
Information Laundromat – один из новейших инструментов анализа сайтов. Изображение: Shutterstock
Information Laundromat: Как работает инструмент для анализа контента и метаданных сайтов
ЧИТАЙТЕ ЭТУ СТАТЬЮ НА ДРУГИХ ЯЗЫКАХ




Я люблю исследовать веб-сайты — написал об этом главу для последнего издания «Руководства по верификации» и всегда ищу новые инструменты и методы для установления связей между сайтами, идентификации владельцев, анализа содержимого, инфраструктуры и поведения.
Information Laundromat — один из новейших бесплатных инструментов для анализа веб-сайтов, и, пожалуй, самый интересный из тех, с которыми мне приходилось сталкиваться. Альянс за безопасность демократии (Alliance for Securing Democracy — ASD) Фонда Джорджа Маршалла разработал этот инструмент для анализа контента и метаданных. ASD вместе с исследователями из Амстердамского университета и Института стратегического диалога использовали его при подготовке своего отчёта «Матрёшка российской пропаганды: как RT встраивается в цифровую информационную среду».
Information Laundromat может анализировать два элемента: контент, размещённый на сайте, и метаданные, используемые для его создания и запуска. Чтобы понять, как это работает, я протестировал инструмент и поговорил с его разработчиком Питером Бенцони.
Питер сказал мне, что Information Laundromat лучше всего применять для поиска зацепок: «Он не ставит цели автоматизировать ваше расследование». Information Laundromat имеет открытый исходный код и доступен на GitHub-аккаунте Альянса за безопасность демократии.
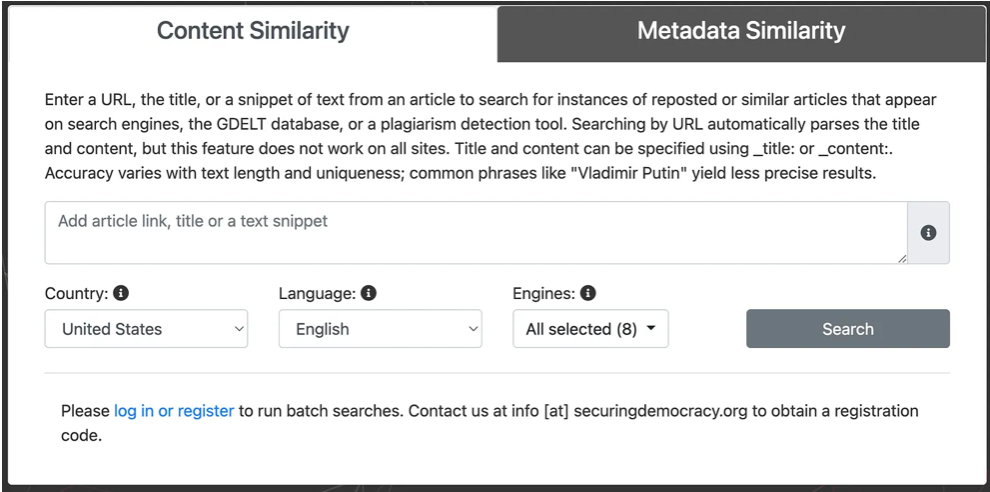
Анализ схожести контента
Изображение: снимок экрана, Digital Investigations
Как это работает
- Введите URL-адрес, заголовок или фрагмент текста, который необходимо проверить.
- Система использует поисковые системы, инструмент проверки на плагиат Copyscape и базу данных GDELT для анализа и оценки сходства этого контента с содержанием других сайтов.
- Страница результатов сортирует сайты по проценту содержимого, похожего на ваш первоисточник.
Я запустил выборочный поиск по URL-адресу, где содержалась почти точная копия новости, опубликованной в другом месте. Information Laundromat правильно определил первоисточник текста, указав на 97% сходства.
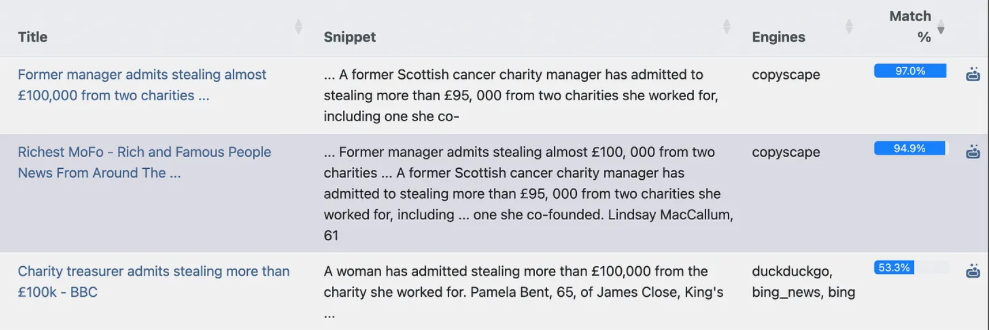
Information Laundromat правильно определил первоисточник текста, указав на 97% сходства. Изображение: снимок экрана, Digital Investigations
Поиск по сходству содержимого пытается найти похожие статьи или тексты в открытом доступе. Он не предоставляет доказательств происхождения этого текста, или каких-либо связей между двумя субъектами, опубликовавшими два похожих текста. Определение происхождения текста не входит в задачи этого инструмента.
Если при работе с инструментом вы получите много результатов, Питер рекомендует «скачать всё в Excel и просмотреть их самостоятельно с помощью сводной таблицы».
По словам Питера, самый большой интерес представляют сайты с рейтингом сходства 70% или выше. Инструмент также предоставляет функцию пакетной загрузки для зарегистрированных пользователей.
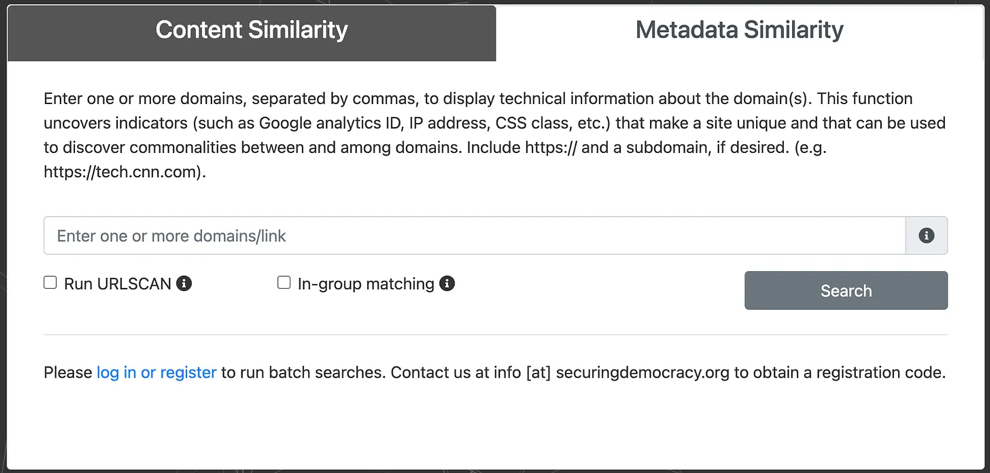
Анализ сходства метаданных
Изображение: снимок экрана, Digital Investigations
Как это работает
- Введите набор доменов, которые необходимо проанализировать на наличие общих связей.
- Инструмент сканирует каждый домен, включая его инфраструктуру, IP-адрес и исходный код, чтобы выделить уникальные показатели и определить, есть ли совпадения между доменами. Он обозначает прямые совпадения IP-адресов, а также показывает, размещены ли сайты в одном диапазоне IP-адресов (что является более слабой связью, но все же потенциально достойно внимания). Кроме поиска уникальных рекламных и аналитических кодов инструмент сканирует CSS-файл сайта на предмет сходства. Питер сказал, что «должно быть более 90% подобных классов CSS», чтобы инструмент обозначил его как достойный внимания. (Полный список индикаторов сайта можно просмотреть здесь).
- На странице метаданных результаты сортируют по двум разделам:
- первая таблица содержит список индикаторов, присутствующих на каждом сайте;
- вторая таблица определяет общие для всех сайтов индикаторы.
- Инструмент также сортирует результаты в каждой таблице в соответствии с относительной силой каждого индикатора. (Объясню подробнее в последней главе этой статьи).
«Идея заключалась в том, чтобы попытаться выявить какие-либо указания на родство сайтов и взаимосвязи между ними», — сказал мне Питер.
Если вы не знакомы с методом обнаружения связей между сайтами с помощью аналитики и рекламных кодов, вы можете прочитать это базовое руководство и мою статью (сначала прочтите руководство!).
Модуль метаданных Information Laundromat может быть полезным, если вы знакомы с инфраструктурой вебсайтов, например, с IP-адресами, и если вы понимаете, как связывать сайты между собой с помощью индикаторов. Если вы не понимаете относительно сильных и слабых сторон каждого индикатора и связи, тогда использование этого инструмента может быть рискованным. (Подробнее об этом ниже).
Питер сказал, что инструмент анализа метаданных является отличной отправной точкой для поиска связей между сайтами из определённого набора.
«Если у вас есть набор сайтов, и вы хотели бы получить представление о потенциальных повторах, то это хороший способ провести быстрый анализ, чтобы не запускать его вручную, применяя кучу других инструментов», — сказал он.
Я согласен, что это потенциально хорошая отправная точка, если у вас есть набор сайтов, которые, по вашему мнению, могут быть связаны между собой. Information Laundromat даст вам полезный обзор потенциальных связей. С этими результатами в руках вы можете погрузиться глубже, используя такие инструменты как DNSlytics, BuiltWith, SpyOnWeb и вашу любимую платформу пассивных DNS.
Хотя инструмент работает с группой доменов, можно запустить поиск метаданных и по одному URL-адресу. Это полезно, ведь система может извлекать, например, коды аналитики для удобного поиска в таких местах как DNSlytics. Вы также можете увидеть, имеют ли URL общие индикаторы с набором из примерно 10 000 доменов, хранящихся в базе данных Information Laundromat. Источники перечислены на странице об инструменте.
- База EUvsDisinfo.
- Исследования партнёрских и смежных организаций, например отчёт Института стратегического диалога о зеркальных сайтах RT.
- Известные государственные медиасайты.
- Списки ненадёжных источников, сайтов «розовой слизи» («инфопомойки») и фейковых местных новостей.
- Список фейковых новостных сайтов из Википедии и список новостных сайтов Wikidata.
Питер отметил, что инструмент не добавляет в базу данных домены, введенные пользователем. Поэтому если вы ищете набор доменов, которые считаете конфиденциальными, вы можете утешиться тем, что инструмент не добавит ваш сайт(ы) в базу Information Laundromat.
Рейтинг технических показателей сайта
Очень важно понимать относительные сильные и слабые стороны индикаторов сайта, определённых этим инструментом, в противном случае есть риск переоценить степень связи между сайтами. К счастью, документация Information Laundromat приводит полезную разбивку показателей.
К примеру, это слабая связь, если несколько сайтов используют систему управления контентом WordPress. Такую систему используют сотни миллионов сайтов, сама по себе она не является полезным сигналом для выявления связи между ними. Однако можно говорить о сильной связи между сайтами, если они используют одинаковый код Google AdSense.
В идеале следует определить несколько технических показателей, связывающих набор сайтов, и объединить их с другой информацией, чтобы по достоинству оценить степень связанности.
Чтобы облегчить анализ, Information Laundromat сортирует индикаторы по трём уровням. На странице результатов удобно ориентироваться по цветовой кодировке, она укажет на сильные, умеренные или слабые индикаторы. Всё равно вам придётся проводить собственный анализ, но это полезная отправная точка.
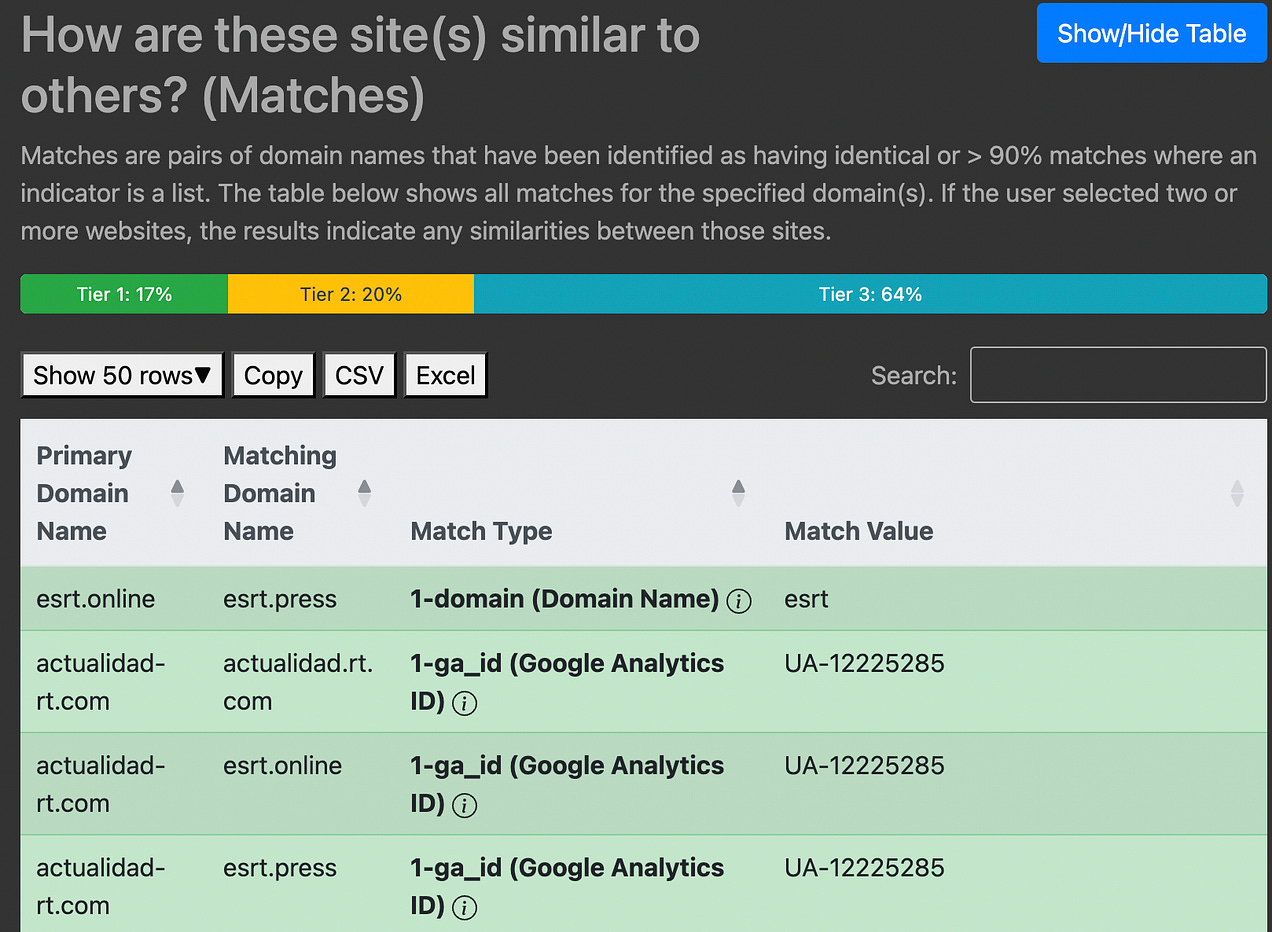
Пример поиска метаданных с использованием доменов, связанных с RT. Изображение: снимок экрана, Digital Investigations.
Вот три уровня индикаторов согласно документации Information Laundromat
- Уровень 1: Эти данные «как правило, уникальны или в значительной степени указывают на происхождение веб-сайта» и содержат «уникальные идентификаторы для верификации и веб-сервисов, таких как Google, Яндекс и т.д., а также метаданные сайта, такие как информация WHOIS и сертификаты».
- Уровень 2: Такие индикаторы «предполагают умеренный уровень уверенности в происхождении вебсайта». Они «предоставляют ценный контекст» и включают «IP-адреса в одной подсети, совпадающие метатеги и общие черты в стандартных и специальных заголовках ответов».
- Уровень 3: На эти индикаторы следует ориентироваться в сочетании с индикаторами более высокого уровня. Уровень 3 включает «общие классы CSS, UUID и систем управления контентом».
Эту статью Крейг Сильверман сначала опубликовал на своём сайте «Цифровые расследования», а мы перепечатали и перевели её с его разрешения.
 Крэйг Сильверман — репортёр издания ProPublica, занимающийся вопросами голосования, цифровых платформ, дезинформации и онлайн-манипуляций. Ранее он работал медиаредактором в BuzzFeed News, где одним из первых начал освещать проблемы цифровой дезинформации.
Крэйг Сильверман — репортёр издания ProPublica, занимающийся вопросами голосования, цифровых платформ, дезинформации и онлайн-манипуляций. Ранее он работал медиаредактором в BuzzFeed News, где одним из первых начал освещать проблемы цифровой дезинформации.

Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Перепечатывайте наши статьи бесплатно по лицензии Creative Commons
Перепостить эту статью
Это произведение защищено лицензией Международная лицензия Creative Commons Attribution-NoDerivatives 4.0
Читать дальше

Советы и инструменты
ChatGPT как инструмент для быстрого поиска: Советы расследователям
Как использовать ChatGPT для поиска контактных данных новых источников и беглого анализа документов, чтобы ускорить начало расследования. Этими и другими советами поделился журналист-расследователь KUSA-TV Джереми Джоджола на конференции IRE24.

Примеры из практики Советы и инструменты
Отслеживание олигархов через границы
Журналисты из авторитарных стран рассказали, как собирают досье на олигархов, находят информацию в корпоративных базах данных и санкционных списках, создают собственные наборы данных и сопоставляют утечки информации, таможенные записи и местные реестры — и всё это, преодолевая юридические риски и угрозы безопасности, связанные с расследованием деятельности влиятельных лиц.

GIJC25 Поиск по открытым источникам Примеры из практики Советы и инструменты
Как украинские журналисты расследуют военные преступления на оккупированных территориях
Не имея доступа к оккупированным территориям, украинские редакции вынуждены изобретать новые нестандартные тактики для репортажей о войне: OSINT, спутниковые снимки, перехваченные разговоры, данные украинских правоохранителей, свидетельства очевидцев и работу на местах событий после деоккупации, чтобы документировать военные преступления.

Журналистика данных Награды
Приём заявок на премию Sigma Awards продлён до 18 января
Приглашаем журналистов из всех регионов мира выбрать свои лучшие работы в области данных и представить их на рассмотрение судей до 18 января.