How Machine Learning Can (And Can’t) Help Journalists




Kevin Wall, a visual journalist at The Boston Globe, is just beginning to use machine learning in his reporting. But the large amounts of data he needs to leverage this kind of artificial intelligence isn’t always easy to find.
“We need a lot of data for machine learning and deep learning, so it can be tough because you will need teams of people to get [that] amount of data,” he says.
Like Wall, the journalism industry is still scratching the surface of these cutting-edge data science tools. There are only a handful of projects out there – such as the search for surveillance aircraft by BuzzFeed News, the analysis of the misclassification of serious assaults by The Los Angeles Times and image recognition of members of Congress by The New York Times.
“For now, journalists and the media industry as a whole are recognizing that AI and [machine learning] can benefit them, but it also represents this drastic shift from what otherwise has been a very stable industry for the last couple hundred years,” says Alex Siegman, an AI technical program manager at Dow Jones. “This is something that’s still very new, and a lot of newsrooms are exploring what it means for them and how they can derive benefits from it.”
What Is Machine Learning?
Simply put, machine learning is when a computer model is trained with a “teaching set” of data to identify patterns, insights and predictions substantially faster and more effectively than a human being. An example of this is training a model on a large set of cat and dog images and then asking the model to distinguish between pictures of cats and dogs with a high level of accuracy.
As Siegman puts it, machine learning is “finding patterns in large amounts of data and making predictions based on historical data.” There are two aspects to using machine learning in journalism: as part of investigative reporting, or as a day-to-day tool to make journalists’ lives easier.
Machine Learning for Investigative Reporting
“There are probably relatively few circumstances under which reporters are going to need … to acquire machine learning – it’s really where you’ve got a classification task,” says Peter Aldhous, a reporter on the science desk at BuzzFeed News.
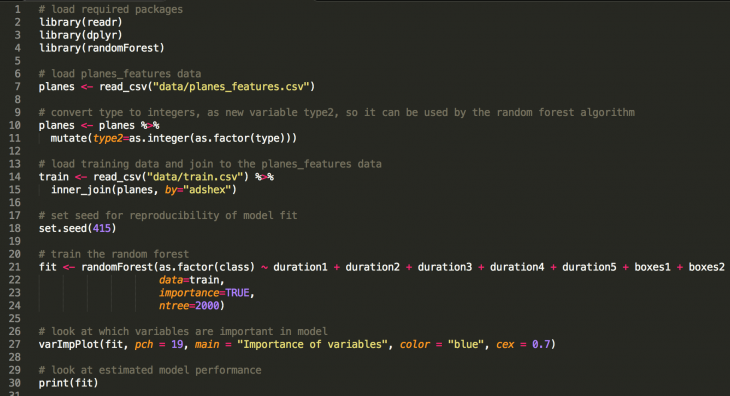
Aldhous is behind Hidden Spy Planes, an investigative project for which he used machine learning – specifically a “random forest” algorithm described here – to identify out of a massive amount of airplane flight data which ones might be covert spy planes. The project won a 2018 Data Journalism Award for innovation in data journalism.

Some findings from Peter Aldhous’s spy planes investigation. Photo: Peter Aldhous.
Aldhous says his plane project was a rare case in which machine learning was actually a good fit, because there was a large enough data set to train the model. “I had very good data on these aircraft, and a lot of it,” he says.
Aldhous successfully acquired four months of flight data from more than 100 known government aircraft. From that, he was able to build a model which could flag planes that might have been surveillance aircraft based on “their turning rates, speeds and altitudes flown, the areas of rectangles drawn around each flight path and the flights’ durations.”
But Aldhous warns that there is danger of data reporters getting too excited about this shining new tool. He says Rachel Shorey, a software engineer in the interactive news department of The New York Times, summarized this sentiment well at the National Institute for Computer-Assisted Reporting (NICAR) conference last year: Sometimes, simple things like a keyword alert or standard statistical sampling techniques might just do as good of a job in an even shorter amount of time.

A slide from Rachel Shorey’s 2018 NICAR talk.
“We need to use the right tool for the right job,” says Aldhous. “[For much of what we do], we don’t need machine learning; we need good data reporting.”
Although the need for machine learning in the newsroom is relatively rare, Shorey pointed out what actually happens when journalists implement this technology in their reporting. The process is “much more haphazard than is desirable,” Shorey wrote in an email. First, reporters find a good library in their favorite programming language; second, they read the documentation; third, they confirm that the methods are a good approach and they understand the inputs and outputs (even if not all the underlying math); fourth, they spend days to weeks cleaning data; and last, they write about 10 lines of code to execute the machine learning process.
Machine Learning as a Day-To-Day Tool
“There’s a lot to what journalists have to do,” says Siegman at Dow Jones. “If you can use technology or machine learning to automate or even semi-automate any part of that, that is a great benefit to journalists.”
Machine learning can help journalists with their day-to-day tasks, such as finding stories, doing photography and videography work, or editing and publishing their work on social media, he says. This can be done through little things, such as automatically transcribing recordings, using image recognition to identify someone in a photo and captioning videos; or through a larger task, such as finding specific information that’s beneficial from a huge influx of content from sources such as social media.
Siegman thinks machine learning or artificial intelligence is nothing more than just a tool. Ten or 20 years from now, he says, people will think about machine learning just like how we think about Microsoft Excel today: “It’s [just] a tool that we are using to perform certain job functions.”
The Ethics of Machine Learning in Journalism
“I would not be happy, in journalism, using black box machine learning methods [where] I don’t know what they are doing,” says Aldhous, referring to the critique that many algorithms lack transparency in how they are designed and trained.
Aldhous says transparency is crucial in journalism – reporters should be able to explain what they did. And at the same time, readers should be able to repeat what reporters did.
Algorithmic accountability is also vital. “One of the most important things journalists need to be doing is actually doing watchdog reporting on how machine learning algorithms are being used by companies and by government,” says Aldhous.
Aldhous thinks watchdog reporting around those issues is even more important than journalists using the algorithms themselves. He says there is a “potential for bias in any algorithmic decision.”
This can happen when a training set includes societal bias that machine learning picks up on, says Carlos Scheidegger, a computer scientist from the University of Arizona.
“There’s very little you can do to validate your results if there’s a problem with the way that a classifier you are using worked,” he says.
Both Siegman and Aldhous mentioned an example of how Amazon used an algorithm that was biased against women as their recruitment tool. The system was trained on data over a 10-year period submitted by mostly male applicants. It then started penalizing resumes that included the word “women.”
“The bias precipitated through the algorithm, and into the real world,” says Siegman.
Siegman thinks privacy concerns are also alarming. “To use any machine learning, you need lots and lots of data,” he says. “And there are privacy concerns around how you are collecting that data from users.”
The Future of Machine Learning in Journalism
Aldhous thinks there is a future in machine learning, but more on the publishing side – such as how to organize, distribute, share and display content to attract more readers.
“But as time goes on, we will get a better idea of when it’s the right tool for the job, and when it just overkills or is not necessary,” he says.
Siegman agrees. “Don’t think about where we can use AI,” he says. “Think about what problems you are facing on a day-to-day [basis], and then evaluate whether or not AI might be a possible solution to that.”
This post originally appeared on Storybench and is reproduced here with permission.
 Floris Wu is a graduate student at Northeastern’s School of Journalism, where she studies journalism with a focus on data science. She is a regular contributor to Storybench.
Floris Wu is a graduate student at Northeastern’s School of Journalism, where she studies journalism with a focus on data science. She is a regular contributor to Storybench.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next

Data Journalism Top 10 Editor's Picks News & Analysis
Editor’s Pick: Top 10 Data Journalism Projects of 2024
Highlights from a year of data journalism columns, from elections to the Olympics and the evolution of the love song.

Data Journalism LATAM Focus News & Analysis
‘Shining a Light Where There Are Shadows’: Latin American Outlets Innovating With Data
Data journalism is helping outlets across the region carry out innovative projects that reveal the stories hidden in large volumes of data.

News & Analysis
Why Investigative Journalists Should Report on Lax Oversight and Fraud in Research Data
Uri Simonsohn, a behavioral scientist who coauthors the Data Colada blog, urges reporters to ask researchers about preregistration and expose opportunities for academic fraud.

Data Journalism News & Analysis
Lessons Learned: 10 Common Mistakes in Data Journalism
GIJN asked speakers and attendees in the NICAR conference hallways for the data journalism gaps they see and for under-covered topic areas newsrooms can address.