ті кілька пікселів дають можливість вийти з глухого кута та зробити прорив.
Справжня робота відбувається у вас у голові. Її суть — розуміти, які інструменти поєднати, як перевірити результати й коли варто (а коли — ні) їм довіряти. Адже, зрештою, різниця між аматором і професійним розслідувачем полягає в наявності системи, яка працює завжди — навіть, коли пікселі опираються.
Розмитий номерний знак
Ті, хто проводить розслідування на основі відкритих джерел, мають свої улюблені інструменти. Попросіть у будь-якого фахівця поради — і він скаже: «Просто використовуй Topaz Gigapixel Pro» або «Спробуй будь-який інструмент Neural Single Image Deblurring на основі Gyro» — ось перелік цих інструментів. Проте рішення далеко не завжди знаходиться у вашому улюбленому додатку. Часто воно полягає в тому, щоб визнати: вам відомо не все.
Під час сесії у Лондоні я показав цей розмитий номерний знак 50 працівникам BBC Verify. Більшість із них могли без проблем назвати три інструменти, які мали б допомогти відновити різкість зображення. Справа у тому, що всі вони виявилися неефективними. Які варіанти лишилися у вас тепер?

Розмитий номерний знак. Фото надане Хенком ван Ессом.
Мій улюблений прийом у 2025 році — завантажити свої провальні спроби в чат-бот, ніби це цифрова терапевтична сесія: «Я пробував Topaz, Remini, DeblurGAN v2, ImageJ+ DeconvolutionLab2». Потім спостерігаю, як чат-бот пропонує мені спробувати «BeFunky Image Editor». Серйозно? До цього я жодного разу не чув про BeFunky. Проте цей безкоштовний інструмент з назвою, яка більше нагадує відкинутий «Нетфліксом» фільм, виявився кращим, ніж просунуте програмне забезпечення за 200 баксів. У цей момент я відчуваю максимальну розгубленість: «Мабуть, я знаю не все». І, чесно кажучи, саме у такі моменти відбуваються справжні прориви.

Зображення надане Хенком ван Ессом
Цей інструмент відтоді жодного разу не давав таких добрих результатів, проте коли я включив його до переліку інструментів, які вже випробував, то отримав нові рекомендації. Часом, коли ділишся своїми невдачами, отримуєш найцінніші поради.
Коли вдалося прочитати текст, потрібно знайти контекст. Коли я досліджував номерний знак червоного Chevrolet Camaro, на якому їздив нідердандський злочинець, у мене не було проблем із прочитанням цифр — вони виникли зі зворотним пошуком зображень. Іноді Google просто не розпізнає обрізану деталь фотографії.

Іноді Google просто не розпізнає обрізану деталь фотографії. Світлина надана Хенком ван Ессом.
Цю проблему можна вирішити: замість зворотного пошуку фотографії у Google Images, введіть у пошуковий рядок видиму частину тексту й здійсніть пошук за фото. У результаті я отримав фотографії туристів у Ірані, які їздили на тому ж червоному Chevrolet Camaro. Як виявилося, злочинець брав машину в оренду (читайте історію повністю тут).

Червоне авто допомогло знайти злочинця. Фото надане Хенком ван Ессом.
Відкритий ноутбук
Ловіть професійну пораду, яка звучить практично неправдоподібно: якщо ваш текст не повністю безнадійний, просто попросіть ШІ прочитати його для вас. Ніяких модних інструментів, ніякої магічної обробки зображень — просто завантажте його у чат-бот і запитайте: «Що тут написано?» Зараз мій фаворит — Gemini Pro 2.5, який, мабуть, вирішив стати найкваліфікованішим коректором у світі.
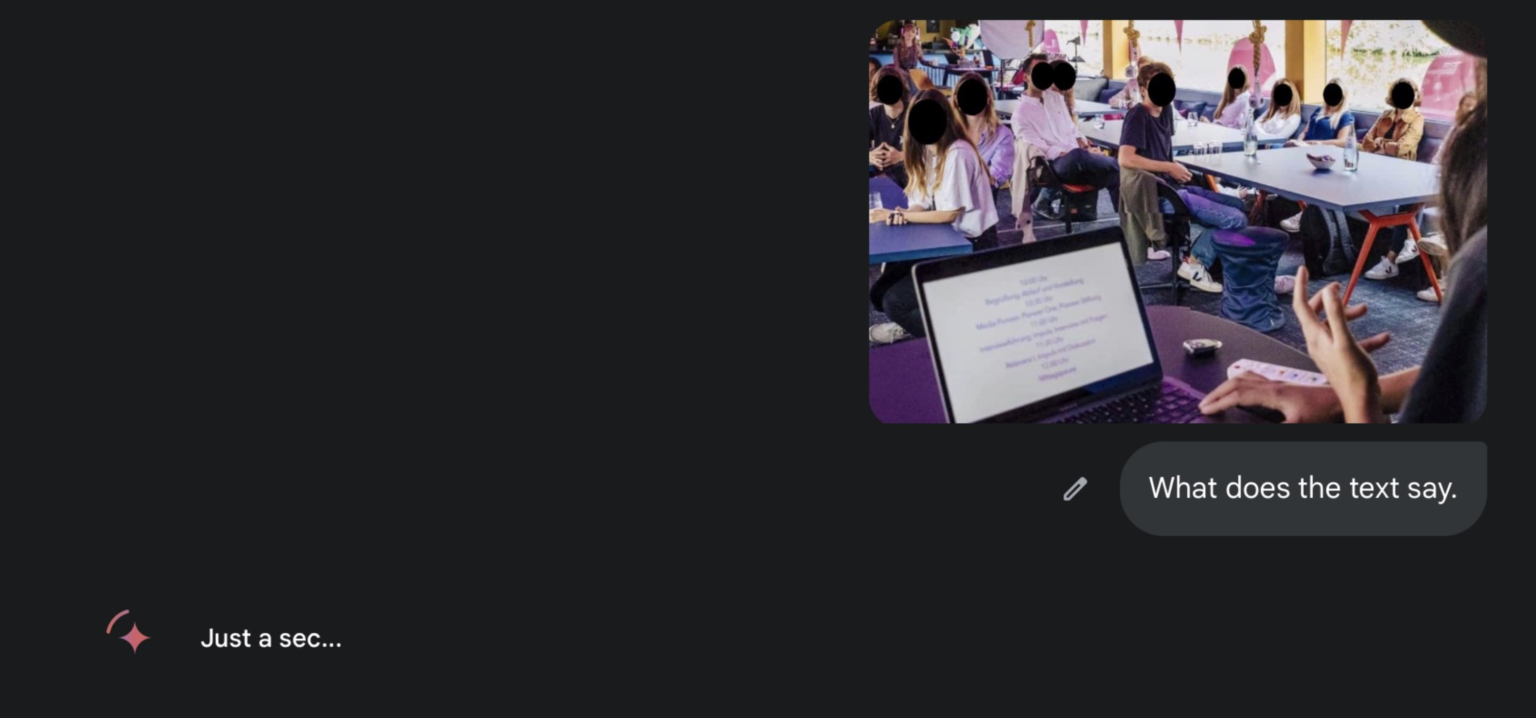
Що написано на моніторі комп’ютера. Фото надане Хенком ван Ессом.
Поки ви мружитеся у спробах розібрати це «а» чи сумний смайлик, чат-бот вже розшифрував і переклав нечитабельний текст:
Фото надане Хенком ван Ессом.
170 нечитабельних слів
Подивіться на цю фотографію. Я багато подорожую, тож не можу возити за собою монітори. Натомість для роботи я використовую окуляри віртуальної реальності. Скільки слів ви можете розібрати на цьому скриншоті, який я навмисне по максимуму розмив?
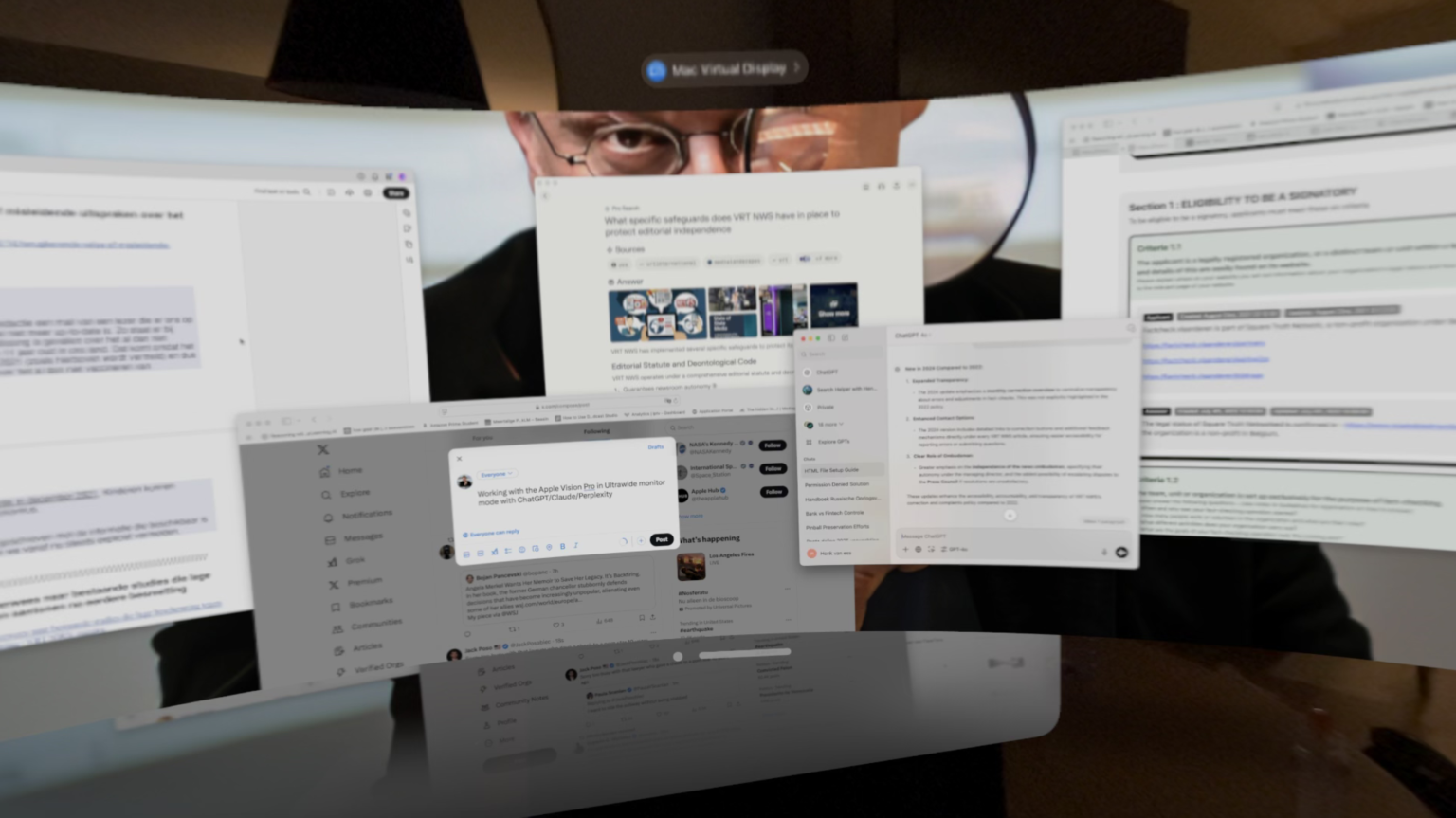
Окуляри віртуальної реальності. Фото надане Хенком ван Ессом.
Поки ви продовжуєте мружитися, я завантажив зображення у Gemini 2.5 Pro. Він зміг прочитати близько 170 слів із фото та точно резюмував те, чим я займався.
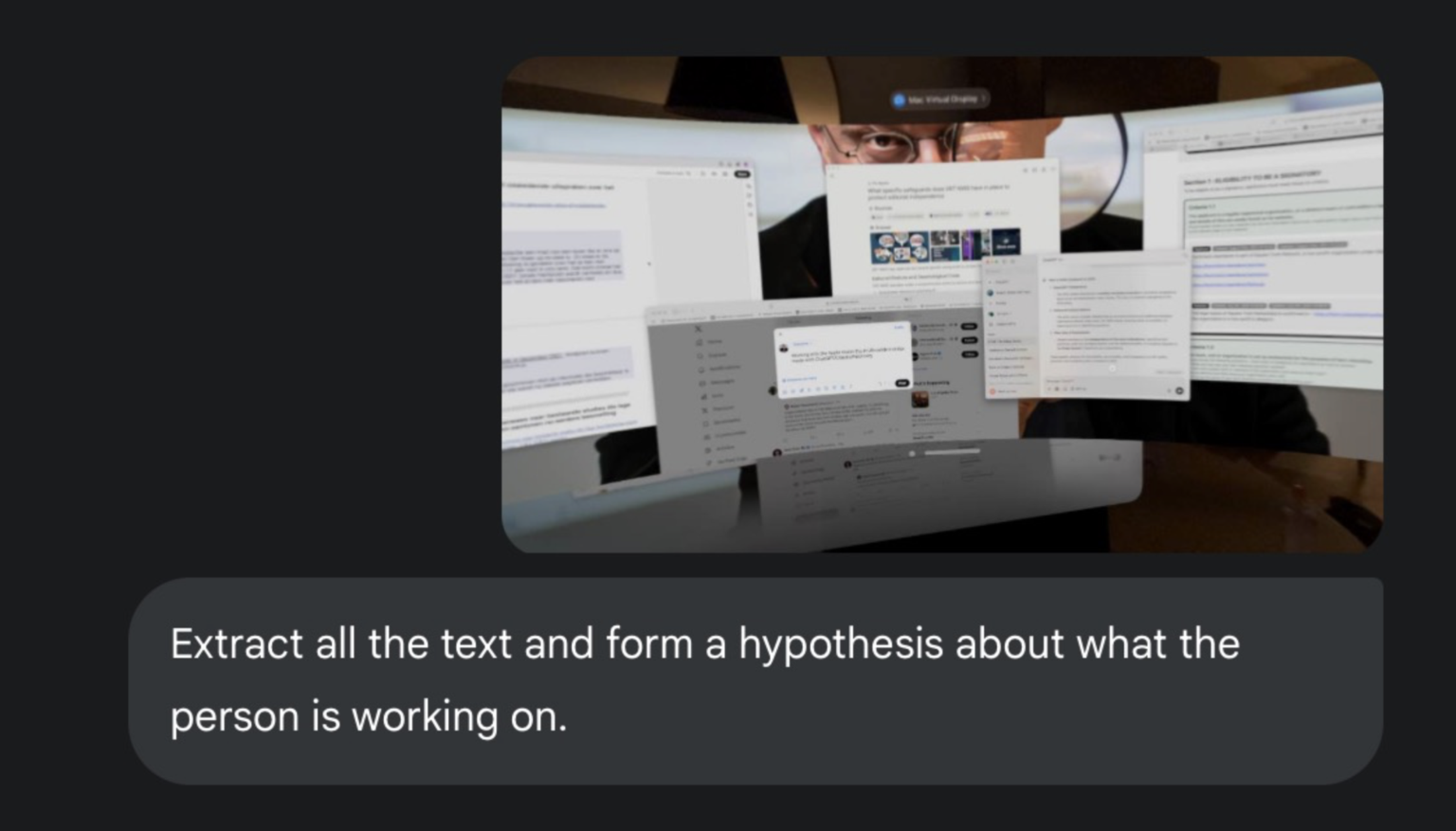

Розшифровка тексту, що не читається. Фото надане Хенком ван Ессом.
Геолокація за допомогою тексту
Нещодавно я два тижні працював у Берліні. Мені подобається проводити короткі вступні лекції з OSINT для студентів — вони чудово демонструють, наскільки ефективними можуть бути методи онлайн-розслідувань. Це пізнавально, трохи лякає й гарантовано змушує кожного негайно перевірити налаштування приватності.
Давайте проаналізуємо цю фотографію. Запитання: «Де і коли вона зроблена?»

Геолокація за допомогою тексту. Фото надане Хенком ван Ессом.
Завдяки знаку «Паркування велосипедів заборонено» зрозуміло, що можна виключити Мальту, Кіпр, Іспанію, Люксембург та Велику Британію. Це робить Нідерланди, Данію та Фінляндію — найімовірнішими кандидатами. Пояснення просте: знак «Паркування велосипедів заборонено» поширений у країнах, де всі їздять на велосипедах. Такі знаки навряд чи встановлюватимуть там, де велосипедистів майже немає. Вони потрібні в місцях, де їх так багато, що доводиться постійно нагадувати: тут паркуватися не можна. Це ніби ви побачили знак «Купання заборонено» на пляжі, а не посеред Сахари. У першому випадку це турбота про громадську безпеку, у другому — міраж. Ви бачите текст, який з’являється двічі — слово «essen» або закінчуються на «essen», — і зелений логотип з кількома словами на ньому. У цьому випадку ШІ впорався з розшифровкою не краще за нас:
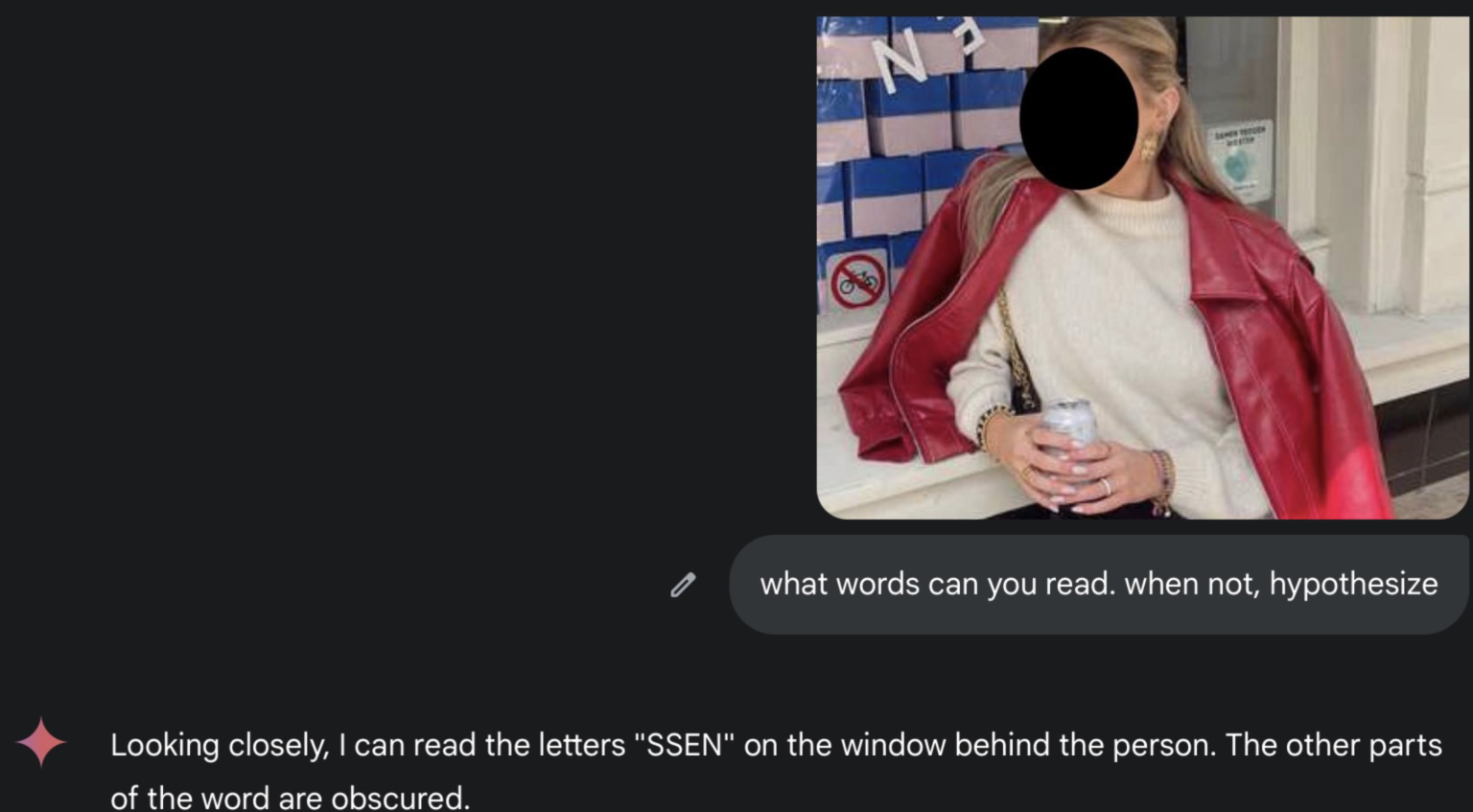
Тут ШІ не впорався з розшифровкою нечіткого тексту. Фото надане Хенком ван Ессом.
Чи зможе BeFunky знову допомогти? Він покращив якість тексту настільки, що я зміг прочитати слова «samen redden». Це означає, що текст написаний нідерландською мовою, і йдеться про «samen redden [щось]». У перекладі — «разом збережемо [щось]».

Розшифровка тексту, що не читається. Фото надане Хенком ван Ессом.
Що потрібно зберегти? Це наклейка на вікні магазину чи ресторану, тож там навряд чи буде написано «разом зберегти… комунізм». Можливо, там написано «разом зберегти… капіталізм»?
Ні, забудьте, це занадто. Напевно, там написано щось мотивуюче, наприклад, «разом зберегти… енергію» чи «разом зберегти… китів», чи «разом заощадити… на парковці». Або, можливо… Зачекайте, здається, я знову мудрую. Не треба вигадувати. Почніть шукати.
Ми можемо припустити, що після «разом зберегти» стоїть одне або два слова — ймовірно, не більше семи символів, якщо розмір шрифту такий самий, як у першому рядку. Тепер найцікавіше: яким чином пояснити Google цю неймовірно специфічну оцінку кількості слів, засновану на аналізі шрифту, щоб не звучати при цьому як конспіролог, який випив забагато кави? У цьому місці звичайні пошукові запити перетинаються із судовою-медичною типографікою (ми поговоримо про це у другій частині статті) — і одразу виникають сумніви щодо правильності вибору професії.
Як сказати Google, що ви не знаєте правильних слів?
Замініть невідомі елементи зірочкою:

Ілюстрація надана Хенком ван Ессом.
Навіщо використовувати лапки? Без них Google вирішить, що ви шукаєте слова «samen» і «redden» у будь-якому порядку, тим часом вам потрібно, щоб вони стояли поруч. Лапки змушують Google шукати саме цю фразу, а не окремі слова, що розкидані по різних абзацах, наче лінгвістичне конфетті. І найважливіше: коли ви додаєте зірочку в кінці, ви кажете Google: «Після цих слів текст продовжується, не показуй мені результати, де на цьому місці фраза закінчується».
По суті це означає: «Ні, я правда маю на увазі, що ці два слова стоять поруч, і я знаю, що текст на цьому не закінчується». Ось результат:
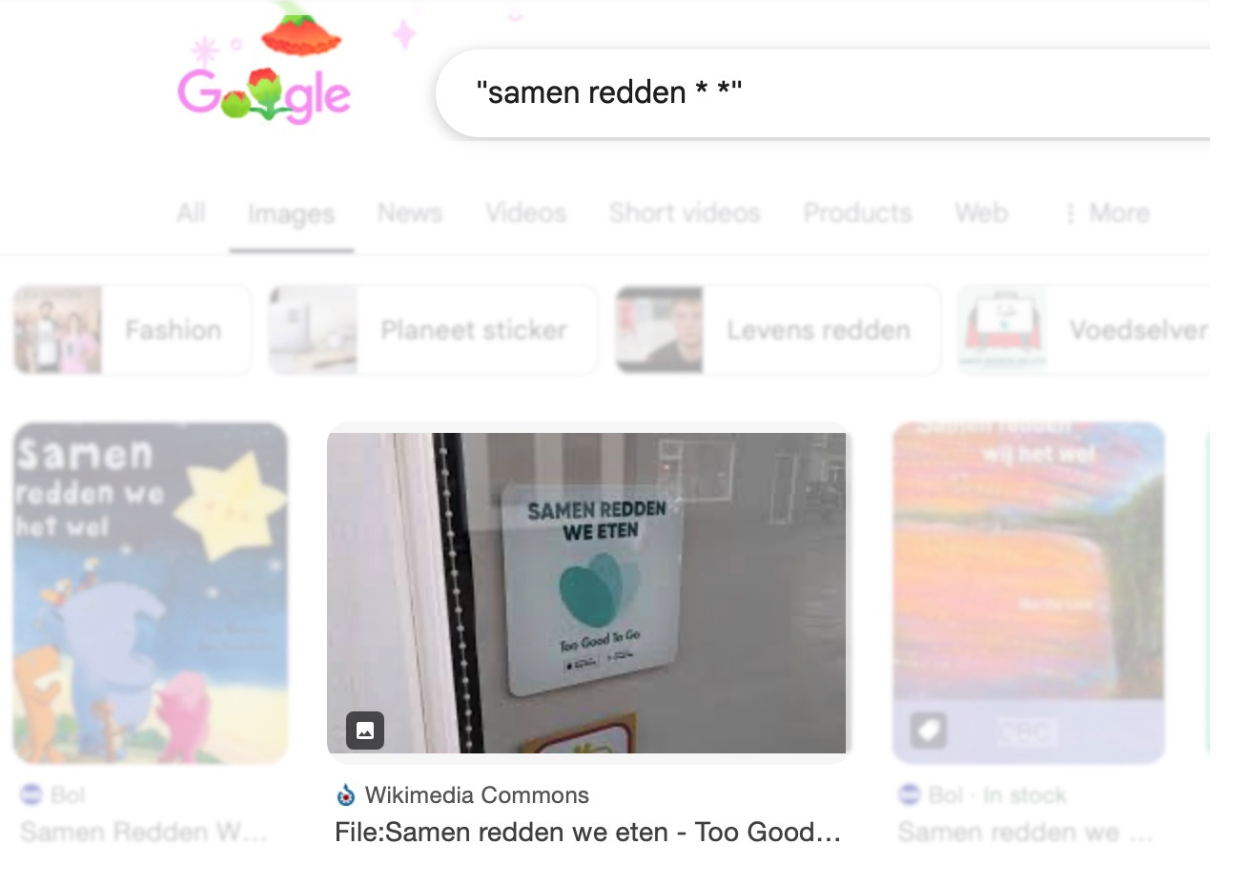
Ілюстрація надана Хенком ван Ессом.
Виявилося, що це «samen redden we eten» — слоган програми Too Good To Go.
Перш ніж рухатися далі, варто пояснити, чому ми скористалися саме Google Images.
Звичайний пошук у Google складніший, адже він покладається на обробку природної мови. А Google Images ніби каже: «О, ти шукаєш текст на зображеннях? У мене їх мільйони — я покажу тобі ті, де ці слова стоять поруч, навіть такі, про існування яких ти не підозрював».
Різниця приблизно така, як між проханням до бібліотекаря знайти книжки про «спільний порятунок їжі» і показати кожне фото, де є саме ці слова. У першому випадку ви отримаєте статті й аналітичні матеріали, у другому — справжні вітрини магазинів і плакати компаній. Наприклад, ось чудовий новий інструмент, який показує всі написи у режимі StreetView у Нью-Йорку:
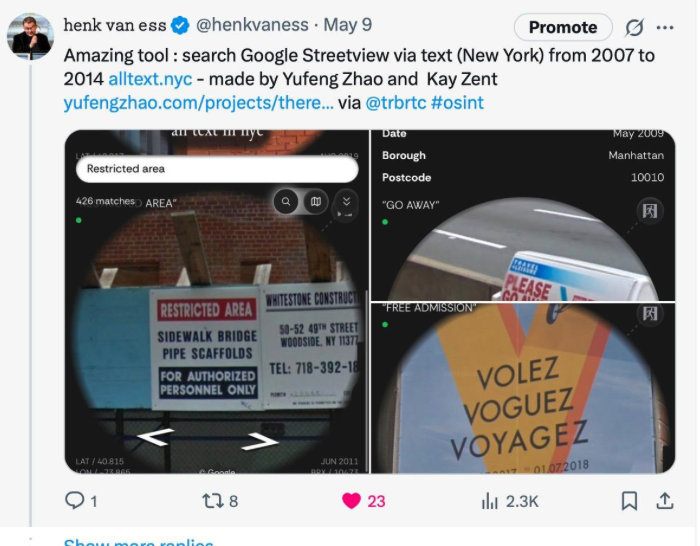
Ілюстрація надана Хенком ван Ессом.
Повернімося до нашої справи. Too Good to Go — це, по суті, додаток знайомств із овочами та випічкою, в якому ресторани, магазини та кафе виставляють свою непродану їжу, щоб врятувати її в останній момент.

Ілюстрація надана Хенком ван Ессом.
Настав час досліджувати літери «ESSEN». Наступна зупинка — Claude, семантичний аналізатор.
Я дав йому конкретику — нідерландські слова на вікнах ресторанів або магазинів, що закінчуються на «essen» — і він миттєво видав «Delicatessen». Звичайно. Поки я грав у детектива, рішення полягало в тому, щоб просто запитати ШІ, який спеціалізується на мовних патернах.

Ілюстрація надана Хенком ван Ессом.
Іноді найпростіший підхід — просто визнати, що потрібен кращий мозок, ніж ваш власний, особливо, якщо він володіє нідерландською.
Я завантажив програму Too Good to Go і почав шукати delicatessen. Дива не сталося. Claude пояснив, чому:
Ілюстрація надана Хенком ван Ессом.
Більшість об’єктів знаходяться в Амстердамі, тому я почав звідти. На вікні стоять біло-сині коробки.

Ілюстрація надана Хенком ван Ессом.

Ілюстрація надана Хенком ван Ессом.
Тримайте маленький цікавий прийом, про який вам ніхто не розповість: якщо розслідування залежить від конкретних кольорів, просто додайте їх наприкінці пошуку в Google Images.
Це як додати посипку до морозива — тільки посипка тут криміналістичні докази, а морозиво — пошук у Google. Несподівано запит «Delicatessen Amsterdam white blue» стає неймовірно точним: він оминає всі загальні списки ресторанів і веде просто до потрібних магазинів — тих самих, з кольоровими коробками на підвіконні. Хто б подумав, що кольори можуть бути параметром пошуку? І водночас це очевидно до геніальності.
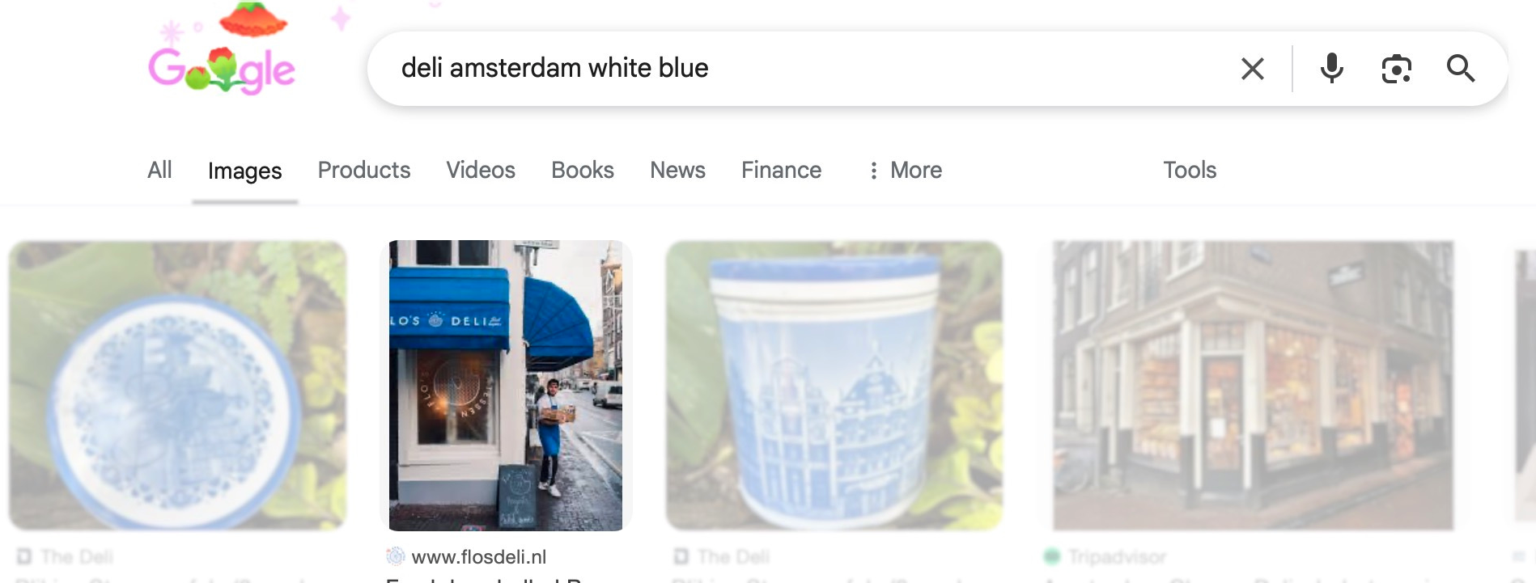
Ілюстрація надана Хенком ван Ессом.
Наш перший кандидат — магазин Flo’s Deli в Амстердамі.

Ілюстрація надана Хенком ван Ессом.
І, уявіть собі, це точний збіг із першої спроби.
Ми натрапили на OSINT-еквівалент виграшу в лотерею з першого квитка. Бачите, ліворуч — наша відправна точка: невідома людина у червоній куртці, яка сидить біля магазину, що може знаходитися будь-де в Європі. Обличчя дбайливо заблюрене — мабуть, приватність усе ще має значення. Нам залишилося відпрацювати лише знак «парковка велосипедів заборонена» та незрозумілі кольорові візерунки, які можуть виявитися чим завгодно — від реклами барбершопа до незвичайної дошки для гри в хрестики-нулики.
Праворуч показаний кульмінаційний момент: магазин Flo’s Deli з написом «samen redden we eten», на якому ми так надовго зациклилися, з такою ж купою біло-синіх коробок і знаком «парковка велосипедів заборонена», який гордо майорить там, ніби каже: «Так, це саме те місце!»
Пометушившись між різними інструментами аналізу на основі ШІ, наче м’ячик для цифрового пінболу, ми з їхньою допомогою з’ясували: так, це фото, ймовірно, зробили навесні або восени (дякуємо роботам за чудову роботу з визначення сезону). І на цьому — за допомогою перевіреного класичного інструменту з арсеналу OSINT, машини часу Google Maps, — ми завершуємо першу частину квеста «Як перетворити нечитабельний текст на докази».

Ілюстрація надана Хенком ван Ессом.
У травні 2022 року цей магазин ще не відкрився. Тому на знімку час між травнем 2022 року та сьогоднішнім днем, правильно?

Ілюстрація надана Хенком ван Ессом.
Якщо у вас багато часу й цікавішого заняття немає, ви можете навіть з’ясувати точний час — для цього треба переглянути тисячі фотографій цього магазину, зроблених туристами. Це цілком нормальний спосіб витратити пів дня.
Що за синьо-білі коробки? Там рогалики.

Ілюстрація надана Хенком ван Ессом.
У масштабах великого розслідування це відкриття таке ж сенсаційне, як те, що лід — холодний. Але ось прекрасна у своїй безглуздій логіці деталь: проаналізувавши інші контекстні фото та простеживши сезонне підняття й опускання рівня коробок із рогаликами, можна досить точно визначити, що знімок зробили восени 2024 року.
Отже, що ми дізналися? Що іноді «просунуті» техніки криміналістичного аналізу означають просто попросити чат-бота на основі ШІ про допомогу, що інструмент за 200 доларів може поступитися редактору під назвою BeFunky, й що тепер аналіз зменшення та збільшення споживання рогаликів в Амстердамі — серйозна детективна робота.
А ось уже справжній висновок: секрет перетворення нечитабельного тексту на доказ — не в одному інструменті. Тут важлива система: ретельно вивчайте кожну деталь, комбінуйте різні підходи, визнайте, коли ви застрягли, та просіть допомоги (навіть у ШІ).
Наступного разу ми продемонструємо більше прийомів Тіммі Аллена з команди Bellingcat на прикладі нашого розслідування китайської кредитної картки. Зокрема покажемо, як розгадувати фінансові загадки за допомогою сильно розмитого відео. Адже, схоже, саме цим може заповнити типову неділю сучасний фахівець із цифрової криміналістики.
Примітка: Ця стаття вперше з’явилася у виданні Digital Digging, інформаційному бюлетені Хенка ван Есса на платформі Substack. GIJN злегка відредагували й передрукували її з дозволу автора.
Цю статтю переклала за допомогою інструментів ШІ та відредагувала асистентка регіонального редактора GIJN Тетяна Колісник.
 Хенк ван Есс — нідерландський фахівець із розслідувань на основі відкритих джерел, викладач і тренер із багаторічним досвідом. Він навчає методам проведення інтернет-досліджень, пошуку та верифікації інформації у соцмережах. Як популярний лектор, Хенк об’їздив Європу з семінарами з OSINT. Серед його проєктів — «Цифрове розслідування» (штучний інтелект та дослідження), «Перевірка фактів в Інтернеті», «Довідник з журналістики даних», який доступний для безкоштовного завантаження.
Хенк ван Есс — нідерландський фахівець із розслідувань на основі відкритих джерел, викладач і тренер із багаторічним досвідом. Він навчає методам проведення інтернет-досліджень, пошуку та верифікації інформації у соцмережах. Як популярний лектор, Хенк об’їздив Європу з семінарами з OSINT. Серед його проєктів — «Цифрове розслідування» (штучний інтелект та дослідження), «Перевірка фактів в Інтернеті», «Довідник з журналістики даних», який доступний для безкоштовного завантаження.

Покроковий посібник для журналістів з основ роботи в Google Таблицях

Посібник журналіста з розслідування кіберзагроз

Посібник журналіста з розслідування організованої злочинності

Посібник із розслідувань з використанням бібліотек цифрової реклами

ChatGPT як інструмент для прискорення пошуку: Поради розслідувачам

Інструментарій GIJN: спробуйте нові безкоштовні інструменти для онлайн-розслідувань

Найновіші інструменти для розслідувань в Telegram

Нові інструменти на базі ШІ та великих мовних моделей для журналістів: що треба знати

Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
Цей твір захищений ліцензією Міжнародна ліцензія Creative Commons Attribution-NoDerivatives 4.0
Читати далі
Поради та інструменти
ChatGPT як інструмент для прискорення пошуку: Поради розслідувачам
Про ефективний пошук контактів та швидкий аналіз документів за допомогою ШІ розповів доповідач IRE24 Джеремі Джоджола – журналіст-розслідувач KUSA-TV.
Поради та інструменти
Інструментарій GIJN: спробуйте нові безкоштовні інструменти для онлайн-розслідувань
Передові й безплатні онлайн-інструменти для перевірки фактів і зображеннь, захисту від шкідливого програмного забезпечення, та підготовки інформаційних довідок на задану тему, якими ділилися з учасниками конференції NICAR 2024 року.
Ресурс Поради Путівник Розділ
Найновіші інструменти для розслідувань в Telegram
Журналістка-розслідувачка й дослідниця дезінформації Джейн Литвиненко пропонує досконало опанувати навички пошуку та аналізу даних у Telegram, використовуючи постійно оновлюваний список інструментів і пошукових систем.
Поради та інструменти
Нові інструменти на базі ШІ та великих мовних моделей для журналістів: що треба знати
Доповідачі NICAR-2024 року розповіли, які чат-боти на базі великих мовних моделей і нішеві інструменти ШІ допомогли їхнім розслідуванням — особливо в питаннях роботи з кодом і отримання інформації з розрізнених джерел.