
Умение пользоваться электронными таблицами – важный навык, помогающий находить потенциальные истории в больших объемах данных. Изображение: Shutterstock
Основы работы в Google Таблицах: Пошаговое руководство для журналистов
ЧИТАЙТЕ ЭТУ СТАТЬЮ НА ДРУГИХ ЯЗЫКАХ




Журналистам-расследователям часто приходится погружаться в огромные массивы данных, полученных от источников в виде утечки информации или в ответ на запрос о доступе к публичным данным. Умение пользоваться электронными таблицами — важный навык, помогающий находить потенциальные истории в больших объемах данных. К тому же он даёт двойное преимущество: облегчает очистку и визуализацию данных, и обеспечивает возможность представить информацию в удобной для читателя форме. Главное — критически осмыслить, как использовать имеющиеся данные для поиска историй в электронных таблицах.
В этом руководстве мы ссылаемся на Google Таблицы, но обратите внимание, что приведённые шаги и формулы можно применить в Microsoft Excel. Там есть незначительные отличия, например, в расположении кнопок в меню или в том, как они выглядят. Для упрощения мы не будем указывать каждый раз на эти отличия.
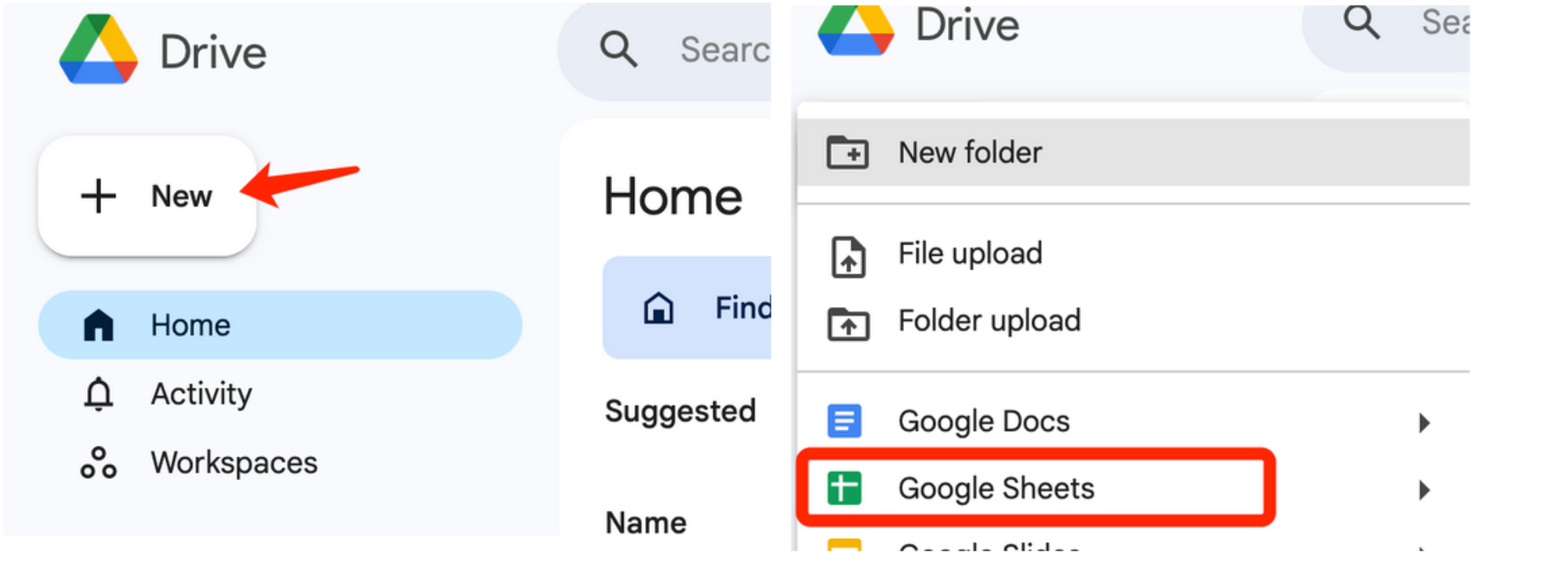
Для начала откройте Google Диск и создайте новую электронную таблицу с помощью Google Sheets. Для этого нажмите кнопку «Создать» в верхнем левом углу Диска и выберите Google Таблицы:
Когда документ откроется, вы увидите пустую электронную таблицу, состоящую из строк и столбцов. Здесь будут «жить» ваши данные.
Вот это строка.

А это столбец.

Когда вы начинаете использовать пустую электронную таблицу, рекомендуем в верхней строке всегда писать заголовки. Это названия ваших категорий данных, например, ИМЯ. Ниже вы увидите пример.
Введите следующие данные в поля в колонке A:
ИМЯ
Andy
John
Mary
Sally
Mark
В столбце B введите суммы зарплат, как показано ниже:
ЗАРПЛАТА
450000
380000
410000
290000
950000
Вводя числа, не используйте знаков препинания — это поможет избежать проблем с форматированием.
Всегда создавайте заголовки столбцов для обозначения данных — так их легче организовывать и сортировать. Дальше мы покажем, как сортировать и фильтровать данные с помощью заголовков.

Использование базовых формул
Каждая формула начинается со знака «=». Будьте внимательны, когда вводите формулу, поскольку Google будет пытаться автоматически подставить то, что, по его мнению, вы хотите написать, и может допустить ошибку. Всегда проверяйте свои формулы.
Чтобы увидеть общую сумму выплаченных зарплат, мы подытожим годовые зарплаты из столбика B для всех работников, упомянутых в столбце A. На рисунке ниже суммы выделены в полях от B2 до B6. В формуле это представлено как =SUM(B2:B6), таким образом Google видит начальную и конечную ячейку для этого набора данных.

Мы также можем рассчитать среднюю заработную плату работников, используя формулу =AVERAGE(B2:B6), как показано ниже.

В нашем случае средняя зарплата составляет 496 000. Но берегитесь аномальных значений! Обратите внимание, что Марк в ячейке A6 является аномальным значением — его зарплата значительно превышает зарплаты других — и поэтому средняя зарплата всех работников смещена в большую сторону. (Заметьте, что все остальные работники зарабатывают меньше среднего значения 496 000).
Журналисты часто используют средние показатели в своих материалах, но такой расчёт может значительно исказить данные, поскольку среднее арифметическое вычисляется путем простого суммирования всех чисел и деления на их количество.
Чтобы точнее показать реальную статистическую картину, часто лучше вычислить медиану, которая предполагает расчёт значения, которое будет ровно посередине ряда всех перечисленных чисел.

В этом случае медиана составляет 410000, что гораздо более реалистично отражает типичный уровень заработной платы работников этой компании. (Заметьте, что два работника получают больше, чем медиана, двое — меньше, а один — ровно столько же). Поэтому распознавание аномальных значений и понимание их влияния очень важно для точности журналистской работы.
Теперь мы создаём новую колонку С с новыми зарплатами, и хотим увидеть новую общую сумму. Вместо того чтобы писать формулу снова, мы можем просто щёлкнуть на B8 и увидеть наверху формулу, которая заполняет эту ячейку.

Мы можем скопировать ячейку B8 и вставить её содержимое в ячейку C8, чтобы рассчитать новую общую сумму зарплат, а Google Таблицы автоматически скорректируют формулу, чтобы использовать поля данных из нашего нового столбца C.

Однако будьте осторожны. Если вы допустили ошибку в первой формуле, копирование её в другие ячейки повторит ту же ошибку. Всегда проверяйте свои формулы, чтобы быть уверенными в правильности информации — так же, как вы проверяете любую информацию, предоставленную вам источником во время интервью.
Копирование формулы можно ускорить — щёлкнуть ячейку с формулой, навести курсор на правый нижний угол, где вы увидите синюю точку, и появится знак «+». Нажмите его и перетащите курсор вправо, чтобы скопировать формулу в соседнюю ячейку.

Если мы теперь создадим новый столбик с заголовком РАЗНИЦА в колонке D, то сможем быстро подсчитать, насколько изменились зарплаты, отняв старую зарплату от новой.
После того, как вы заполните первую строчку, Google Таблицы предложат выполнить такой же расчёт для других строк, поэтому можно нажать галочку, чтобы принять предложение или снова переместить курсор в правый нижний угол D2 и перетащить его вниз через другие строки к D6. Кроме того, можно дважды щелкнуть синюю точку в правом нижнем углу D2 и она автоматически заполнит формулу для всех строк под ней.

Чтобы вычислить разницу между двумя зарплатами в процентах, нужно от новой зарплаты отнять старую, а затем разделить результат на старую зарплату = (Новая – Старая) / Старая.
Запишем формулу так, как это делается в математике, используя круглые скобки (), чтобы указать Google Таблицам, какая операция будет первой, в нашем случае C2 – B2.

Но такие дробные значения сложно использовать в журналистских материалах и пояснить читателю

Чтобы это исправить, нажмите на верхнюю часть столбца E, чтобы выделить все ячейки в столбце, затем выберите поле «Формат» в верхнем меню страницы, выберите в меню «Числа» > «Процент» и нажмите на него, чтобы отформатировать весь столбец.


Сейчас мы создадим новый столбец F, чтобы вычислить процент от общей суммы. Для этого нам нужно разделить часть на целое, то есть C2 (новую зарплату Энди) на C8 (общую сумму новых зарплат).

Как упоминалось выше, если мы хотим выполнить те же вычисления для остальных строк с 3-й по 6-ую, мы перетаскиваем ячейку F2, чтобы применить формулу к остальной колонке F. Однако, когда мы это делаем, получаем ошибку или странные результаты.

Это происходит потому, что когда вы копируете формулу и применяете её к другим строкам, Google Таблицы будут в дальнейшем подставлять в формулу значения, которые находятся ячейкой ниже, используя соответствующие поля для выполнения новых вычислений. Это означает, что в ячейке F2 формула имеет вид C2/C8, в ячейке F3 – C3/C9, F4 – C4/C10, F5 – C5/C11 и F6 – C6/C12.
Можно избежать этой проблемы, используя инструмент привязки «$». Привязка — это команда, указывающая Google Таблицам не делать шаг к следующей ячейке, поскольку нам всегда нужно использовать только определённую ячейку для нашей формулы.
В этом случае ячейка C8 (TOTAL NEW SALARY — НОВАЯ З/П, ВСЕГО:) — это ячейка, на которую мы всегда будем делить новые зарплаты. Чтобы привязать C8 к нашей формуле, мы запишем её как C2/$C$8. В этой формуле вы видите два символа привязки, потому что мы говорим Google Таблицам не выходить из столбца C и не выходить из строки 8. Всегда ставьте символ привязки перед соответствующей строкой и столбцом, а не после.

После этого можно снова выбрать столбец F, перейти к верхнему меню и нажать «Числа» > «Процент», чтобы увидеть значения в процентах вместо сообщения об ошибке «#DIV/0!».
Создание диаграмм
Мы журналисты, потому нам хочется помочь людям понять данные с помощью визуальных средств. В нашем случае мы хотим сравнить старую и новую зарплату, поэтому нам нужно выбрать диапазон от A1 до C6.
Выбрав данные, нажмите «Вставка» в верхнем меню и выберите «Диаграмма».

Таблицы Google создадут для вас график, а если отвести курсор мыши в правую сторону экрана, то можно изменить его и/или его настройки с помощью инструмента «Редактор диаграмм».

Также можно создать круговую диаграмму с процентами от всей суммы, рассчитанными ранее в колонке F. Для этого нам понадобится колонка A с именами и колонка F с процентами. Поскольку эти два столбика не находятся рядом, мы не можем просто нажать на A1 и перетащить курсор. В этом случае мы нажимаем на A1, удерживаем кнопку мыши нажатой, перетаскиваем вниз к A6, а затем отпускаем, чтобы завершить выделение.
Затем перемещаем курсор на F1, нажимаем и удерживаем клавишу Command для Mac или Control для Windows, а затем перетаскиваем курсор вниз в F6. Это позволит выбрать те данные, которые нам нужны для нашей круговой диаграммы.

Снова выбираем верхнее меню «Вставка» > «Диаграмма», и Google Таблицы создадут круговую диаграмму.

После того, как вы настроили графику, можете сохранить её отдельно для своих публикаций. Нажмите на три вертикальные точки в правом верхнем углу диаграммы, перейдите в раздел «Скачать диаграмму» и выберите тип файла, который больше подходит для ваших целей.

Сортировка длинных списков данных
Что делать, если нам предоставили длинный список данных, и нужно попытаться найти в них какую-то историю? Сортировка — это один из лучших способов представить данные по-разному и понять, есть ли что-нибудь интересное в этих цифрах.
К примеру, в этой таблице давайте рассмотрим ожидаемую продолжительность жизни в разных странах. Сделайте копию документа, чтобы поэкспериментировать самостоятельно.
Открыв электронную таблицу, щёлкните столбец A и удерживайте кнопку мыши нажатой, а затем перетащите курсор справа на столбец C, чтобы выделить три столбца и все строки данных ниже. Затем в верхнем меню выберите «Данные» > «Сортировать диапазон» > «Расширенные настройки сортировки диапазонов».

Сначала обязательно поставьте галочку «Данные со строкой заголовка», чтобы Google Таблицы знали, что первая строка — это не сама строка данных, а заголовки/названия ваших столбцов.

Если вы выберете «Сортировать по: Male Life expectancy» (Ожидаемая продолжительность жизни мужчин) от А до Я, то увидите страны с ожидаемой продолжительностью жизни мужчин от самого низкого значения (А) до самого высокого (Я).


С другой стороны, если вы выберете вариант от Я до А, вам сначала покажут страны с наивысшим значением, в данном случае — Швейцарию.

Но, как вы можете заметить, для некоторых стран нет данных. Отсортировав сотни строк, можно быстро увидеть, в каких странах отсутствуют данные, и указать на это в своем материале, чтобы не ввести читателей в заблуждение.
Закрепление строк и столбцов
А теперь используем другой набор данных для наших заключительных советов. Сделайте копию этого документа о зарплате европейских футболистов.
Если его открыть и прокрутить, вы увидите, что заголовки верхних строк исчезают при прокручивании вниз — а это мешает, если нам нужно всегда видеть эту информацию. Чтобы это исправить, щелкните правой кнопкой мыши в строке 1 и внизу выберите «Показать другие действия со строкой» > «Закрепить до строки 1».

Если вы теперь прокрутите таблицу вниз, то увидите, что верхнюю строчку видно постоянно. Так же можно сделать и со столбиками, попробуйте щелкнуть правой кнопкой мыши на столбце A и закрепить его.
Если же передумаете, выполните те же шаги, и вы сможете нажать «Открепить строку», чтобы снять закрепление.
Использование фильтров
Если нам нужно увидеть только определённый набор данных, воспользуемся опцией фильтра.
Чтобы активировать фильтры для ваших данных, просто щёлкните где угодно на данных, а затем в верхнем меню выберите «Данные» > «Создать фильтр».

Теперь вы увидите, что на верхних полях заголовков строк рядом с названиями столбцов появились кнопки в виде перевёрнутых треугольников.

Кликните на перевёрнутый треугольник рядом с пунктом «Nation» в поле C1 и выберите «Сбросить», чтобы удалить все выбранные данные, затем выберите «de GER» и нажмите «ОК».

Теперь вы можете увидеть всех самых высокооплачиваемых немецких футболистов. Этот процесс можно повторить для нескольких стран.

Обратите внимание, что строки больше не отображаются по порядковому номеру, теперь они идут от 1 до 6, затем 13, 19, и до 97. Это происходит потому, что Google Таблицы скрывают данные, которые вы решили сейчас не просматривать, но не удаляют их. В этом случае нельзя использовать функцию =SUM внизу списка, как мы делали ранее [=SUM(G6:G97)], так как таблица сложит все данные от строки 1 до строки 97, включая скрытые строки не-германских футболистов.
Если же вам нужно использовать для расчетов именно эти конкретные данные, выберите их, скопируйте, а затем внизу слева в документе нажмите на знак плюс, чтобы создать новый лист.

Now paste the data, and you will see that the rows are numbered correctly once again. This is because now there is no more hidden data, and you can use the =SUM or other functions to calculate the data for your investigation.
Теперь вставьте в него данные, и вы увидите, что строки снова пронумерованы по порядку. Это потому, что в новой таблице нет скрытых данных, и вы можете использовать функцию =SUM или другие функции вычисления данных для вашего исследования.
Это руководство создано на основе советов и методов, изложенных на сессии Глобальной конференции журналистов-расследователей в Гётеборге, Швеция, в сентябре 2023 года. На сессии выступили профессор Школы журналистики Университета Миссури Марк Горвит; соучредитель Kaas & Mulvad Томми Каас; и старший редактор программы расследований NBC News Investigations Эндрю Лерен. Вы можете просмотреть запись сессии на нашем канале YouTube (на английском).
Материал отредактировал и сократил для большей наглядности бывший онлайн-продюсер GIJN Леонардо Перальта.
 Марк Горвит — профессор Школы журналистики Университета Миссури, где он преподаёт журналистские расследования, а также возглавляет программу «Освещение деятельности органов власти штата» и заведует кафедрой журналистских профессий. Ранее Горвит работал исполнительным директором организации Investigative Reporters and Editors (IRE) и Национального института компьютерной журналистики (NICAR), где проводил тренинги по журналистским расследованиям и журналистике данных для разных стран. До работы в IRE Горвит работал репортёром и редактором в течение 20 лет.
Марк Горвит — профессор Школы журналистики Университета Миссури, где он преподаёт журналистские расследования, а также возглавляет программу «Освещение деятельности органов власти штата» и заведует кафедрой журналистских профессий. Ранее Горвит работал исполнительным директором организации Investigative Reporters and Editors (IRE) и Национального института компьютерной журналистики (NICAR), где проводил тренинги по журналистским расследованиям и журналистике данных для разных стран. До работы в IRE Горвит работал репортёром и редактором в течение 20 лет.
 Томми Каас — редактор и соучредитель издания Kaas & Mulvad (основано в 2007 году), специализирующегося на поиске новостей и закономерностей в сложных данных и представлении результатов онлайн. У Томми — многолетний опыт работы в ряде датских СМИ; он преподаёт журналистику данных, в том числе на факультете журналистики в Университете Роскилле. Он также принимал участие в основании Foreningen for Computerstøttet Journalistik в 1997 и DICAR в 1999.
Томми Каас — редактор и соучредитель издания Kaas & Mulvad (основано в 2007 году), специализирующегося на поиске новостей и закономерностей в сложных данных и представлении результатов онлайн. У Томми — многолетний опыт работы в ряде датских СМИ; он преподаёт журналистику данных, в том числе на факультете журналистики в Университете Роскилле. Он также принимал участие в основании Foreningen for Computerstøttet Journalistik в 1997 и DICAR в 1999.
 Эндрю Лерен — старший редактор команды расследований NBC News. Он освещал реагирование на пандемию и распределение финансовой помощи, а также руководил работой над пятью расследованиями Международного консорциума журналистов-расследователей, включая Implant Files, China Files, и FinCEN Files. Его материал о болельщиках, травмированных отбитыми мячами, заставил Высшую бейсбольную лигу усилить защиту на всех своих стадионах. Ранее он почти 13 лет работал репортёром The New York Times, где публиковал американские и международные материалы и журналистские расследования. Он принимал участие в анализе утечки WikiLeaks — изучал дипломатические телеграммы, боевые донесения из Афганистана и Ирака, а также досье узников Гуантанамо. Эти материалы были опубликованы в книге-бестселлере «Открытые секреты» («Open Secrets»). Он участвовал в серии отмеченных Пулитцеровской премией расследований, проливших свет на некачественные китайские химикаты, которые используют в американской фармацевтике. Лерен получил образование в Университете Миссури и Лехайском университете.
Эндрю Лерен — старший редактор команды расследований NBC News. Он освещал реагирование на пандемию и распределение финансовой помощи, а также руководил работой над пятью расследованиями Международного консорциума журналистов-расследователей, включая Implant Files, China Files, и FinCEN Files. Его материал о болельщиках, травмированных отбитыми мячами, заставил Высшую бейсбольную лигу усилить защиту на всех своих стадионах. Ранее он почти 13 лет работал репортёром The New York Times, где публиковал американские и международные материалы и журналистские расследования. Он принимал участие в анализе утечки WikiLeaks — изучал дипломатические телеграммы, боевые донесения из Афганистана и Ирака, а также досье узников Гуантанамо. Эти материалы были опубликованы в книге-бестселлере «Открытые секреты» («Open Secrets»). Он участвовал в серии отмеченных Пулитцеровской премией расследований, проливших свет на некачественные китайские химикаты, которые используют в американской фармацевтике. Лерен получил образование в Университете Миссури и Лехайском университете.

Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Перепечатывайте наши статьи бесплатно по лицензии Creative Commons
Перепостить эту статью
Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Читать дальше

Журналистика данных Примеры из практики Советы и инструменты
10 типичных ошибок в журналистике данных
На конференции по дата-журналистике NICAR-2024 репортёр GIJN Рован Филп расспросил спикеров и участников о пробелах в журналистике данных, темах, которые часто остаются в тени, и навыках, которых не хватает редакциям.

Ресурс Советы
Работа с данными: Практические советы для небольшой редакции
Редакторка турецкой редакции GIJN Пинар Даг рассказывает о важности журналистики данных для небольших редакций и описывает шаги, которые помогут сформировать дата-команду при ограниченном бюджете и штате сотрудников.

Советы Журналистика данных
Веб-скрейпинг без программирования с помощью Data Miner: Пошаговая инструкция
Расширение для браузера Data Miner извлекает данные с веб-страниц и сохраняет их в формате Excel, CSV или JSON. Редакторка турецкой редакции GIJN Пинар Даг предлагает пошаговую инструкцию по использованию этого инструмента.

Журналистика данных
10 шагов, необходимых небольшим СМИ, чтобы начать копаться в журналистике данных
Журналистика данных становится всё важнее для всех типов редакций. Но как маленький ньюзрум начать заниматься этим? Вот 10 шагов, которые помогут вашей редакции.