
Illustration: Louiza Karageorgiou for GIJN




Editor’s Note: This guide is a collaboration between the Pulitzer Center’s AI Accountability team and GIJN. Karen Hao, Laís Martins, and Pablo Jiménez Arandia co-developed some of the materials described in this article.
Artificial Intelligence (AI) has become a major force in many areas of society throughout the world. The technology plays an outsized role in many economies and has implications for knowledge workers globally. The most powerful players in this arena are a handful of mostly US- Europe-, or China-based entities, many of them private Big Tech companies that have garnered billions in investments and are primed to set the tone on how this technology will be developed and deployed around the world.
But from its supply chain to its applications, AI has also stirred a lot of controversy. The data centers needed to develop AI are consuming water and energy at extraordinary levels. The workers who are labeling the data that AI needs are struggling with low wages and mental health issues. The AI technologies themselves have proven to be biased and to hallucinate when used.
The field of AI is rife with stories for investigative reporters to tap. This guide is meant to help reporters understand some of the nitty-gritty of the technology underlying AI and to give them a framework through which they can examine it.
What Is AI?
Many people were first introduced to the idea of artificial intelligence through ChatGPT. For that reason, people think of ChatGPT as AI and of AI as just ChatGPT.
But the truth is far more complex than that. Artificial intelligence describes the process of using machines to mimic human decision-making and can better be thought of as a “grab bag” of a term that encompasses a large number of technologies.
Scientists and researchers coined the term in the 1950s and since then have found many, differing ways to recreate human intelligence through technology.
One of the most popular and prolific AI methods these days is machine learning and all the forms it takes, including its subsets deep learning and generative AI.
Machine learning is the process of analyzing data to find patterns that allow us to make predictions or decisions based on those findings. These analyses use various mathematical methods, from simple statistics to complex neural networks, often depending on the amount of data that’s being processed. The result of this training is a computer program, or AI model, that can take in new data and make predictions or generate new information based on this old data. In many ways, you can imagine machine learning outputs as a remix of old data. In one use case, simple machine learning models may be used by government agencies that are assigning risk scores to potential welfare recipients or to people who are applying for housing benefits.
Deep Learning is a subset of machine learning that requires a large amount of data entries, often in the millions, and uses complex analytical methods, like neural networks, which are mathematical methods that mimic the structure of the brain and consist of interconnected nodes, to make sense of the data. (You can learn more about neural networks here.) This kind of machine learning is often used by Big Tech companies that may use it for predicting terms in search engines or recommendation systems for streaming services.
Then there is generative AI which is a subset of machine learning that requires even more data and, during its training phase, even more energy and intricate mathematical methods to make its models. Generative AI differs from many other machine learning methods in that it does not just produce a recommendation for a timeline or a predictive score, but also creates new content in the form of text or imagery. That’s the technology we now encounter through Large Language Models (LLMs) in the form of chatbots like ChatGPT or Gemini, as well as through apps that create images from text prompts like Midjourney.
The diagram below lays out all versions of machine learning.
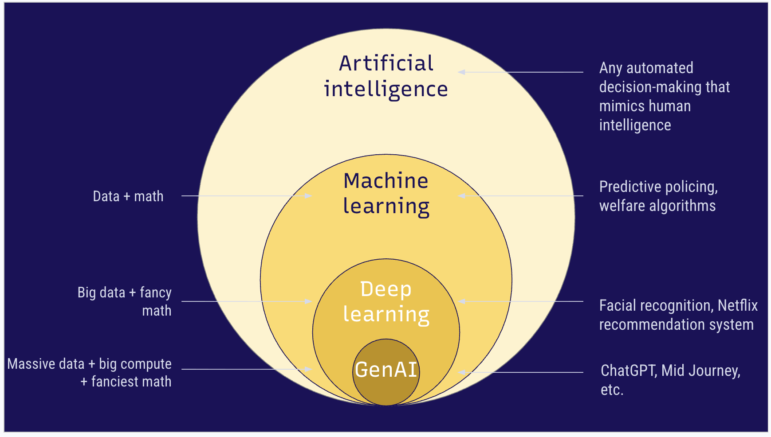
Graphical representation of artificial intelligence and its subsets, including machine learning, deep learning and generative AI. Image: Courtesy of the Pulitzer Center.
Knowing how machine learning works in broad strokes can help journalists find ways to speak about it, ask informed questions about the technology, and find ways to better tap into the various stages of AI development for their reporting.
Framework for AI Accountability Stories
When we first began developing the AI Spotlight Series with Karen Hao, we kept returning to a simple question: What do we wish we had known when we first started reporting on AI? The answer was a framework for how to identify and frame AI stories.
AI encompasses a broad set of technologies and issues, and it can be overwhelming to figure out where to start. Our framework revolves around the four stages of modern AI development. At the foundation are the inputs, the data and compute that make today’s systems possible. From there, models are built and trained, shaped by data and design choices. Finally, these models are applied in the real world. Each of these development stages comes with its own set of related issues, actors involved, and impacted people or structures.
We’ll go through each of these stages, discussing key concepts and archetypical stories.
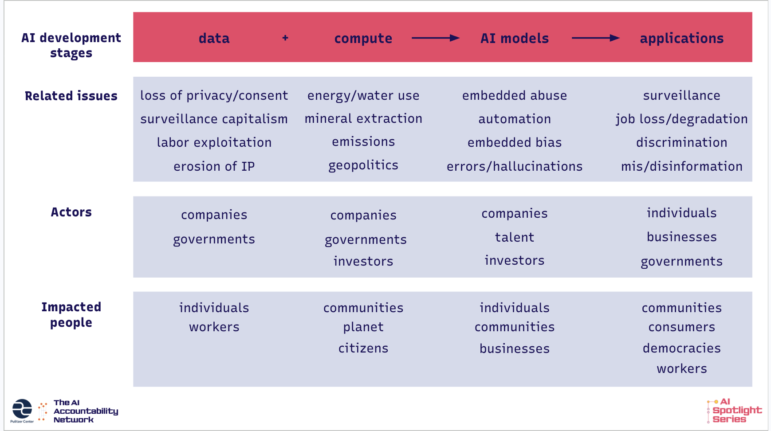
Screenshot: A graphical representation of the AI accountability reporting framework, Courtesy of the Pulitzer Center
Investigating the Data Used
The simplest AI models may use training sets containing a few hundred data points, whereas the most complex models, like LLMs, are often trained on vast swathes of the internet. The range of material in training data can be equally broad. It can take the form of structured, tabular data neatly organized in rows and columns, or unstructured text scraped from social media platforms, news sites, and online forums. Increasingly, it also includes images and videos.
Most reporting that centers on the data development stage tends to focus on more advanced systems that are trained on massive datasets at an industrial scale. A significant number of these stories focus on issues of privacy and intellectual property. In particular, how copyrighted material or personal data end up in training pipelines for AI models. This Atlantic story, for example, looks at how Meta allegedly used thousands of pirated books in order to train its generative AI model Llama; A spokesperson for Meta declined to comment to The Atlantic journalists, citing the ongoing litigation against the company. Another story, from The New York Times, found that car insurance companies are purchasing personal driving data from seemingly innocuous apps to risk-score drivers.
But looking at data also involves looking at the human labor that makes training datasets usable in the first place. While companies tend to present their data collection and training as a highly automatic process, the reality is that training sets are often cleaned and categorized by a large underclass of data labelers, predominantly located in the Global South and operating through outsourcing firms and digital labor platforms. These workers label pictures of cats and dogs that are fed into image classifiers, draw boxes around objects in dashcam footage used to train self-driving cars, or identify hate speech and violent content to prevent LLMs from reproducing it.
Reporting from across the world has shown that data laborers are exploited, underpaid, and sometimes forced to engage with traumatic content. This Bureau of Investigative Journalism investigation shows how low-paid gig workers around the world are unknowingly helping train facial recognition systems that are used by the Russian government. Another story from Africa Uncensored examined the growing ‘AI tutor’ industry, wherein highly educated workers train LLM chatbots to produce higher-quality responses.
Investigating the Compute
Once training datasets are collected and cleaned, companies use them to train AI models. While simple AI models can be trained in a fraction of a second on a consumer laptop, more complex models, like OpenAI’s ChatGPT, require massive amounts of computing power. This computing power, often referred to as “compute,” is typically provided by specialized computer chips housed in enormous data centers.
Reporting on the “compute” development stage tends to focus on the environmental, social, and economic impact of the sprawling and rapidly expanding physical infrastructure powering modern AI development. When we first developed the AI Spotlight Series, in 2024, data centers were still a relatively nascent reporting topic. Since then, there has been a wealth of reporting from Latin America, Asia, Africa, and the United States demonstrating the enormous amounts of energy and water data centers consume, as well as corporate or governmental efforts to conceal these numbers. In Brazil, for example, Pulitzer fellow Laís Martins found that a TikTok data center was slated to use as much electricity as 2.2 million people; the company didn’t respond to the reporter.
Reporting on data centers extends beyond environmental impact. It also examines how data centers reshape local communities, the frequently unfulfilled promises of economic growth, and the intense lobbying efforts at both the local and national level to attract and build them. Laís developed an adjusted version of our framework just focused on data center reporting that you can find below.
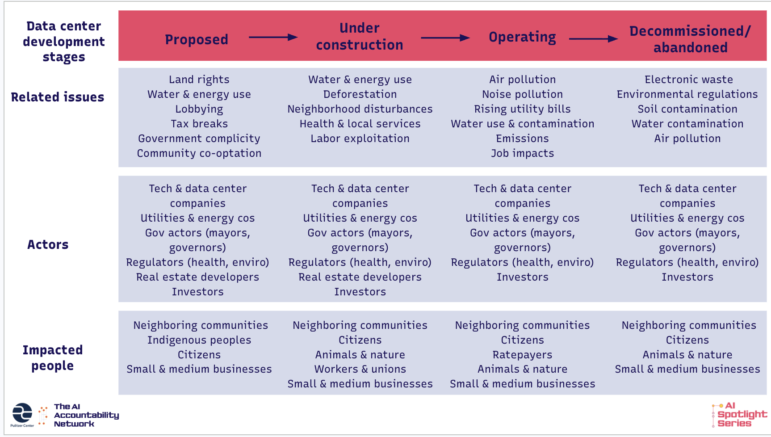
Image: Courtesy of the Pulitzer Center
Investigating the Models
The combination of training data and compute produces an AI model, a technical artifact that makes predictions, classifications, or, in the case of generative AI, creates new content altogether. Like data and compute, AI models vary in complexity and scale, ranging from relatively simple machine learning systems used to calculate healthcare premiums to sophisticated deep learning systems capable of generating realistic images.
Stories that focus on AI models tend to focus on issues around bias, errors, or the abject effects of automation on communities and institutions.
These investigations may scrutinize design choices when they are accessible, such as the training data or parameters used by a model. This investigation from El Confidencial, for example, obtained the formula for an AI system used in the Catalan prison system to predict who will commit a future crime. According to the journalists, the model systematically assigned higher risk scores to certain groups based on discriminatory or irrelevant factors.
When such information is unavailable, you can analyze the model’s outputs instead. A story from Rest of World systematically analyzed 3,000 images produced by MidJourney AI, a popular image generator tool, and found that the system reproduces crude stereotypes about various cultures. According to the journalists, the company didn’t respond to their requests for comment. Another investigation, from the Philippine Center for Investigative Journalism, reverse-engineered Grab’s algorithmic output, a popular ride-hailing app, by collecting thousands of ride quotes. It found that Grab was always charging consumers surge fees that are supposed to only be present during heavy traffic hours. In a written reply to PCIJ, Grab’s Philippine operations said it had “fully cooperated with the [Land Transportation Franchising and Regulatory Board]’s inquiry” by participating in the hearings.
Investigating the Applications
Last but not least, it’s important for journalists to look into how artificial intelligence is deployed in the real world. When AI technology does not work as intended or malfunctions, many people who are subject to decisions made by automated systems like algorithms or generative AI apps may experience harm.
In a story for the Guardian, reporter Johana Bhuiyan showed how the US government’s overreliance on AI translation apps left one asylum seeker stranded in an ICE detention center for six months. The app, which performed poorly in low-resourced languages, was mistranslating him and he was unable to meaningfully communicate with anyone. The DHS didn’t respond to the Guardian reporter.
Hera Rizwan’s story about the use of facial recognition by the Indian government found that the app that civil servants were using to give out emergency food rations failed to recognize some pregnant women or those who were nursing because their faces looked different than the years-old images stored in government databases. The Ministry of Women and Child Development did not respond to Rizwan’s questions.
AI Accountability Reporting Is for Everyone
As the examples above show, our accountability framework can help journalists report on AI with various levels of technical effort and resources. Stories can be on the shorter side or the longer side and more human-driven or more technically executed. And we hope that these approaches and examples help other journalists find their own local approach to AI accountability reporting.
Resources
- Algorithmic Literacy for Journalists: a resource with explainers and other resources for journalists.
- AI Spotlight Series Open-Sourced Curriculum: offers video tutorials, frameworks, and slide decks from the Pulitzer Center’s initiative to educate journalists from around the world on AI.
- Reporter’s Guide to Detecting AI-Generated Content
- Guide to Investigating Social Media Algorithms
Research
- Algorithmic Justice League: an organization that documents and examines algorithmic harm.
- AI Now Institute: an independent institute that publishes research about AI and algorithmic accountability.
- Center for Democracy and Technology: a nonprofit that puts out reports around civil liberties in the digital age.
- Data and Society: a research nonprofit focused on technology, data, and policies.
- Algorithm Watch: a nonprofit group based in Zurich and Berlin.
- Privacy International: a nonprofit group based in London.
- Derechos Digitales” a nonprofit digital rights organization focusing on Latin America.
- African Digital Rights Network: a pan-African digital rights organization.
 Gabriel Geiger is an Athens, Greece-based investigative journalist specializing in surveillance and algorithmic accountability reporting. He is currently an investigative journalist at Lighthouse Reports, a nonprofit newsroom organization based in the Netherlands. His work has appeared in WIRED, Le Monde, Der Spiegel, and the Guardian, among others.
Gabriel Geiger is an Athens, Greece-based investigative journalist specializing in surveillance and algorithmic accountability reporting. He is currently an investigative journalist at Lighthouse Reports, a nonprofit newsroom organization based in the Netherlands. His work has appeared in WIRED, Le Monde, Der Spiegel, and the Guardian, among others.
 Lam Thuy Vo is a journalist who marries data analysis with on-the-ground reporting to examine how systems and policies affect individuals. She is currently an investigative reporter working with Documented, an independent, nonprofit newsroom dedicated to reporting with and for immigrant communities, and an associate professor of data journalism at the Craig Newmark Graduate School of Journalism. Previously, she was a journalist at The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America, and NPR’s Planet Money.
Lam Thuy Vo is a journalist who marries data analysis with on-the-ground reporting to examine how systems and policies affect individuals. She is currently an investigative reporter working with Documented, an independent, nonprofit newsroom dedicated to reporting with and for immigrant communities, and an associate professor of data journalism at the Craig Newmark Graduate School of Journalism. Previously, she was a journalist at The Markup, BuzzFeed News, The Wall Street Journal, Al Jazeera America, and NPR’s Planet Money.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Republish our articles for free, online or in print, under a Creative Commons license.
Republish this article
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
Read Next

GIJC25 News & Analysis
Tips to Investigate AI Labor Abuses in the Global South
Workers in East Africa and South Asia are now paid low wages to perform behind-the-scenes data tasks are used to power AI-driven facial recognition systems around the world.

GIJN Impact
How Digital Threats Training Has Powered Innovative Cyber Investigations Around the World
Alumni of GIJN’s four Digital Threats training courses have produced a number of exposés on online scams and political disinformation, from India to Kenya to the Philippines.

How They Did It
Analyzing Job Posting Data to Investigate the African Labor Behind AGI Hype
In the AI economy, hundreds of thousands of digital workers — or “gig workers” — from around the world are tasked with refining the answers of models like ChatGPT.

GIJN Co-Hosts International Journalists at IRE26 Luncheon
GIJN co-hosted journalists from nearly two-dozen countries and territories at an International Luncheon at the 2026 IRE Conference outside Washington, DC.